



新智元报道
编辑:编辑部
【新智元导读】Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。
LLM对数据的大量消耗,不仅体现在预训练语料上,还体现在RLHF、DPO等对齐阶段。
后者不仅依赖昂贵的人工标注数据,而且很可能让人类水平限制LLM的进一步发展。
今年1月,Meta和NYU的团队就提出了语言模型的自我奖励机制,使用LLM-as-a-Judge的提示机制,让模型在训练期间进行自我反馈。

论文地址:https://arxiv.org/abs/2401.10020
论文发现,即使不依靠人类标注者,LLM也能通过评价自己的响应实现性能提升。
最近,这个团队又发表了一篇研究,将LLM「自我奖励」这件事情再拔高了一个层次。

论文地址:https://arxiv.org/abs/2407.19594
毕竟是自己给自己打分,因此不能只关注模型作为actor如何从反馈中优化,也需要保证模型作为judge具备优秀的自我评价能力。
之前的研究就因为过于关注前者而忽略后者,造成了迭代训练期间性能的过快饱和。
甚至,还有可能造成比饱和更差的情况,即对奖励信号的过度拟合(reward hacking)。
因此,来自Meta、NYU、UC伯克利等机构的研究者们提出,还需要增加一个「元奖励」步骤——让模型评价自己的评价,从而提升评价能力。

虽然听起来有点绕,但实际是合理的。而且实验发现,加上这一层嵌套有显著的提升效果。
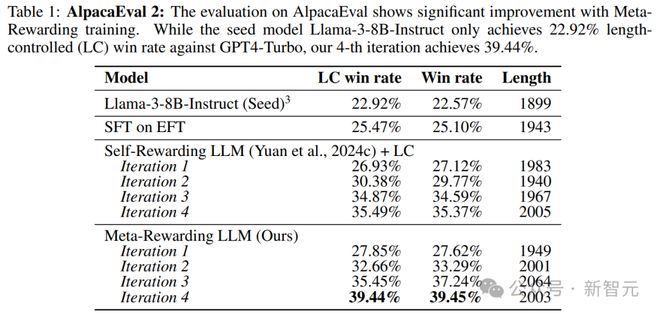
比如Llama-3-8B-Instruct在AlpacaEval 2上的胜率就从22.9%增至39.4%,比GPT-4的表现更佳;在Arena-Hard上则从20.6%提升至29.1%。
如果说,今年1月发表的研究是LLM-as-a-Judge,那么这篇论文提出的「元奖励」,就相当于LLM-as-a-Meta-Judge。
不仅Judge不需要人类,Meta-Judge也能自给自足,这似乎进一步证明,模型的自我提升可以摆脱对人类监督的依赖。
Meta科学家Yann LeCun也转发了这篇研究,并亲自下场玩起了双关梗——

Meta提出的Meta-Judge,FAIR能否实现fair?
研究不重要,重要的是Meta FAIR这一波曝光率拉满了。

元奖励(Meta-Rewarding)
用更直白的话说,「元奖励」方法就是在原有的actor-judge的互动中再引入meta-judge,且由同一个模型「分饰三角」,不需要额外人类数据的参与。
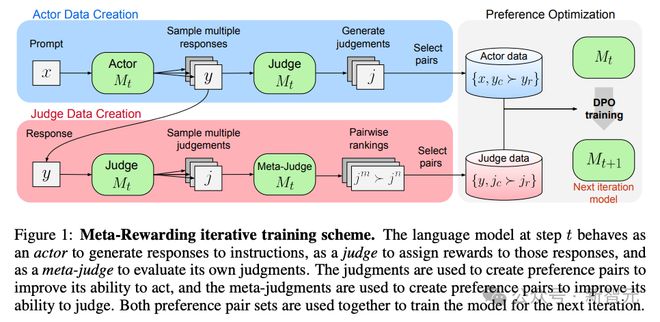
其中,actor负责对给定提示生成响应;judge负责为自己的响应进行评价和打分;而meta-judge会对自己的打分质量进行对比。
最终的优化目标,是希望actor能生成更好的响应,但训练效率依赖于judge的准确率。
因此,meta-judge作为训练judge的角色,可以同时提升模型作为actor和judge的性能。
这三种角色组成的迭代训练模式如图1所示,在第t个步骤中,先收集模型M_t对提示x的响应,由再让M_t对自己进行评价,由此得到用于训练actor的偏好数据。
之后,给定同一个响应内容y,让M_t生成各种不同评价的变体,由meta-judge进行打分和排名,由此得到用于训练judge的偏好数据。
结合上述的两类偏好数据,通过DPO方法对模型M_t进行偏好优化,就完成了一轮迭代,得到模型M_(t+1)。
长度偏好
之前的工作曾经发现,作为judge的模型会偏好更长的响应,这会导致多轮迭代后答案的「长度爆炸」。
因此,作者引入了一种简洁的「长度控制」(length-control)机制——使用参数ρ∈[0,1],权衡judge的评分和响应文本长度。
比如,对于分数在第一梯队的模型响应,即分数范围为[(1-ρ)Smax+ρSmin, Smax],选择其中最短的响应作为最优答案。
Judge偏好数据的创建
首先,选择judge最没有把握的模型响应,通过分数方差衡量judge的确定性。对于每个选中的响应y,我们有最多N个对应的模型评价{j1, … , jN}。
之后,对其中的每一对(jm, jn)进行成对评估,使用如图2所示的meta-judge提示模板。

