安装新浪财经客户端第一时间接收最全面的市场资讯→【下载地址】
OpenAI的对手越追越紧了。
美国当地时间4月18日,Meta发布了Llama 3开源大模型,包括Llama 3 8B和Llama 3 70B。Meta同时透露,目前其最大参数模型已超400B(4000亿)参数,但还在训练。据Meta称,Llama 3是迄今为止功能最强的开源LLM(大语言模型)。在多项基准测试中,Llama 3 70B超过同行。
随着Llama 3发布,开源阵营呈现壮大之势。对于Llama 3的发布,大模型生态社区OpenCSG创始人陈冉向记者表示,竞争会越来越激烈,好现象是大家处于良性竞争。不过未来参数越大,消耗越大,“竞争其实就是钱的竞争”。

Llama 3登场
据Meta介绍,Llama 3 8B和70B的推理、代码生成和指令跟踪等功能有大幅改进。Meta使用了超15T tokens(文本单位)的数据训练,训练数据集比Llama 2大7倍,包含的代码多4倍。在开发中,Meta开发了一套新的高质量人类评估集,包含1800个提示并涵盖12个关键用例,如征求建议、头脑风暴、分类、编码等。该评估集的结果显示,Llama 3 70B的表现比Claude Sonnet、Mistral Medium、GPT-3.5、Llama 2更好。
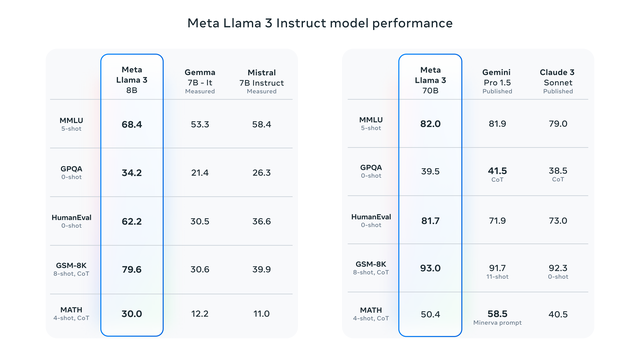
Meta还公布了两个新开源模型与竞争对手比较的情况。在MMLU、GPQA等多项五项基准上,指令微调的Llama 3 8B得分都超过谷歌(175.75, 1.54, 0.88%)Gemma 7B-1t和法国初创公司Mistral AI的Mistral 7B Instruct,Llama 3 70B则在三项基准中超过谷歌Gemini Pro 1.5和Anthropic的Claude 3 Sonnet。
不过,Llama 3并非完美,其中被指摘最多的是其上下文窗口只有8k,落后于现在业内平均水平。Meta首席人工智能科学家、图灵奖得主杨立昆(Yann LeCun)在社交媒体发帖同步Llama 3发布的喜讯,而评论区有不少人都在讨论上下文窗口长度只有 8k的信息,“这很令人惊讶,确实限制了实用性”,有热门评论说道。有人质疑为什么Llama 3的上下文窗口与同等模型相比这么小,是架构的限制,还是在训练期间决定优先考虑模型的其他方面,这并未得到杨立昆答复。
外界对Llama 2上下文窗口的关注,背景之一是近两年大模型上下文窗口的文本长度限制已提升明显。更长的上下文这意味着大模型能处理更大范围的文本,更好理解长篇文章或对话,使其在各种应用中更加有用。GPT-3.5上下文窗口文本长度限制为4k,GPT-4提升到32k,GPT-4 turbo版能接收128k输入,基本相当于10万字的小说长度。在国内,零一万物Yi-34B、上海人工智能实验室与商汤科技联合发布的书⽣·浦语2.0等都支持200k长语境输入,月之暗面kimi更支持200万字上下文输入,阿里(140.62, 0.67, 0.48%)通义千问免费开放了1000万字长文档处理功能。
对于长上下文窗口的限制,Meta并未直接回应,但在其官方博客里提到,在接下来的几个月里预计将引入新功能、更长的上下文窗口。
对于后续计划,Meta还透露, Llama 3系列还会有更多产品推出,其最大模型超400B参数,该模型还在训练中。
目前,Meta还未透露Llama 3超4000亿参数版本是否会开源。如果该模型开源,将会超过目前参数量最大的开源模型昆仑万维天工3.0(4000亿参数)和马斯克旗下初创公司xAI的Grok-1(3140亿参数)。
业界对Llama 3发布颇为关注。AI写作助手公司HyperWrite AI CEO Matt Shumer感叹“我们正在进入一个新世界,GPT-4级别的模型开源而且可以免费访问”。传奇研究员、AI开源倡导者吴恩达表示,Llama 3发布是自己收到过最好的生日礼物。马斯克也在一条评论Llama 3表现出色的帖文下回复“Not bad(不错)”。
阿里云首席智能科学家丁险峰在社交软件上表示,开源的Llama 3有如安卓,一夜之间打掉所有闭源手机操作系统:PalmOS、Windows mobile、symbian,伟大的时代要来临了。
