

Facebook&哥大等推出实验性AI框架,音视频信息可自由转换文本!
来源:新智元
对于人工智能来说,开发一个能可靠地理解世界、并使用自然语言作出反应的对话系统是一个很大的挑战。
如果要达到这一目标,那么我们需要一个能够从图像、文本、音频和视频中提取突出信息,并以人类能够理解的方式回答问题的模型。
最近,Facebook、哥伦比亚大学、佐治亚理工学院和达特茅斯大学的研究人员开发了Vx2Text——一个从视频、语音或者音频中生成文本的框架。他们声称,相比之前的最先进的方法,Vx2Text可以更好地创建说明文字并回答问题。

论文地址:
https://arxiv.org/pdf/2101.12059.pdf
与大多数人工智能系统不同,人类可以很自然地轻易理解文本、视频、音频和图像在上下文语境中的含义:
例如,一些给定的文本和图像,在分开讨论的时候似乎无害,比如“看看有多少人爱你”和一张贫瘠沙漠的图片,然而,人们会立即意识到,这些元素在结合在一起的时候,其实是具有潜在伤害性的。
多模态学习可以包含一些潜在互补的信息或者趋势,不过,只有在学习中完全包含相关信息的时候,这些含义才能显现。
对于Vx2Text,,“模态独立“的分类器将来自视频、文本或音频的语义信号,转换为公共语义语言空间,这使得语言模型能够直接解释多模态数据,从而为通过谷歌的T5等强大的语言模型进行多模态融合——即结合信号来支持分类——提供了可能。
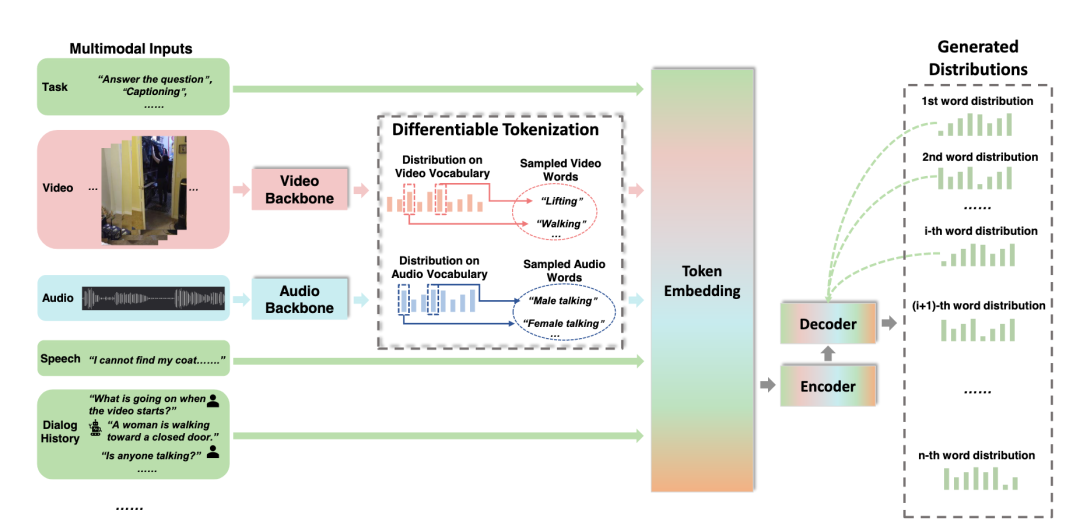 图:模型框架
图:模型框架Vx2Text中的生成式文本解码器,将编码器计算的多模态特征转换为文本,使该框架适合于生成自然语言语义概括,如下图:
研究人员在论文中写道:“与之前的方法相比,这种设计不仅简单得多,而且具有更好的性能。”
“更有用的是,它并不需要设计专门的算法,或者借鉴其他替代方法来实现多模态信息的组合”
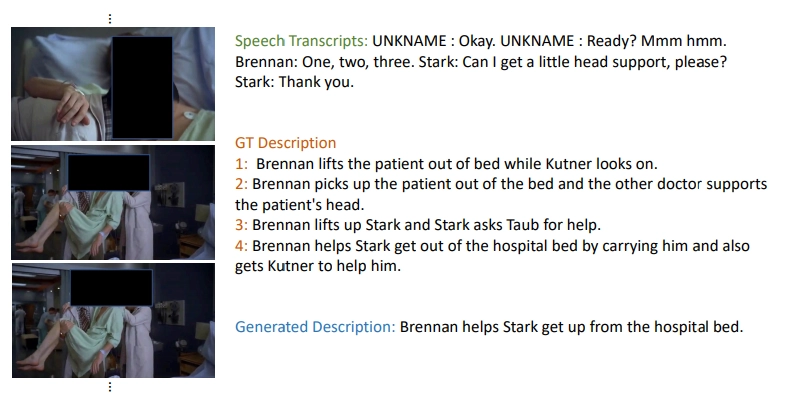
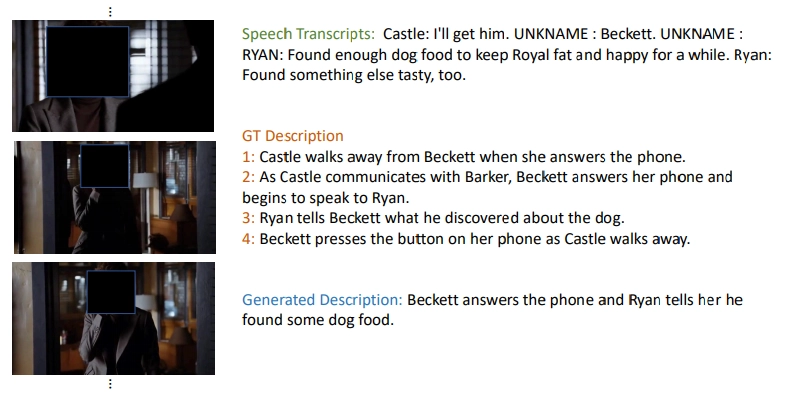