除了给出评价结果,meta-judge还需要生成CoT推理过程。
为减少meta-judge可能存在的位置偏好(可能倾向于选择最先出现的Judgment A),对同一对数据(jm, jn)会交换顺序让meta-judge进行两次评价,得到单次结果rmn:

引入参数w1、w2用于表征可能存在的位置偏好:

其中win1st和win2nd表示在meta-judge的整个评价过程中,两个位置的评价分别有多少次胜出。
用以上变量构建「对决矩阵」(battle matrix)B记录每一次的最终结果:
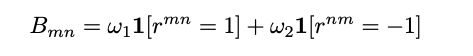
利用Elo评分,可以从矩阵B计算meta-judge给每个judge赋予的元奖励分数。
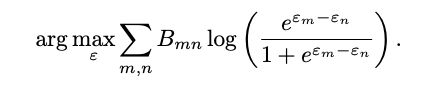
作者发现,meta-judge和judge一样,也会展现出「长度偏好」,倾向于选择更长的评价意见。
为了避免最终训出的模型过于啰嗦,构建judge数据集时也采取了过滤措施。如果meta-judge选中的评价意见超过一定长度,整个数据对都会被直接舍弃。
评估实验
实验准备
实验使用Llama-3-8B-Instruct作为种子模型,其他方面的实验设置与之前发表的论文《Self-Rewarding Language Models》一致。
在元奖励训练之前,实验首先在EFT(Evaluation Fine-Tuning)数据集上对种子模型进行监督微调(SFT)。
EFT数据集是根据Open Assistant构建的,并提供初始的LLM-as-a-Judge训练数据,包含经过排名的人类响应,能训练模型充当法官。
对于元奖励迭代,实验利用2万个提示,由Llama-2-70B-Chat经过8-shot提示生成。
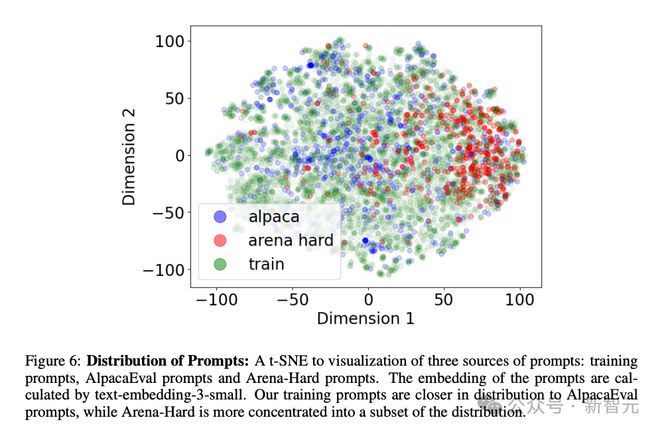
如上图所示,训练所用的提示在分布上更接近AlpacaEval数据集,而Arena-Hard的提示集中分布于训练提示的一个子集。
对于每次迭代,实验从该种子集中抽取5,000个提示,总共进行四次迭代。
迭代过程如下:
- Iter 1:从初始的SFT模型开始,使用DPO(Direct Preference Optimization)对生成的actor和judge的偏好对进行训练,获得M1。
- Iter 2:使用DPO对M1生成的actor和judge偏好对进行训练,获得M2。
- Iter 3/4:使用DPO仅对M2/M3生成的actor偏好对进行训练,获得M3/M4。
每个prompt都让模型生成K=7个响应,每次迭代总共生成3.5万个响应。然后,我们过滤掉相同的响应(通常删除不超过50个重复项)。