英伟达科学家Jim Fan则在社交媒体上表示,即将推出的Llama 3 400+B将意味着开源社区获得GPT-4级别的模型开放权重访问,这将是一个分水岭时刻,将改变许多研究工作和初创公司的发展方式。
Jim Fan提取了Anthropic Claude 3 Opus、Open AI GPT-4 Turbo、谷歌Gemini Ultra 1.0和Gemini Pro 1.5的多项基准得分并与Llama 3 400+B早期Checkpoint(检查点)的得分相比,发现Llama 3 400+B多项得分高于Gemini Ultra 1.0和Gemini Pro 1.5,低于但已接近GPT-4和Claude 3 Opus。
猎豹移动(5.145, 0.15, 3.00%)董事长兼CEO傅盛则表示,Llama 3性能远超上一代,小参数模型Llama 3 8B的表现比上一代大参数Llama 2 70 B更好,这印证了小参数模型的能力会快速提升,可达到相当高使用水准的说法。Llama 2 70B性能比上一代则有质的提高。预期Llama 3应该代表了开源社区非常高的水准。
也有业界人士使用了Llama 3 8B后表示,原本工具使用稳定性费劲的本地多智能体变得稳定了不少。陈冉则告诉记者,当前国内的开源模型与Llama 3相比或许相差还不小。
OpenAI的对手紧追
OpenAI今年2月发布Sora,成功“狙击”谷歌彼时刚发布的Gemini 1.5并引来更多关注后,似乎难以再压低竞争对手的热度了。OpenAI还未拿出更大“杀器”的情况下,竞争对手的产品升级则是肉眼可见。
有OpenAI最强竞争对手之称的Anthropic今年3月发布了最新大模型系列Claude 3,其中Claude 3 Opus在本科级别专业知识(MMLU)、研究生级别专家推理(G[QA)、基础数学(GSM8K)等领域都超过GPT-4。
Anthropic之外,闭源阵营的OpenAI其他竞争对手则在上探参数量。传言GPT-4参数量上万亿,今年3月,腾讯透露其混元大模型也已达万亿参数规模,近日MiniMax也宣布推出abab 6.5,包含万亿参数。
谷歌、Meta、xAI所属的开源或开闭源双轨并行的阵营也在步步紧逼,参数量越来越大。马斯克指责OpenAI不开源并陷入双方论战后,自己拿出Grok-1。国内也引发一轮开源潮,包括4月初大模型初创企业新旦智能与APUS联手开发的APUS-xDAN大模型4.0(1360亿)参数,以及昆仑万维近日开源的4000亿参数天工3.0。
此次Meta开源的8B和70B参数模型还是小试牛刀,后续或开源的4000亿以上参数大模型,可能是开源阵营的更大“杀器”。
关于开闭源之争近日趋于激烈,也隐隐显露出包括OpenAI在内的闭源阵营,受到开源阵营的一定冲击。相关代表性言论包括百度(94.8, 1.41, 1.51%)董事长李彦宏近日所称“大模型开源意义不是很大,有商业模式的闭源模型才能聚集人力和财力”。
支持大模型开源的业界人士则在反击李彦宏的观点。4月18日的生成式AI大会上,vivo AI解决方案中心总监谢伟钦表示,作为产品经理,希望开源社区能逐渐繁荣,出现不同维度的好算法,vivo开源了参数量7B的模型,未来可能还有更大参数的模型开源。
硅基智能CTO林会杰在该会上则表示,开源一定会比闭源好,搜索引擎目前只运行在开源软件上,开源产品的开发效率好,这是无数开发者已验证过的事。同时,开源软件面向更广泛人群,代码质量被更多人看在眼里,不敢开源反而是对自身模型能力不自信的一种表现,很多闭源模型也是建立在开源模型之上。
傅盛也表示:“国内某大厂认为闭源大模型与开源社区的距离越来越远,现实情况正好相反,开源社区公司越来越猛烈。怼算力、怼芯片、只注重参数这条路未必走得通,而且AI不应该是大公司和巨头之间的游戏,应该是所有人都能参与的。我们相信,开源社区必将越战越勇,最终打败闭源大模型。“
闭源和开源阵营竞争对手步步紧逼的情况下,OpenAI的压力很可能变得越来越大。新浪微博(10.92, 0.10, 0.92%)新技术研发负责人张俊林认为,大模型巨头混战形成了打压链,OpenAI处于链条顶端,打压有潜力追上的对手,第一层对手包括谷歌、Anthropic和Mistral,第二层是Meta,OpenAI有一个技术储备库,专等竞争对手发布新产品时推出。不过,竞争对手正试图改变被OpenAI打压的情况,此前Anthropic推出Claude 3便可能打乱OpenAI的产品节奏。
