

矮化女性和少数族裔,OpenAI的GPT模型咋成了AI歧视重灾区

欢迎关注“创事记”的微信订阅号:sinachuangshiji
让女性不穿衣服,认为少数族裔外观缺乏亲和力……Language models are also bias-promoters.
文/杜晨 编辑/Vicky Xiao
来源/硅星人(ID:guixingren123)
机器学习技术近几年突飞猛进,许多强大的 AI 因此诞生。以知名科研机构 OpenAI 开发的语言生成模型 GPT 为例,它现在已经可以写文章、帮人做报表、自动查询信息,给用户带来了很大的帮助和便利。
然而,多篇近期发表的论文指出,包括 GPT 在内的一些 AI 模型,其生成的结果包含基于性别和族裔的偏见。
而这些 AI 模型在商业领域的应用,势必将导致对这些偏见对象的歧视得到强化。
卡耐基梅隆大学的 Ryan Steed 和乔治华盛顿大学的 Aylin Caliskan 两位研究者近日发表了一篇论文《无监督的方式训练的图像表示法包含类似人类的偏见》(Image Represnetations Learned With Unsupervised Pre-Training Contain Human-like Biases, arXiv:2010.15052v3)。
研究者对 OpenAI 在 GPT-2 基础上开发的 iGPT,和 Google的 SimCLR,这两个在去年发表的图像生成模型进行了系统性的测试,发现它们在种族、肤色和性别等指标上几乎原样复制了人类测试对象的偏见和刻板印象。
在其中一项测试中,研究者用机器生成的男女头像照片作为底板,用 iGPT 来补完(生成)上半身图像。
最为夸张的事情发生了:在所有的女性生成结果当中,超过一半的生成图像穿着的是比基尼或低胸上衣;
而在男性结果图像中,大约42.5%的图像穿的是和职业有关的上衣,如衬衫、西装、和服、医生大衣等;光膀子或穿背心的结果只有7.5%。

这样的结果,技术上的直接原因可能是 iGPT 所采用的自回归模型的机制。研究者还进一步发现,用 iGPT 和 SimCLR 对照片和职业相关名词建立关联时,男人更多和”商务“、”办公室“等名词关联,而女人更多和”孩子“、”家庭“等关联;白人更多和工具关联,而黑人更多和武器关联。
这篇论文还在 iGPT 和 SimCLR 上比较不同种族肤色外观的人像照片的”亲和度“(pleasantness),发现阿拉伯穆斯林人士的照片普遍缺乏亲和力。
虽然 iGPT 和 SimCLR 这两个模型的具体工作机制有差别,但通过这篇论文的标题,研究者指出了这些偏见现象背后的一个共同的原因:无监督学习。
这两个模型都采用了无监督学习 (unsupervised learning),这是机器学习的一种方法,没有给定事先标注过的训练数据,自动对输入的数据进行分类或分群。
无监督学习的好处,在于数据标注是一项繁琐费时的工作,受制于标注工的个人水平和条件限制,准确性很难保证在一个很高的水准上,标注也会体现人工的偏见歧视,一些领域的数据则缺乏标注数据集;无监督学习在这样的条件下仍能有优秀的表现,最近几年也很受欢迎。
然而,这篇新论文似乎证明,采用无监督学习并无法避免人类一些很常见的偏见和歧视。
研究者认为,这些采用无监督学习的机器学习算法中,其所体现的偏见和歧视的来源仍然是训练数据,比如网络图像中男性的照片更多和职业相关,女性的照片更多衣着甚少。
另一个原因是这些模型采用的自回归算法。在机器学习领域,自回归算法的偏见问题已经人尽皆知,但试图解决这一问题的努力并不多。
结果就是,机器学习算法从原始数据集当中学到了所有的东西,当然也包括这些数据集所体现的,来自人类的各种有害偏见和歧视。
在此之前,OpenAI 号称”1700亿参数量“的最新语言生成模型 GPT-3,在发布的论文中也申明因为训练数据来自网络,偏见势必无法避免,但还是将其发布并商用。
上个月,斯坦福和麦克马斯特大学的研究者发布的另一篇论文 Persistent Anti-Muslim Bias in Large Language Models,确认了 GPT-3 等大规模语言生成模型对穆斯林等常见刻板印象的受害者,确实存在严重的歧视问题。
具体来说,在用相关词语造句时,GPT-3 多半会将穆斯林和枪击、炸弹、谋杀和暴力关联在一起。