接下来,使用相同的采样参数为每个响应生成N = 11^2个不同的判断。
评估方法
元奖励模型的目标是要让模型既能自己「演」,还能自己「评」,因此实验也要评估模型在这两个角色中的表现如何。
基线模型是前述论文中提出的自我奖励模型,带有相同的「长度控制」机制,可以直接对比出元奖励机制带来的性能增益。
首先,先看看如何评判「演」的怎么样。
实验利用三个基于GPT4-as-a-Judge的自动评估基准,包括AlpacaEval 2、Arena-Hard和MT-Bench,分别侧重于模型的不同方面。
例如,AlpacaEval主要关注聊天场景,提示集涵盖了各种日常问题。
相比之下,Arena-Hard包含更复杂或更具挑战性的问题,要在预定义的7个方面(创造力、复杂性、问题解决能力等)满足更多的标准。
MT-Bench有8个不同的问题类别,主要评估模型的多轮对话能力。
另一方面,为了评估LLM法官「评」的怎么样,实验测量了LLM给的分数与人类偏好的相关性。如果没有可用的人类标注数据,则使用较强的AI法官代替。
指令跟随评估
图3展示了在AlpacaEval基准上,元奖励方法(带有长度控制机制)胜率随训练迭代的变化。
总体来看,元奖励的胜率从22.9%大幅提升到39.4%,超过了GPT-4,并接近Claude Opus模型。
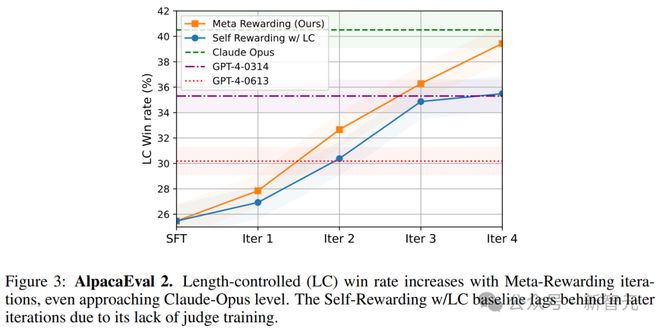
考虑到种子模型参数量只有8B,并且,除了在SFT阶段使用的EFT数据集,没有引入任何额外的人工数据,这是一个相当优秀的结果。
另外,结果也证明了meta-judge和长度控制机制的重要性。
自我奖励模型训练到超过3轮时,开始出现饱和迹象,但带有元奖励的模型并没有,到第4轮时仍保持性能增长。
这表明了对模型评价能力进行训练的重要性,以及meta-judge这一角色的有效性。
如表1所示,经过4轮迭代,无论是自我奖励模型还是元奖励模型,平均响应长度(以字符为单位)都没有显著增加,证明长度控制机制的有效性。
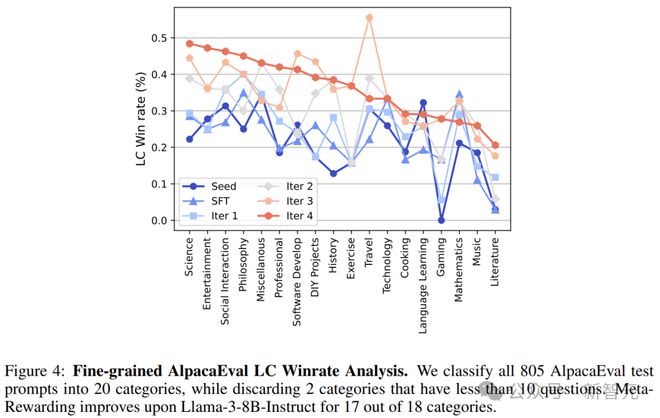
元奖励机制有以下三个较为明显的改进。
首先,将AlpacaEval中的805个类别细分为18个类别进行详细分析,可以看到,元奖励几乎改进了所有类别的响应(图4),包括需要大量知识和推理的学科,例如科学(Science)、游戏(Gaming)、文学(Literature)等。
值得注意的是,旅游(Travel)和数学(Mathematics)这两类,模型并没有实现显著提升。
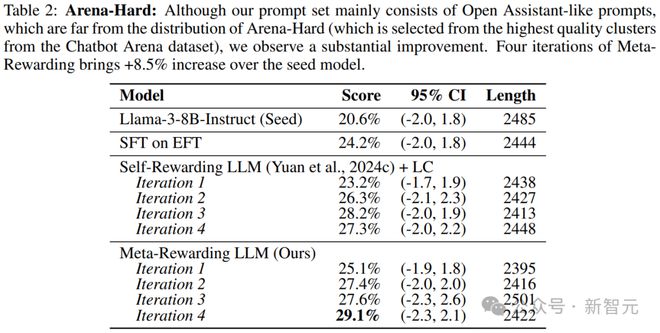