在实验中,研究人员展示了Vx2Text为带有视频和音频的视频场景所生成的「真实的」自然文本。
尽管研究人员研究人员以对话历史和语音记录的形式,为模型提供了上下文,但是他们注意到,生成的文本包括了非文本形式的信息,例如帮助某人帮助某人站起来或者接电话等行为。
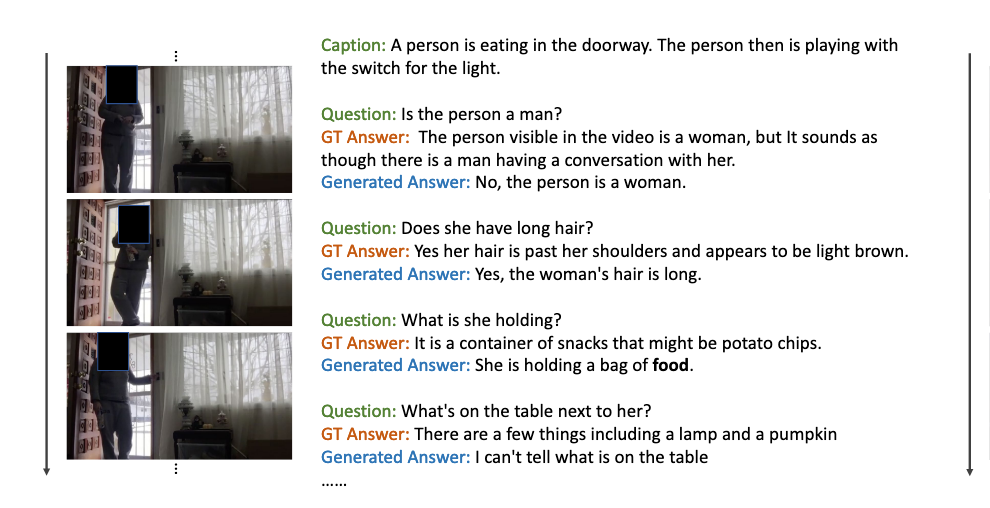
此外,由于Vx2Text可以高度整合、概括和真正理解多模态输入中蕴含的信息,因此,基于生成的语义信息,它也可以回答各种各样的问题:
Vx2Text可以用于工业界,比如,它可以用于为流媒体视频添加标题来增加访问性。
此外,这个框架也可能会用于YouTube和Vimeo等视频分享平台——这些平台依赖字幕和其他信息来提高搜索结果的相关性。
研究人员表示:“我们的方法从将所有形式的信息映射到语义语言空间的想法出发,来实现直接应用强大语言模型——Transformer网络的目标,这使得我们的整个模型都可以进行端到端的训练。“
参考链接:
https://venturebeat.com/2021/02/02/researchers-vx2text-ai-framework-draws-inferences-from-videos-audio-and-text-to-generate-captions/


(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介
作者文章
推荐阅读
- 奈雪上市,“薛定谔的奶茶股”到底甜不甜?
-

- 二级市场的疯狂正在上演,瑞幸的泡沫破灭,似乎并不妨碍其他新茶饮玩家带来的新市场想象力。“薛定谔的甜”,总得试过才知道。详细>>
- 造车就是“顺势而为”,除了贾跃亭
-
- 新造车行业诡异地出现了一个共识——创业者在低谷期出国,是危险动作。详细>>
- 叮咚买菜,背水一战?
-

- 叮咚买菜要上市了。详细>>
- 你在支付宝上搞钱,“90后”却在相亲
-

- 近日,支付宝的基金讨论区掀起一股“相亲风”,大批“90后”在平台上寻找有缘人,特别是这一两日,有愈演愈烈之势,从始发地招商中证白酒指数基金的讨论区溢出至多个热门基金。详细>>