张俊林向第一财经记者表示,OpenAI最新推出的是一个音频模型Voice Engine,该模型还在小规模测试阶段,这可能说明OpenAI手里已没太多新东西了,竞争对手已对OpenAI造成比较大压力。
竞争压力下,OpenAI或已经在加快下一代GPT产品研发。3月Claude 3系列发布不久,有网友就发现搜索引擎一度能搜到GPT-4.5 Turbo产品页面,页面摘要显示该模型将在“速度、准确性和可扩展性方面全面超越GPT-4.0 Turbo”,相关页面很快下架。OpenAI如何应对这些竞争,将是下一步看点。
(本文来自第一财经)


责任编辑:王许宁

















热门推荐
视频|网友调侃:海尔老总还没大葱高!海尔老总回应:他说的对!我很高兴为山东大葱代言 收起视频|网友调侃:海尔老总还没大葱高!海尔老总回应:他说的对!我很高兴为山东大葱代言
- 2025年03月08日
- 00:50
- APP专享
- 扒圈小记
 5,756
5,756
意大利总理提议北约集体防御条款适用于乌克兰
- 2025年03月08日
- 01:25
- APP专享
- 扒圈小记
- 4,686
冲击全球第六!《哪吒2》票房破147亿,将在日本上映!背后A股公司宣布:拟12.2亿买楼
- 2025年03月08日
- 08:59
- APP专享
- 北京时间
- 1,967

24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)
投资研报 扫码订阅
股市直播
-

趋势领涨今天 10:51:39
【2月深圳新房成交暴涨197% 深铁前海时代·尊府入市锁定“日光”?】今年政府工作报告首次提出“稳住楼市”,并释放了多项地产利好信号,为后续市场回暖奠定了基础。市场方面,2025年2月深圳新建商品住宅成交面积25.6万平米,同比增长197.2%。面对3月小阳春,深铁集团将推出多个新房产品,其中豪宅项目“深铁前海时代·尊府”也将入市,户型为245-285平方米四居,共计77套,样板间于3月8日开放。该项目此前多次出现“日光”,市场普遍预期此次推出的房源也将迅速售罄,凸显深圳高端住宅市场的火爆需求。 -
趋势领涨今天 05:29:59
私募股权公司Sycamore Partners与老牌连锁药店沃博联达成最终协议,以近100亿美元价格将后者私有化,包括债务在内的交易总价值为237亿美元。这笔交易预计将于今年四季度完成。沃博联的市值自2015年以来已下跌90%,截至当地时间6日为93亿美元。 -
趋势领涨今天 00:27:08
=加入潜伏擒牛VIP,享四大顶级服务=【1】购买VIP自动加入私密小直播间!【2】每周3-5只超短金股调入调出服务,适合实时看盘的投资者!【3】每周一份高端内部绝密文章:包含近期布局、热点版块、指数预判!【4】每月2~3只高端中线金股服务!(VIP超短、中线个股均有涉足,让上班族也能跟上VIP节奏!)现月课7.5折,1288元!季课6.9折,3558元,续费季度更划算!新朋友可先月课体验!点网址,直接买,订购地址:【更多独家重磅股市观点请点击】【更多独家重磅股市观点请点击】 -
趋势领涨今天 00:26:42
人工智能是后期主要发展方向,这点没有任何疑问,人工智能板块的炒作也是后期主要热点,这点也没有疑问,但近期涨幅确实有点大了,树不能长到天上去,虽然后期还有行情,但短期也有调整的风险。该消息主要涉及的是AI+教育,前期也已经经过了多次炒作,所以,大家还是要注意追涨的风险。另外,骏利亨德森投资环球科技领先团队表示,近期减持中资科技股,将资金调回美股。这个信号也要引起大家的注意。三、美国2月非农就业人数略低于市场预期 降息预期降温美国2月季调后非农就业人口15.1万人,预期16万人,前值由14.3万人修正为12.5万人。数据公布后,美国短期利率期货下跌;交易员不再押注美联储5月降息。美国利率期货交易员现在押注美联储要等到6月才能重新开始降息。以前市场预期美联储将在12月份才有降息,随后提到5月份降息,现在美国2月非农就业人数低于预期,市场不再预期5月份会有降息,总之,美联储要降息时,公布的数据都是符合降息的;否则,美国公布的数据都是不利于降息。一句话就是美联储通过不断地恐吓,将资金留在国内,给美国服务,但美元指数的大幅回调,说明资金正在逃离美国,东升西落,美国正在进入衰退期,大摩将2025年美国GDP增长预测下调至1.5%,之前的预测为1.9%,这个应该也是信号。资金都是逐利的,只要有一小部分资金能够进入A股市场,A股今年出现牛市是可能的,但前提是内资不能天天砸盘!下周重要事件将要落幕,大盘应该会迎来震荡,但中期走势还是向好的,所以,大盘回调将是机会。今天是三八节,没有太阳、花朵不会开,没有爱、幸福不会来,没有妇女,也就没有爱,所以,妇女是爱的根源,也是爱的源泉,祝天下妇女三八节快乐! -