第二,元奖励改进了对于复杂和困难问题的回答。
实验进一步使用Arena-Hard评估在元奖励方法在回答复杂和具有挑战性的问题上的表现。
表2中的评估结果显示,元奖励在4次迭代中都能提高分数,与种子模型(20.6%)相比,显著提高了8.5%。
第三,元奖励在仅训练单轮对话的情况下也并未牺牲多轮对话能力。
论文进行了MT-Bench评估,以检查在仅训练单轮数据的情况下多轮对话能力的损失。
结果如下表显示,元奖励模型的4次迭代显著提高了第一轮对话得分,从8.319(种子模型)提高到8.738,而第二轮对话得分仅下降了不超过 0.1。
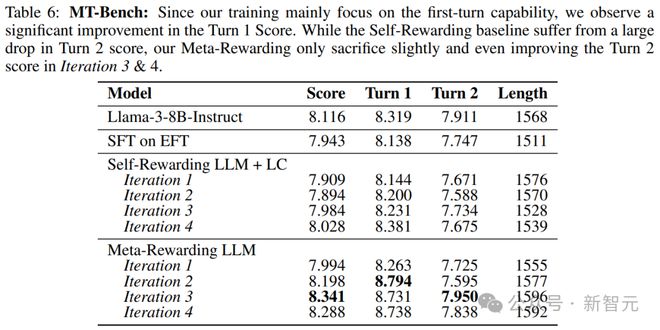
这是对基线模型中自我奖励+长度控制(Self-Rewarding + LC)的巨大改进,因为后者通常会在第二轮对话得分上,下降超过 0.2,同时没有提高第一轮对话得分。
奖励模型评估
实验评估了模型对种子模型Llama3-8B-Instruct生成响应的判断准确性。
在缺乏人工标注的情况下,作者选择测量元奖励模型与当前最强的判断模型gpt-4-1106-preview之间的评分相关性。
分析采用了两种略有不同的设置,主要区别在于它们如何处理判断模型给出的平局,因此使用了两种指标:将平局计为0.5的一致性分数(agreement)和舍弃平局结果的一致性分数。
结果显示,模型在进行训练后判断能力有所提高。
表3中的分析显示,与基线模型相比,在两种评估设置中,元奖励与强大的GPT-4判断模型之间的相关性显著提高。
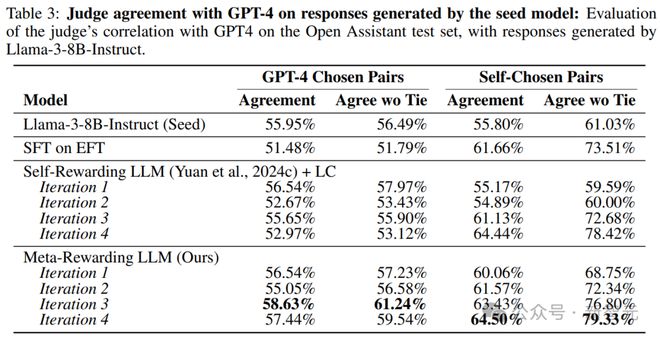
这些结果表明,元奖励方法能够改进模型判断能力,使其评估结果与更复杂的语言模型GPT-4的评估结果更加接近。
此外,实验对比了模型判断结果与Open Assistant数据集中人类响应排名的相关性(表7),发现元奖励训练提高了与人类的判断相关性。
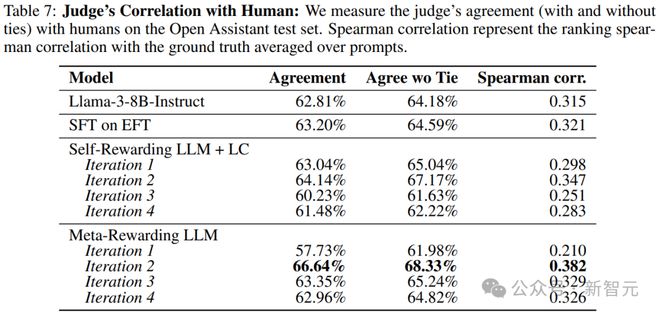
然而,这种改进在后续训练迭代中没有持续,可能是由于模型生成的响应与人类响应之间的分布差异导致的。
分析
长度控制机制
长度控制机制对于保持模型响应的全面性和简洁性之间的平衡至关重要。
实验比较了最后一次训练迭代中不同长度控制参数ρ的结果,如表4所示:
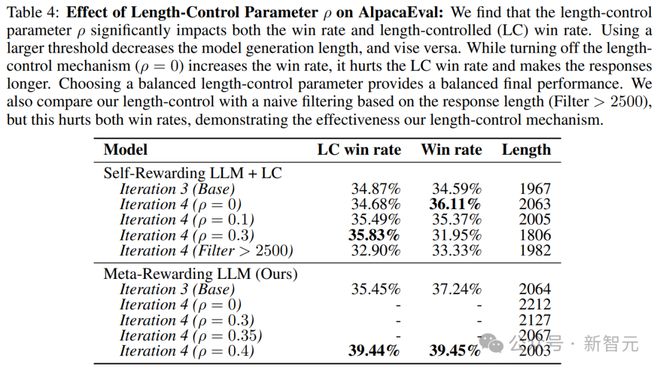
ρ = 0,相当于在偏好数据选择中不进行任何长度控制。
正如预期的那样,这种训练方式使得模型生成的响应变得过于冗长,LC胜率降低。
使用外部奖励模型进行训练
元奖励机制让模型自己作为judge,来评估其自身的响应;实验尝试了使用强大的外部奖励模型Starling-RM-34B作为对比。
