


IT之家 6 月 3 日消息,科技媒体 marktechpost 昨日(6 月 2 日)发布博文,报道称英伟达联合麻省理工学院(MIT)、香港大学,合作推出 Fast-dLLM 框架,大幅提升扩散模型(Diffusion-based LLMs)的推理速度。
扩散模型被认为是传统自回归模型(Autoregressive Models)的有力竞争者,采用双向注意力机制(Bidirectional Attention Mechanisms),理论上能通过同步生成多个词元(Multi-token Generation)加速解码过程。
不过在实际应用中,扩散模型的推理速度往往无法媲美自回归模型,每次生成步骤都需要重复计算全部注意力状态,导致计算成本高昂。此外,多词元同步解码时,词元间的依赖关系易被破坏,生成质量下降,让其难以满足实际需求。
IT之家援引博文介绍,英伟达组建的联合团队为解决上述瓶颈,研发了 Fast-dLLM 框架。该框架引入两大创新:块状近似 KV 缓存机制和置信度感知并行解码策略。
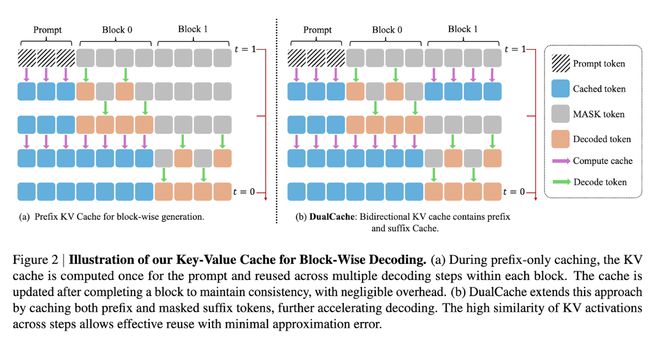
KV 缓存通过将序列划分为块(Blocks),预计算并存储其他块的激活值(KV Activations),在后续解码中重复利用,显著减少计算冗余。其 DualCache 版本进一步缓存前后缀词元(Prefix and Suffix Tokens),利用相邻推理步骤的高相似性提升效率。
而置信度解码则根据设定的阈值(Confidence Threshold),选择性解码高置信度的词元,避免同步采样带来的依赖冲突,确保生成质量。
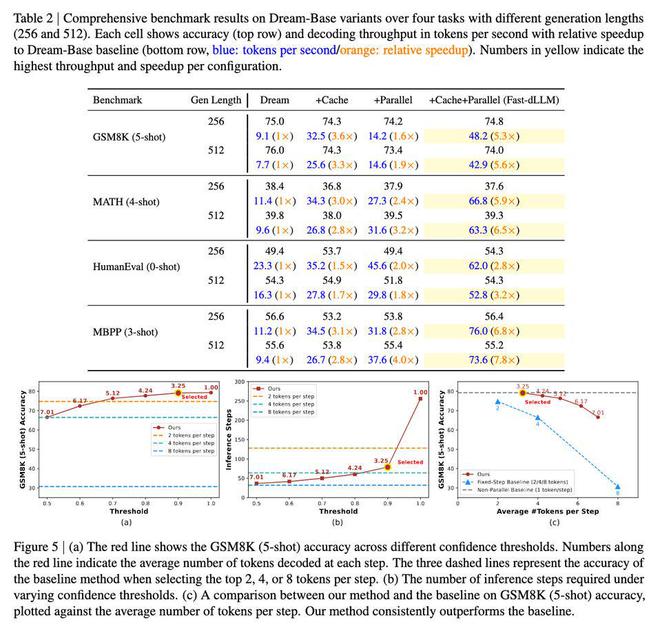
Fast-dLLM 在多项基准测试中展现了惊人表现。在 GSM8K 数据集上,生成长度为 1024 词元时,其 8-shot 配置下实现了 27.6 倍加速,准确率达 76.0%;在 MATH 基准测试中,加速倍数为 6.5 倍,准确率约为 39.3%;在 HumanEval 和 MBPP 测试中,分别实现了 3.2 倍和 7.8 倍加速,准确率维持在 54.3% 和基线水平附近。
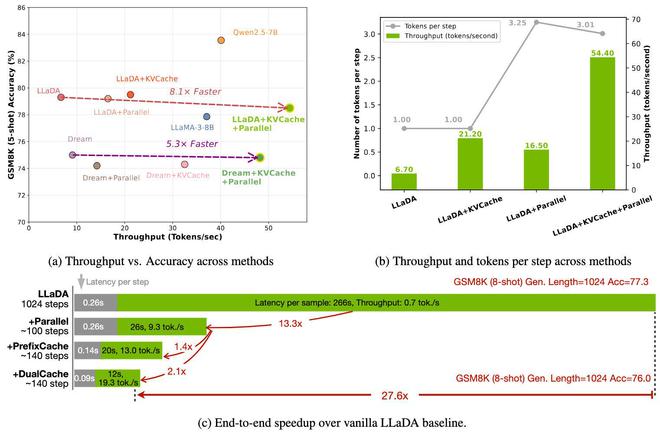
整体来看,Fast-dLLM 在加速的同时,准确率仅下降 1-2 个百分点,证明其有效平衡速度与质量。这项研究通过解决推理效率和解码质量问题,让扩散模型在实际语言生成任务中具备了与自回归模型竞争的实力,为未来广泛应用奠定了基础。
IT之家附上参考地址


VIP课程推荐
APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




