




IT之家 2 月 21 日消息,清华大学人工智能产业研究院(AIR)和北京水木分子生物科技有限公司(简称:水木分子)昨日宣布推出升级版的生物医药多模态开源基础大模型 BioMedGPT-R1。
此前,在 2023 年,双方合作发布了开源可商用、生物医药多模态百亿参数开源基础大模型 BioMedGPT,水木分子发布了自研千亿参数多模态生物医药专业大模型 ChatDDFM 和新一代 AI 驱动药物发现工具 ChatDD。这次 DeepSeek 版 ChatDD-R1 基座模型也已同步上线 ChatDD,用于生物医药企业的药物研发。
BioMedGPT 是清华大学智能产业研究院(AIR)携手水木分子开源的全球首个可商用多模态生物医药百亿参数大模型,该模型在生物医药专业领域问答能力号称“比肩人类专家水平”,发布时在自然语言、分子、蛋白质跨模态问答任务上达到 SOTA。
在 BioMedGPT 的基础上,清华大学 AIR 与水木分子推出了 BioMedGPT-R1,用 DeepSeek R1 蒸馏版本模型更新了 BioMedGPT 中现采用的文本基座模型,从而引入了更优的文本推理能力。
通过跨模态特征对齐,BioMedGPT-R1 实现了生物模态与自然语言文本模态在同一个特征空间的统一融合,探索了生物多模态场景下的模型深度推理能力。
通过训练对齐翻译层(Translator),BioMedGPT-R1 将生物模态编码器(Molecule Encoder 与 Protein Encoder)输出映射到自然语言表征空间,从而在 DeepSeek R1 基础上增加了生物模态数据的理解能力。
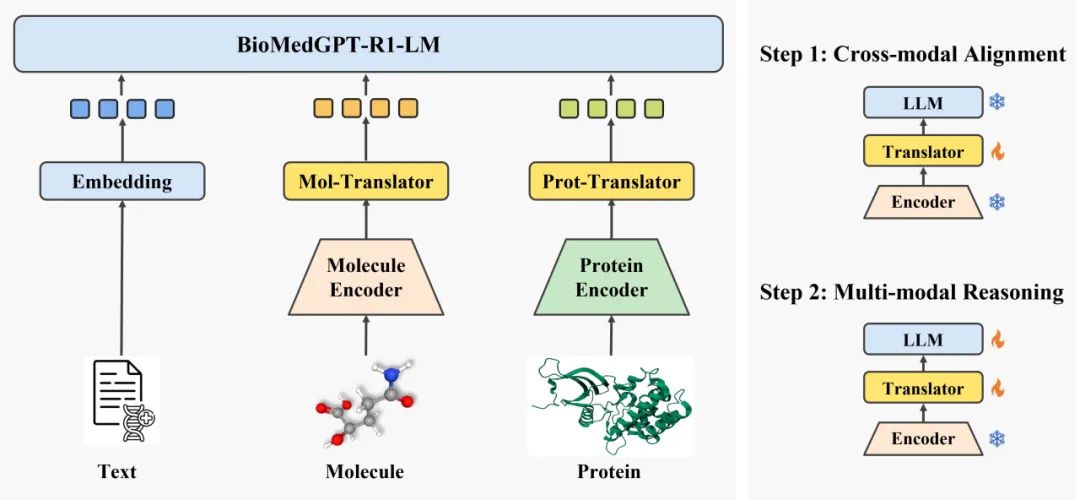
 BioMedGPT-R1 模型框架和主要训练步骤
BioMedGPT-R1 模型框架和主要训练步骤BioMedGPT-R1 的训练分为两个主要步骤:
首先,仅训练对齐翻译层 Translator,使其能将编码后的生物模态表征映射到语义表征空间;
然后,同时微调对齐翻译层 Translator 和基座大语言模型,激发其在下游任务上的多模态深度推理能力。
清华大学 AIR 和水木分子研究团队表示,将长期持续维护 OpenBioMed 开源平台,团队现阶段探索方向是如何在强推理语言模型的基础上更好地适应性地实现跨模态对齐,团队正在以 BioMedGPT-R1 为基础进行系统性研究与综合评估,目前已经观察到其在化学分子理解任务上的性能提升,如在 CheBI-20 化学分子描述任务上相比上一版本效果提升超 15%,后续也将依托 OpenBioMed 平台开源 BioMedGPT-R1 模型和生物医药研发 Agent 系统框架。




“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