趋势领涨今天 00:26:37
昨天港股再创新高,港股这波走势确实很牛,港股恒生指数大涨超过32%,恒生科技指数大涨近50%,主要原因就是港股里面有国内科技股巨头腾讯、阿里等,而A股连上攻3400点的勇气都没有,主要原因就是量化资金收割,垃圾股太多,港股炒业绩,A股炒垃圾,这就是宿命!所以,我们始终认为,本轮炒作要盯紧港股,港股一旦见顶,A股必定见顶,只要港股能够继续上行,最终资金会流向A股,因为以前港股便宜,A股跟港股的逆差较大,但经过本轮上涨以后,A股跟港股的逆差已经大幅缩小,随着后期进一步缩小,A股就会变成低估了,所以,对今年的行情不悲观,但短期不会一帆风顺。一、华为正式组建医疗卫生军团据科创板日报,华为正式组建医疗卫生军团。据悉,医疗卫生军团将重点构建AI辅助诊断解决方案体系,推动医疗大模型在临床场景的应用。华为作为国内领军企业,不管走到哪个行业,都会引发大家的关注,华为+都将是行业龙头,比如华为算力,华为汽车等,现在华为组建医疗卫生军团,这就是华为+医疗,再叠加AI+医疗,后期医药板块会迎来机会,当然重点是跟AI对应,比如医疗、创新药方向等。二、北京:从2025年秋季学期开始 全市中小学校开展人工智能通识教育北京市推进中小学人工智能教育工作方案发布,从2025年秋季学期开始,全市中小学校开展人工智能通识教育,每学年不少于8课时,实现中小学生全面普及。学校可将人工智能课程独立设置,也可与信息科技等课程融合开展。 -
趋势领涨今天 00:26:34
大家早上好!趋势为王,做股海的领航者,新的一天,新的战斗,欢迎你来到本直播室!新进的朋友请注意点赞,收藏本直播室,以方便你下次观看,谢谢大家的支持!【更多独家重磅股市观点请点击】 -
趋势领涨2025-03-07 23:56:04
晚间重大消息:1、美国2月非农就业人数增加15.1万人,不及市场预期;美国2月失业率为4.1%,预估为4%,前值为4%。2、高盛将美国2025年GDP增长预期从此前的2.2%下调至1.7%,摩根士丹利则从此前的1.9%下调至1.5%。3、美联储主席鲍威尔表示,美联储不需要急于调整利率;特朗普政府政策影响的不确定性仍然很高;不会对一两项超出预期的经济数据做出过度反应。4、美股三大指数集体收涨,道指涨0.52%,本周累计下跌2.37%;纳指涨0.7%,本周累计下跌3.45%;标普500指数涨0.55%,本周累计下跌3.1%。热门中概股多数收涨,纳斯达克中国金龙指数涨0.47%,本周累涨4.93%。15、WTI原油期货结算价涨1.02%,报67.04美元/桶,本周累计下跌3.9%;布伦特原油期货结算价涨1.19%,报70.36美元/桶,本周累计下跌3.36%。 -

数字江恩2025-03-07 09:44:18
简单来说,3384后已经震荡了2周时间了,再震荡主要也就是下周一二而已。所以下周前半周关注3336+-10区间支撑,只要不跌破,大盘还会继续向上运行。 -
数字江恩2025-03-07 09:44:12
30分钟图来看,15分钟级别的abc只是将大盘拉回了前三角形的轮谷线位置,而宽幅震荡则是在红色轮谷线下的横盘震荡箱体。下周5分钟图的3336+-10只要不跌破,那么横盘震荡完毕,大盘必将站上红色轮谷线。至于站上红色轮谷线后的首轮高度,下周末再说不迟。【更多独家重磅股市观点请点击】 -
数字江恩2025-03-07 09:44:00
这是3384之后的5分钟震荡结构,简单来说,下周出还可以有震荡,但是不应该明显超过图上第一轮的回踩,即第一轮最低点3337不应该跌破超过10个点了,3336+-10支撑,也就是不有效跌破5周线,这个震荡结构都将要完美而开始新的1上涨。【更多独家重磅股市观点请点击】