新智元报道
编辑:KingHZ
【新智元导读】LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。
全新检索模式:在无限长token下,大语言模型自身或能检索信息!
受大语言模型(LLM)上下文窗口大小的限制,处理输入token数超过上限的各种任务颇具挑战性,无论是简单的直接检索任务,还是复杂的多跳推理任务。
尽管新提出的各种方法用来增强大语言模型的长上下文处理能力,但这些方法痛点突出:
要么会产生高昂的训练后成本,
要么需要额外的工具模块(如检索增强生成RAG),
要么在实际任务中显示出改进,并不明显。
研究团队观察了各层注意力分布与生成答案之间的相关性,通过实验证实了注意力分配与检索增强能力是一致的。
基于上述见解,研究团队提出了一种全新的方法InfiniRetri,该方法利用大语言模型自身的注意力信息,实现对任意长度输入的精确检索。
实验表明,在100万个token的「大海捞针」(Needle-In-a-Haystack,NIH)测试中,InfiniRetri将5亿参数的模型从44.6%提升到了100%的准确率。
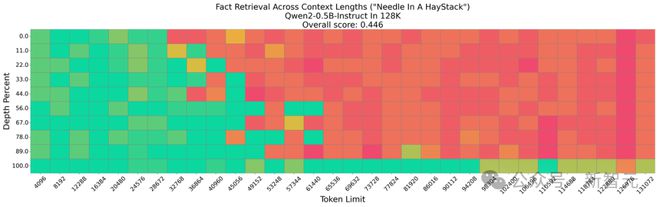
没有InfiniRetri的NIH测试只有44.6%的准确率
要知道GPT-4在NIH测试中都做不到100%准确率。

InfiniRetri一举超过了其他方法或更大的模型,创造了当前最佳(SOTA)结果。
值得注意的是,某7B模型在HotpotQA任务上的得分,超越了其他同等参数规模的模型。
类似地,Mistral-7B-Instruct v0.2作为擅长短文本推理的模型,在长文本任务中的表现也得到了显著提升。
此外,新方法在实际基准测试中也取得了显著的性能提升,最大提升幅度达到288%。
另外,无需额外训练,InfiniRetri就可应用于任何基于Transformer的大语言模型,并且能大幅降低长文本推理延迟和计算开销。

论文链接:https://arxiv.org/abs/2502.12962
项目地址:https://github.com/CapitalCode2020/InfiniRetri2
文章主要贡献如下:
鞭辟入里,灵魂三问
近年来,许多主流的LLM都在致力于扩展上下文窗口的规模。
例如,GPT-4、Llama3和DeepSeekV3支持最长128K的上下文长度,Claude-3可达200K,而Gemini-Pro-1.5和Qwen2.5-1M甚至支持1M的上下文长度。
然而,实际效果并未完全达到这些模型所宣称的长度。
LLM在处理超长上下文方面仍然面临重大挑战。
那自然考虑:是否能不断延长上下文窗口?
这是第一个问题,答案是不能,有3大原因:
接下来,进一步考虑第二个问题:要打破处理长上下文时不同窗口之间的信息壁垒,是否存在一种低成本的方法?
事实上,业界已经通过检索增强生成(Retrieval-Augmented Generation,RAG)提供了答案。
RAG由两大核心组件组成:检索模块和生成模块。其中,检索模块依赖外部嵌入模型,根据输入查询从长文本中检索相关内容。
然而,RAG系统普遍难以建立检索信息之间的关联。
相比之下,在推理过程中,LLM的注意力机制,能够高效地建立不同信息片段之间的联系。
由此引出了第三个问题:为何不直接利用LLM自身的检索能力,来处理长文本上下文?