然而,结果发现StarlingRM-34B未能在第一次迭代中提高AlpacaEval的LC胜率(24.63% vs. 27.85%),这可能是由于其长度偏见。
meta-judge偏见
在元奖励训练的第一次迭代之后,meta-judge几乎总是更倾向于更高分数的判断,如表5所示。
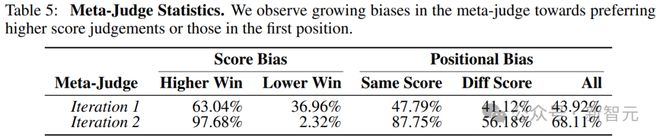
这种分数偏见显著地将判断的评分分布向满分5分倾斜。对于位置偏见,我们也看到在训练过程中有增加的趋势,特别是在比较两个相同分数的判断时。
判断评分变化:为了调查在元奖励训练迭代过程中判断评分分布的变化,实验使用与奖励建模评估相同的验证提示。
使用Llama-3-8B-Instruct在每个提示上生成7个响应,然后为每个响应生成11次判断。图5是评分分布的可视化,密度是使用高斯核密度估算的。
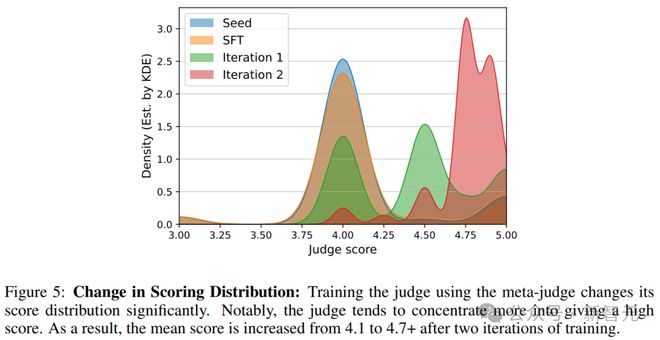
可见,使用meta-judge训练判断进一步增加了其生成高分的可能性。
然而,判断训练的前两次迭代使其倾向于分配4.5、4.75、4.9的分数,根据根据指示这些分数应该是整数。
尽管这些是高分,但它们提供了更细致的区分能力,以区分不同质量的响应。
结论
实验提出了一种新机制,通过使用meta-judge为作为judge的模型分配元奖励(meta-rewards),从而提高模型的评判能力。
这解决了自奖励(Self-Rewarding)框架的一个主要限制,即缺乏对模型评判能力的训练。
为了使元奖励训练(Meta-Rewarding training)更加有效,实验还引入了一种新的长度控制技术,以缓解在使用AI反馈进行训练时出现的长度爆炸问题。
通过自动评估基准AlpacaEval、Arena-Hard和MT-Bench,元奖励方法的有效性也得到了验证。
值得注意的是,即使在没有额外人类反馈的情况下,这种方法也显著改进了Llama-3-8B-Instruct,并超越了依赖大量人类反馈的强基线方法自奖励(Self-Rewarding)和SPPO。
此外,评估模型的评判能力时,它在与人类评判和强大的AI评判(如 gpt-4-1106-preview)的相关性上表现出显著的改进。
总体而言,研究结果提供了有力的证据,证明无需任何人类反馈的自我改进模型是实现超级对齐(super alignment)的一个有前途的方向。
参考资料:
https://arxiv.org/pdf/2407.19594



VIP课程推荐
APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




