

真·拿嘴做视频!Meta“AI导演”一句话搞定视频素材,网友:我已跟不上AI发展速度

欢迎关注“新浪科技”的微信订阅号:techsina
文 | 鱼羊 Alex
来源:量子位
画家执笔在画布上戳戳点点,形成手绘作品独有的笔触。
你以为这是哪部纪录片的画面?
No,No,No!
视频里的每一帧,都是AI生成的。
还是你告诉它,来段“画笔在画布上的特写”,它就能直接整出画面的那种。
不仅能无中生画笔,按着马头喝水也不是不可以。
同样是一句“马儿喝水”,这只AI就抛出了这样的画面:

好家伙,这是以后拍视频真能全靠一张嘴的节奏啊……
不错,那厢一句话让AI画画的Text to Image正搞得风生水起,这厢Meta AI的研究人员又双叒给生成AI来了个超进化。
这回是真能“用嘴做视频”了:
AI名为Make-A-Video,直接从DALL·E、Stable Diffusion搞火的静态生成飞升动态。
给它几个单词或几行文字,就能生成这个世界上其实并不存在的视频画面,掌握的风格还很多元。
不仅纪录片风格能hold住,整点科幻效果也没啥问题。

两种风格混合一下,机器人在时代广场蹦迪的画面好像也没啥违和感。

文艺小清新的动画风格,看样子Make-A-Video也把握住了。

这么一波操作下来,那真是把不少网友都看懵了,连评论都简化到了三个字母:
而大佬LeCun则意味深长地表示:该来的总是会来的。

毕竟一句话生成视频这事儿,之前就有不少业内人士觉得“快了快了”。只不过Meta这一手,确实有点神速:
比我想象中快了9个月。
甚至还有人表示:我已经有点适应不了AI的进化速度了……

文本图像生成模型超进化版
你可能会觉得Make-A-Video是个视频版的DALL·E。
实际上,差不多就是这么回事儿

前面提到,Make-A-Video是文本图像生成(T2I)模型的超进化,那是因为这个AI工作的第一步,其实还是依靠文本生成图像。
从数据的角度来说,就是DALL·E等静态图像生成模型的训练数据,是成对的文本-图像数据。
而Make-A-Video虽然最终生成的是视频,但并没有专门用成对的文本-视频数据训练,而是依然靠文本-图像对数据,来让AI学会根据文字复现画面。
视频数据当然也有涉及,但主要是使用单独的视频片段来教给AI真实世界的运动方式。
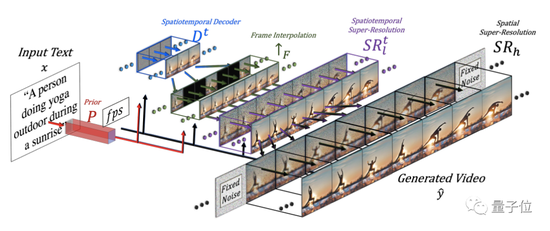
具体到模型架构上,Make-A-Video主要由三部分组成:
-
文本图像生成模型P
-
时空卷积层和注意力层
-
用于提高帧率的帧插值网络和两个用来提升画质的超分网络
整个模型的工作过程是酱婶的:
首先,根据输入文本生成图像嵌入。
然后,解码器Dt生成16帧64×64的RGB图像。
插值网络↑F会对初步结果进行插值,以达到理想帧率。
接着,第一重超分网络会将画面的分辨率提高到256×256。第二重超分网络则继续优化,将画质进一步提升至768×768。
基于这样的原理,Make-A-Video不仅能根据文字生成视频,还具备了以下几种能力。
将静态图像转成视频:

根据前后两张图片生成一段视频:

根据原视频生成新视频:

刷新文本视频生成模型SOTA
其实,Meta的Make-A-Video并不是文本生成视频(T2V)的首次尝试。
比如,清华大学和智源在今年早些时候就推出了他们自研的“一句话生成视频”AI:CogVideo,而且这是目前唯一一个开源的T2V模型。
更早之前,GODIVA和微软的“女娲”也都实现过根据文字描述生成视频。
不过这一次,Make-A-Video在生成质量上有明显的提升。
在MSR-VTT数据集上的实验结果显示,在FID(13.17)和CLIPSIM(0.3049)两项指标上,Make-A-Video都大幅刷新了SOTA。

此外,Meta AI的团队还使用了Imagen的DrawBench,进行人为主观评估。
他们邀请测试者亲身体验Make-A-Video,主观评估视频与文本之间的逻辑对应关系。
结果显示,Make-A-Video在质量和忠实度上都优于其他两种方法。

One More Thing
有意思的是,Meta发布新AI的同时,似乎也拉开了T2V模型竞速的序幕。
Stable Diffusion的母公司StabilityAI就坐不住了,创始人兼CEO Emad放话道:
我们将发布一个比Make-A-Video更好的模型,大家都能用的那种!
而就在前几天,ICLR网站上也出现了一篇相关论文Phenaki。
生成效果是这样的:
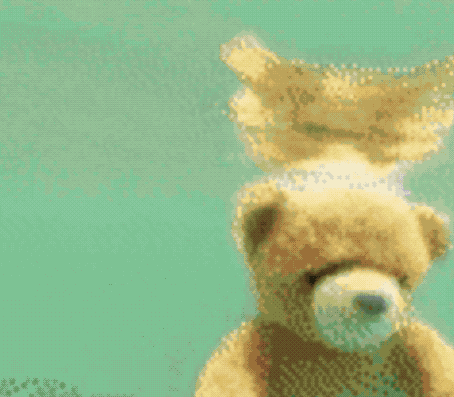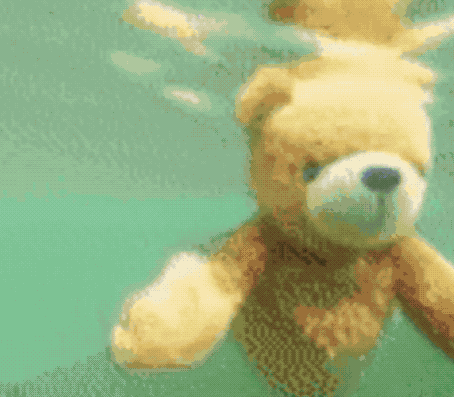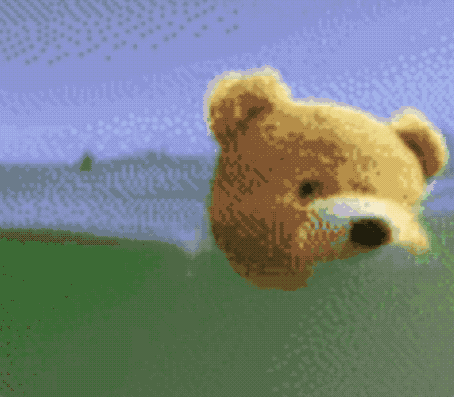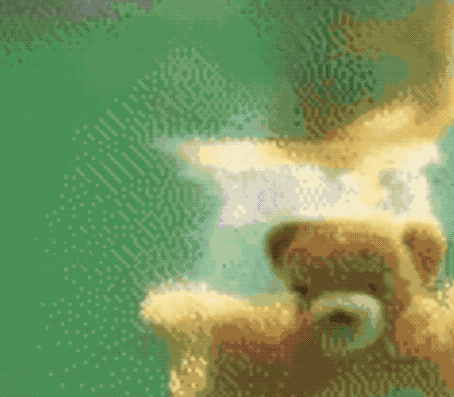
对了,虽然Make-A-Video尚未公开,但Meta AI官方也表示,准备推出一个Demo让大家可以实际上手体验,感兴趣的小伙伴可以蹲一波了~

(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介