为了让LLM以低成本的方式压缩并存储过去的键(key)和值(value),研究团队认为,只有打破不同上下文窗口之间的信息壁垒,LLM才能真正提升其处理长文本的能力。
此外,通过观察LLM在推理过程中回答问题时的注意力分配模式,研究团队提出:这种注意力分配模式与检索增强能力(RAG)高度契合。
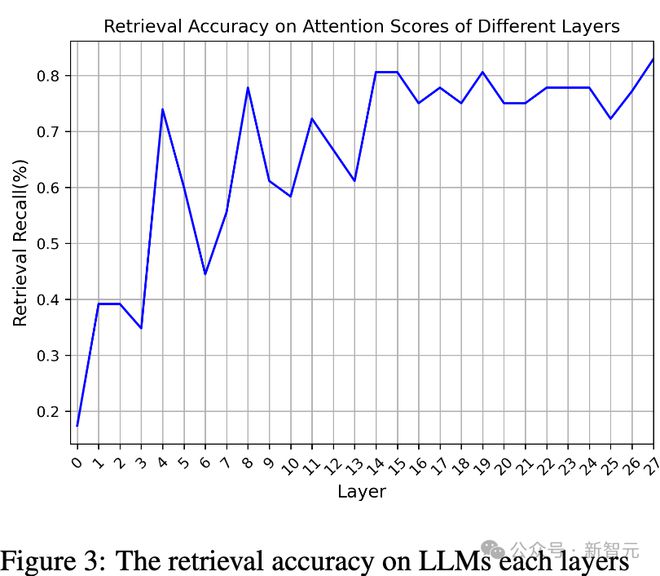
研究团队测试了基于所有层的注意力分布来检索答案的准确性。
正如下图3所示,越接近输出层,这种模式的增强效果就越明显。
此外,在第14层和第15层,检索准确率达到一个局部峰值。
因此,InfiniRetri引入了全新的策略,利用LLM自身的注意力信息,而非依赖外部嵌入模型,去提升其长文本处理能力。
无需对基于Transformer的LLM进行额外训练,InfiniRetri可以开箱即用。得益于此,研究团队在多个模型上进行了全面的对比实验。
在跨上下文长度的事实检索任务「大海捞针」(Needle In A Haystack,NIH)中,InfiniRetri仅使用5亿个额外参数,就将模型的上下文长度从原始的32K扩展至100万个token(如图1所示)。
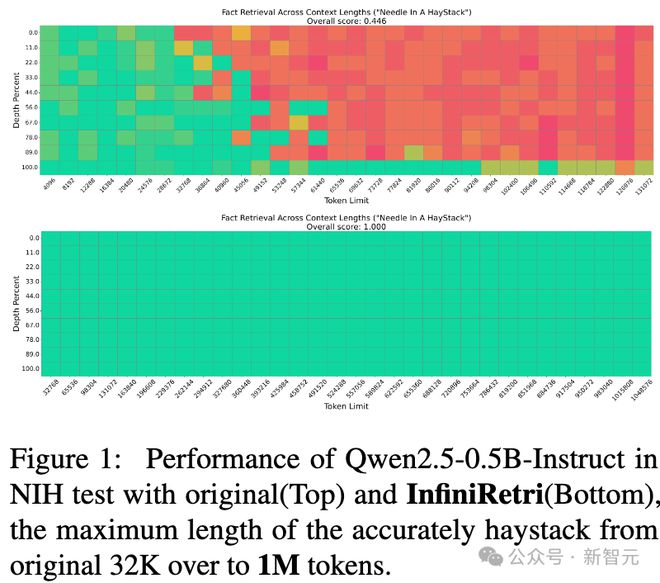
原始方法(上)与InfiniRetri方法(下)对比,准确检索的最大文本长度从原始32K提升至超过1M tokens。
更值得注意的是,InfiniRetri在NIH任务上实现了无限长度范围内的精准检索,不仅超越了当前主流方法,还有效解决了NIH任务的挑战。
此外,在LongBench提供的9个真实数据集上,InfiniRetri在基于KV Cache甚至Full KV的主流方法中均取得了超越性的表现,尤其是在多文档问答(Multi-Document QA)任务(如HotpotQA、2WikiMQA和Musique)中,Qwen2-7B-Instruct采用InfiniRetri后,平均性能提升高达369.6%。
InfiniRetri方法:带着问题阅读
那么,如何应用这一模式来处理超出上下文窗口的长文本,并真正提升LLM的长文本处理能力呢?