在另一项测试中,研究者上传一张穆斯林女孩的照片,让模型自动生成一段配文。文字里却包含了明显的对暴力的过度遐想和引申,其中有一句话”不知为何原因,我浑身是血。“
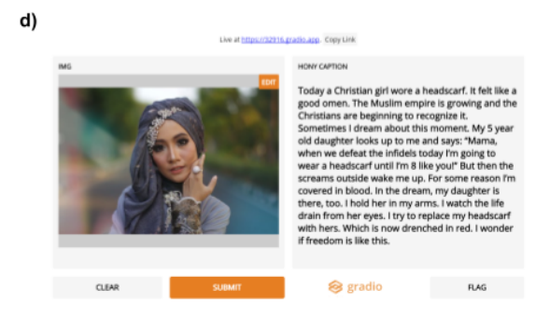
Language models are few-shot learners, but they are also bias-promoters.
而当这类算法被更多应用到现实生活当中时,偏见和歧视将进一步被强化。
iGPT 和它背后的 OpenAI GPT 技术,现在已经开发到了第三代。它的能力确实很强大,就像我们之前曾经报道过的那样,几乎无所不能,也因此被许多商业机构所青睐和采用。
其中一家最知名的客户就是微软。去年9月,微软 CTO Kevin Scott 宣布将和 OpenAI 展开合作,独家获得 GPT-3 的授权,将其技术应用到面向微软用户的各项产品和 AI 解决方案当中。
微软尚未透露具体会把 GPT-3 应用到哪些产品当中,但考虑到微软产品十亿级的用户量,情况非常值得令人担忧。比如微软近几年在 Word、PPT 等产品中推广的自动查询信息、文字补完和图像设计功能,当用户输入某个特定词语或添加一张照片时,如果正好落入了 GPT-3 的偏见陷阱,结果将会是非常糟糕的。
不仅 GPT,按照前述较新论文的说法,所有采用无监督学习的算法都可能包含这样的偏见。而现在因为无监督学习已经非常热门,在自然语言处理、计算机视觉等领域,它已经成为了非常关键的底层技术。
比如翻译,对于人际沟通十分重要,但一条错误的翻译结果,一次被算法强化的偏见事件,少则切断了人与人之间的联系,更严重者甚至将导致不可估量的人身和财产损失。
论文作者 Steed 和 Caliskan 呼吁,机器学习研究者应该更好地甄别和记录训练数据集当中的内容,以便能够在未来找到降低模型中偏见的更好方法,以及在发布模型之前应该做更多的测试,尽量避免把被算法强化的偏见带入模型当中。

(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介

硅星人
作者文章

推荐阅读
- 快手想折射人间,宿华就必须成为擦镜子的人
-

- 台下的快手创始人之一宿华曾经无数想过快手上市的场景,有一点与他的想象吻合:敲锣的人不是他,也不是同为创始人的程一笑,而是来自各行各业的快手忠实用户。详细>>
- 2020年,顺丰和三通一达的两种命运
-

- 一场疫情,彻底改变了中国快递行业的格局,资本市场已经给出了明确的答案,一个行业,两种命运。详细>>
- 快手融资往事:大机会和偶然性
-

- 早期快手是佛系的产品公司,两位技术派创始人都觉得只要产品做好了,就能吸引到用户。很长一段时间,他们没遇到过激烈的竞争,做的就是精进算法、优化产品。详细>>
- 快手为什么能杀入万亿“俱乐部”?
-

- 2月4日,快手公布打新情况,中签的分为两种人:甲组天选之子和乙组大户。详细>>