在本节中,将InfiniRetri方法拆分为三个小节,分别介绍该模式的应用方式,以提升LLM的长文本处理能力。
如图4所示,该方法的完整工作流程包括五个主要步骤,详细介绍这些步骤:
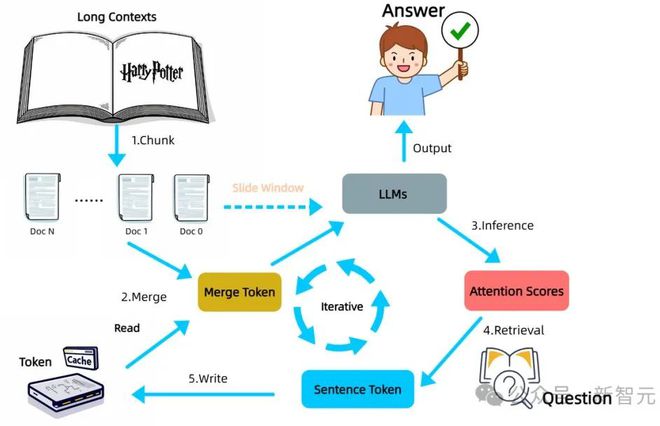 图4:InfiniRetri方法在增强LLM长上下文处理能力中的完整工作流程
图4:InfiniRetri方法在增强LLM长上下文处理能力中的完整工作流程文本分割
新方法受到人类阅读书籍过程的启发,专门针对LLM在处理超出上下文窗口的文本时所面临的挑战。
尽管人类的视野有限,一次只能看到一页内容,但仍然可以逐页阅读并理解整本书。在这个过程中,大脑就像一个缓存(cache),通过记忆保留并整合每一页的信息,从而掌握整本书的内容。
类似地,InfiniRetri将整篇文本拆分为连续的文本块(chunk)。
这种切分方式虽然与RAG相似,但不同之处在于,InfiniRetri不是并行处理每个文本块,而是按照顺序逐块迭代地处理每个文档。
这种方法能够保留文本的顺序信息,更符合人类的阅读习惯。
具体而言,如图4所示,在步骤1(切分,Chunk)中,研究团队根据句子边界将整个长文本划分为长度大致相等的文档块,其长度由方法参数ChunkSize³决定。
然后,这些文档块依次与缓存(Cache)中保留的token进行合并,形成完整的输入序列,称为MergeToken,并将其输入LLM进行处理。
InfiniRetri采用了类似滑动窗口注意力(Slide Window Attention,SWA)的迭代方式,按顺序处理每个文本片段。
然而,InfiniRetri对缓存的处理方式与传统方法有本质区别。
其中,A^h∈R^{n×m}表示查询(query)和键(key)组成的注意力矩阵,n是查询的数量,m是键的数量。
在注意力中检索(Retrieval In Attention)
在单个上下文窗口内,根据问题token准确定位相关的上下文token,注意力分配模式能够帮助LLM找到正确答案。
如果在滑动窗口框架内的每次推理过程中持续应用这一模式,理论上,LLM就可以在保持查询不变的情况下,对整个长文本进行推理。
这一过程与人类的阅读方式高度相似,类似于公认的「带着问题阅读」学习策略,即通过问题作为锚点,在LLM可处理的范围内逐步整合相关信息。
因此,LLM能否精准检索与问题最相关的文本,是本方法有效性的核心。
关键在于设计基于注意力得分分布的token检索策略和算法,以确保模型能够在长文本中高效提取关键信息。
借鉴实验结果,研究团队选取了多头注意力(Multi-Head Attention)的最后一层,并对所有注意力头的得分进行求和聚合(如公式2所示),探索了一种能够准确判断模型关注重点的方法。
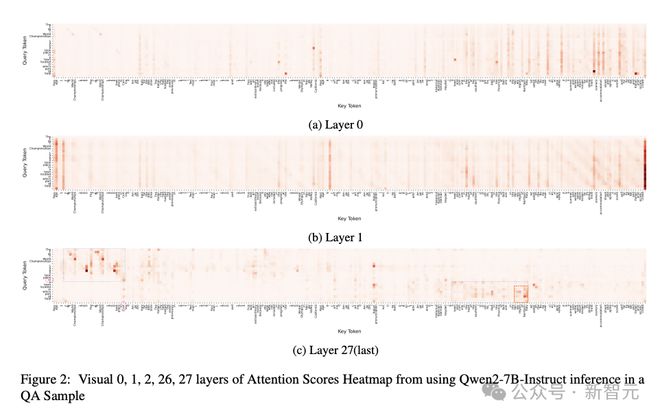
通过可视化注意力得分,研究团队观察到:与答案相关的信息通常由连续的token组成。
也就是说,它们以短语级别的粒度存在。
这一发现与在图2c的实验结果一致,进一步确认了LLM在token级别上具备较高的注意力精度。
因此,希望设计的操作是:计算每个token及其相邻token在2D注意力得分矩阵中的累积注意力得分。
计算结果将作为新的特征,在后续的检索过程中用于排序。经过深入分析,发现此操作等效于使用一个填充了1的卷积核(kernel)进1D卷积。
对于查询i和键j,其特征重要性计算如下:
1. 聚合所有注意力头的得分(公式2):
2. 基于1D卷积计算每个token及其相邻token的重要性(公式3):
其中,k是1D卷积核的大小,对应于方法中的参数Phrase Token Num。
3. 沿矩阵的列方向求和,计算每个上下文token的总重要性分数(公式4):
其中,s_i代表第i个上下文token的综合重要性分数。
4. 最后,选取重要性分数最高的前K个上下文token,并将其所在句子的所有token写入缓存(cache)。这个过程可表示为:
即,从所有token的重要性分数v中,选择排名前K的token,并将它们所在的完整句子存入缓存,以便后续推理时使用。
缓存句子Token(Cache Sentence Token)
在推理过程中对缓存(cache)的使用方式,InfiniRetri与传统方法存在本质性区别。
相比于直接使用缓存,InfiniRetri将其用于存储过去的上下文信息。
具体而言,主要有以下两点不同:
1 新方法在模型外部缓存token ID,而不是每层的历史键值(Key-Value)状态。具体来说,在推理过程中不使用传统的Key-Value缓存,而是在每次推理前,将过去的上下文信息与当前输入合并后再进行推理。
2 新方法基于短语级特征进行检索,并在缓存中存储包含Top-K token的句子级token。也就是说,存储的是完整的句子,而不是单独的token,从而确保检索到的信息更具上下文完整性。
事实上,正是这两项创新性改进,使得新方法在无需微调的情况下,就能比传统的KV缓存方法更有效地提升LLM处理长文本的能力。
新方法并不试图压缩缓存中的token,而是保留句子级别的相关上下文信息。这是因为,句子是最小的完整语义单元,相比于单个token,更能确保LLM对上下文的理解。
在LLM逐步推理每个文本片段的过程中,缓存中保留的中间结果是动态变化的,它们由先前存储的token和当前输入片段的组合决定。因此,在整个过程中,这些中间结果会相对调整和更新,以适应模型的理解需求。
AI界的「大海捞针」
大海捞针(Needle-in-a-Haystack,NIH)任务要求模型在一篇「超长文档」(「大海捞针」之海)中,精准检索出一个特定的目标句子(「针」),该句子可以被随机插入到文档的任意位置。
通过调整「针」的放置位置(文档深度)和上下文长度,反复测试以衡量模型的表现。
为了直观分析模型的检索能力,采用了热力图(heatmap)可视化实验:
这种可视化方法可以直观展示LLM处理长文本的能力上限,因此被广泛用于评估。
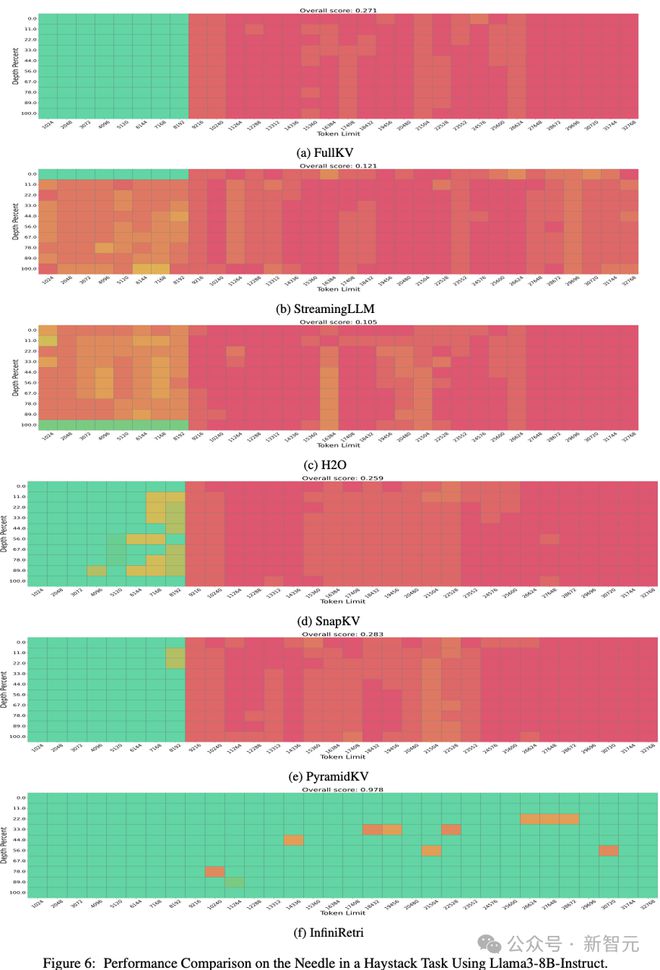
实验1:Llama3-8B-Instruct的对比
如图6所示,在Llama3-8B-Instruct模型上测试NIH任务,并与以下方法进行了对比:Full KV(完整KV缓存)
StreamingLLM、H2O、SnapKV、PyramidKV以及InfiniRetri(新方法)。
在最长32K token的输入文本上进行实验,结果表明:
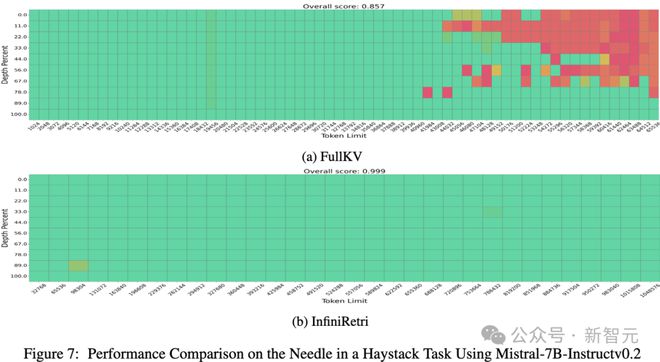
实验2:Mistral-7B-Instruct的对比
为了进一步验证InfiniRetri的有效性,在Mistral-7B-Instruct上扩展了输入长度。
Mistral-7B-Instruct官方支持的上下文窗口为32K token,对比了FullKV和InfiniRetri的表现,如图7所示:
关键发现与额外实验
进一步观察到:只要LLM在有限上下文窗口内具备足够的检索能力,新方法就可以赋能模型处理超长文本的检索任务,理论上可支持无限长输入。
基于这一发现,在更小的开源模型上的额外实验,结果符合预期:
新方法将该模型的有效上下文token长度从32K扩展至1M+,从而使其在NIH任务上具备了近乎无限的长文本处理能力(如图1所示)。
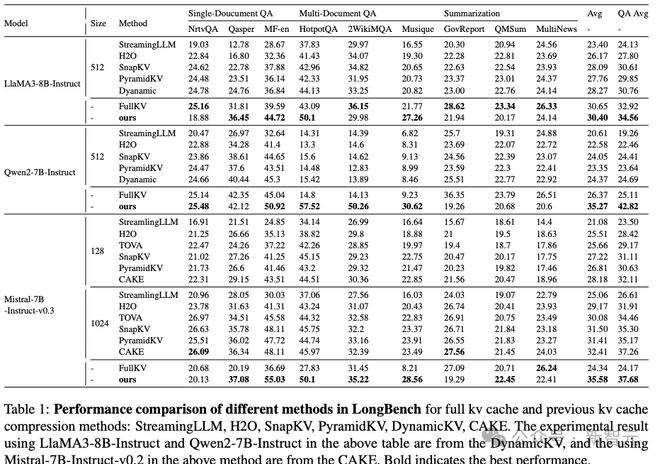
LongBench实验
从表1的整体实验结果来看,新方法是唯一一个在所有模型上全面超越Full KV的方法,其中在文档问答(DocumentQA)任务中的提升最为显著。
主要实验结果:
其中,Qwen2-7B-Instruct在HotpotQA任务上的表现提升最为显著,最大增幅达到288%(14.8→57.52)。
关键发现
随后,虽然新方法在长文档问答任务中取得了显著改进,但在文档摘要任务上的表现相对较差。
这种差异可能源于摘要任务的性质,这些任务通常需要更丰富的上下文信息来生成高质量的输出。
新方法无法一次性访问所有相关信息,这在一定程度上限制了它在这些任务中的有效性。
与问答和检索任务不同,在这些任务中,答案通常依赖于长上下文的一小部分,摘要任务则高度依赖于对整个上下文的全面理解。
因此,新方法可能需要进一步的优化和改进,以更好地应对这些摘要任务。
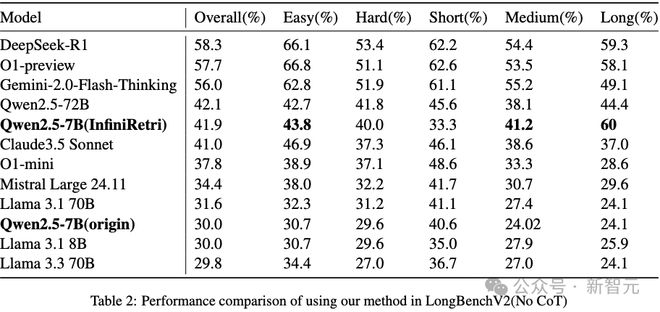
为了进一步评估InfiniRetri的有效性,使用最新的Qwen2.5-7B-Instruct模型在LongBenchV2上进行了额外的实验。
正如表2所示的结果,在应用了新方法InfiniRetri后,在处理LongBenchV2上的长文本和中等长度文本方面,Qwen2.5-7B整体性能与72B的对比模型相当,表现出显著的改进。
这一结果进一步验证了,只要LLMs在短上下文场景中表现出色,新方法就可以有效地提高其处理更长上下文文本的能力。
降低延迟与计算开销
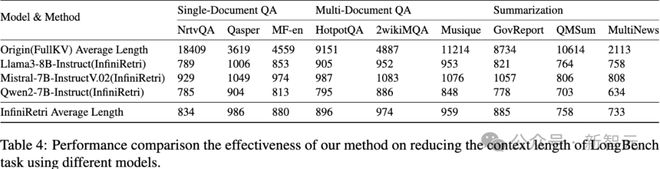
如前所述,新方法采用分段滑动窗口机制+迭代处理,在确保LLM推理长度保持在方法参数范围内的同时,仅在缓存中保留最相关的token。
这种机制使得LLM仅需处理长文本中的少部分关键信息,从而显著降低长文本处理时的推理延迟和计算开销。
正如表4所示,即使未对方法参数进行精细调整,新方法仍能在LongBench文档问答(QA)任务中,大幅降低推理成本,适用于Llama3-8B-Instruct、Mistral-7B-InstructV0.2和Qwen2-7B-Instruct等模型。
例如,在NtvQA任务中,仅保留4.5%的原始输入文本(18409->834);在HotpotQA任务中,Qwen2-7B-Instruct仅需处理8.7%的原始文本(9152->795),但推理性能提升高达288%。
这些实验结果进一步证明,新方法能够通过优化LLM在较小上下文窗口内的能力,有效提升其长文本处理能力。
这一发现表明,提升LLM的长文本处理能力不仅可以通过扩展上下文窗口,还可以通过优化模型在小窗口内的推理能力,再结合新方法机制,实现高效处理长文本的目标。
评论
这篇论文强调了一个本应显而易见的事实:预测和检索是同一枚硬币的两面。
要有效地进行预测,首先必须确定什么是相关的。令人惊讶的是,适当地利用注意力模式,拥有5亿参数的模型可以在100万个token上执行完美的检索。
这引发了一个有趣的问题:如果围绕检索能力明确设计架构会怎样?
Transformer架构是为预测而设计的,检索是作为副产品出现的。那么,专门为检索优化的架构会是什么样子呢?
许多资金已经投入到构建大规模RAG(检索增强生成)系统中。
如果这篇论文所承诺的性能改进是真实的,其影响将是巨大的。

参考资料:
https://arxiv.org/abs/2502.12962
https://github.com/gkamradt/LLMTest_NeedleInAHaystack
















热门推荐
51岁男子找17岁女孩代孕前已离异 收起51岁男子找17岁女孩代孕前已离异
- 2025年03月27日
- 00:31
- APP专享
- 扒圈小记
 34,385
34,385
华为智驾大师赛冠军开智驾出车祸?官方回应:协助进行事故处理和医疗安置,提醒用户规范使用智驾功能
- 2025年03月27日
- 02:19
- APP专享
- 扒圈小记
- 11,932
央行副行长宣昌能:将根据国内外经济金融形势择机降准降息
- 2025年03月27日
- 06:58
- APP专享
- 北京时间
- 4,534

24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)
投资研报 扫码订阅
股市直播
-

趋势领涨今天 14:39:21
=加入潜伏擒牛VIP,享四大顶级服务=【1】购买VIP自动加入私密小直播间!【2】每周3-5只超短金股调入调出服务,适合实时看盘的投资者!【3】每周一份高端内部绝密文章:包含近期布局、热点版块、指数预判!【4】每月2~3只高端中线金股服务!(VIP超短、中线个股均有涉足,让上班族也能跟上VIP节奏!)现月课7.5折,1288元!季课6.9折,3558元,续费季度更划算!新朋友可先月课体验!点网址,直接买,订购地址:【更多独家重磅股市观点请点击】【更多独家重磅股市观点请点击】 -

数字江恩今天 10:23:30
【3月限时vip活动】3月板块轮动加快,哪些赛道机会更好?数字江恩《股知道VIP》48小时VIP课程2元(原价8元),月课限时特价979元(原价1088元)。活动截止3月31日。【更多独家重磅股市观点请点击】 -
趋势领涨今天 10:07:58
【南向资金今日净买入逾41亿港元 泡泡玛特获净买入居前】南向资金今日净买入41.42亿港元,其中,泡泡玛特、阿里巴巴-W分别合计获净买入约7.25亿港元、3.64亿港元;盈富基金遭净卖出约14.42亿港元。 -
数字江恩今天 09:33:02
明日看3366-3386之间的选择,若先站上3386,那么2-b还可以延伸一点空间;反之,若先跌破3366,则立即确认2-c回踩开始。这里也不用过于担心,2-c确立后,能否跌破3340还两说了,而且哪怕跌破也空间非常有限。第二浪回踩有望在未来三个交易日内结束。 -
数字江恩今天 09:32:57
看5分钟图,今日的脉冲受阻与图上的3297-3341红色轮谷线。截止今日,3340的2-b结构反弹了54个点,和本人预期的50-60个点相吻合,时间也算合适。正常来说,2-b可以结束了。【更多独家重磅股市观点请点击】 -
数字江恩今天 09:32:44
板块上,今日化工板块继续炒作涨价概念,活跃度第一。光刻机、芯片、新能源、医药医疗也算是局部炒作,总的来说,都是局部炒作,市场没有明显热点。 -
数字江恩今天 09:32:38
A股两市今日成交4965 + 6942 = 11907 亿人民币,相对昨日成交金额略微提升,但成交量下跌。大盘今日低开后脉冲拉起新高,然后全天缓缓回调了约一半拉升幅度。个股方面,红盘个股略微超过了1/3,大幅下跌个股家数86家,和大幅上涨个股家数91家相当。 -
数字江恩今天 09:32:30
2-c回踩呼之欲出 -
趋势领涨今天 09:32:07
沪深北三大交易所年内的发行上市审核全线启动。3月26日,北交所召开年内首场上市委会议,四川西南交大铁路发展股份有限公司过会。有业内人士称,目前IPO申报不需要预沟通,发行人和中介机构可视情况进行申报。另有投行人士表示:“IPO申报数量后续将增加,但市场是否回暖还要再观察。”他认为,判断IPO是否常态化,应综合申报受理、发行上市等整体情况考量。这个是下午大盘回落的原因吗?这叫带病工作! -

北京红竹今天 07:59:00
3、短线有增仓2个组合,基本上长线组合没变化,好几天没有交易了,静等大级别调整之后的布局。短线组合昨天是55%的仓位,酱油股大跌没给机会出来,还在持有,早上跌停又买了一只算力10%的仓位,下午差点干到涨停吃个地天板,仓位就上到了65%。大级别末端只能发挥短线的作用,因为不格局,随时可以撤,这里长线和ETF没办法布局,长线需要格局的。