

内存256KB设备也能人脸检测,微软提出用RNN代替CNN | NeurIPS 2020
来源:量子位
蕾师师 发自 凹非寺
量子位 报道 | 公众号 QbitAI
为了让更多IoT设备用上AI,在条件“简陋”的单片机上跑图像识别模型也成为一种需求。
但是图像识别对内存有较高的要求,一般搭载MCU的设备内存都不高,怎样才能解决这个问题呢?
最近,微软提出了一种RNNPool方法,甚至可在内存只有256 KB的STM32开发板上运行人脸检测模型。

这篇论文也发表在近期举行的顶会NeurIPS2020上,相关代码已经开源。
CNN难以适应单片机低内存
目前,计算机视觉领域的主要架构都是基于CNN,但是CNN对处理器的内存要求比较高,所以对于微型处理器,更加不友好。
CNN主要分成两个部分,一是卷积层,用来提取被输入图像的视觉特征。二是池化层,用来组合特征,并且简单表达出来。
但这样的结构真的非常消耗内存,假如我们输入一张56×56的8位图像,在处理的过程中,至少需要800KB的内存。
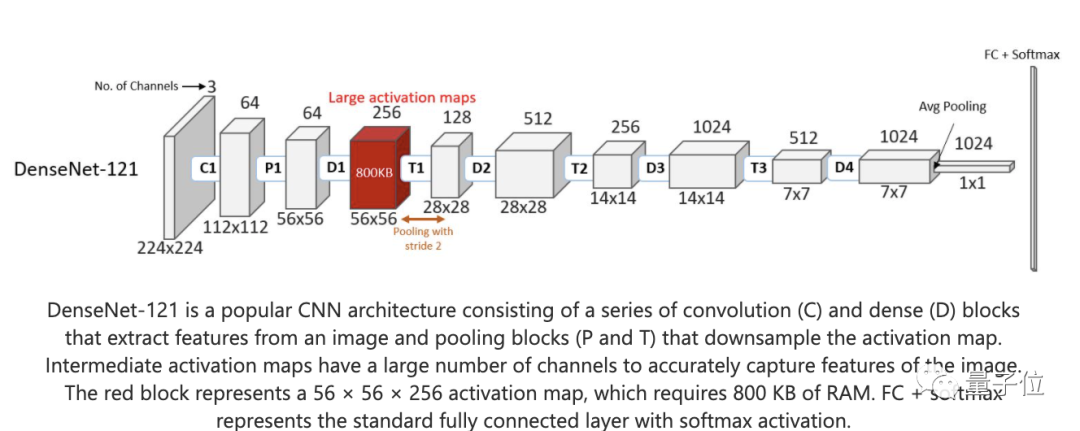
边缘AI往往内存和功耗都有限,大多数Arm Cortex-M4微控制器设备的内存都少于256 KB。
显然,CNN方法应用在这类边缘设备上是不现实的。
虽然压缩激活图的大小可以减少输出通道的数量,但这可能会导致精度大大降低。
另一种方法是对图的行/列数量进行下采样。
假设是一个28×28×256的激活图取代56×56×256激活图。那么,一个图像就可以压缩到200 KB内。
池化算子和带状卷积是下采样激活图的标准方法,但这个方法依赖于相对简单和有损的聚合。若将其应用于较大的接收域,或者图像模块进行更激进的下采样,则可能会导致其精度降低。
因此,如上图中所示,在大多数标准CNN架构中,这种运算符仅限于在2×2的接收域才能保证它的准确度。
而且这种方法只将激活图大小减少了四倍,满足不了我们的要求。
因此,我们需要找到一个池化算子,它既可以总结激活图的大模块,并可以一次性降低激活图的大小。
这种方法就叫做RNNPool。
RNNPool所需内存减少80~90%
RNNPool在语法上等效于池化算子,可以快速减小中间图的大小。它的模型层数更少,对内存要求更低,可以在内存受限的小型设备上分析图像。
RNNPool由两个学习递归神经网络(RNN)组成,它们以每个模块为单个向量,在水平和垂直方向上扫过激活图的每个模块。
RNNPool获取一个激活图的模块并将其汇总为1×1体素,然后逐步执行下采样步骤。RNNPool可以支持8×8,甚至16×16的模块大小,并且可以以步长s = 4或s = 8采样,而不会显著降低精度。

第一个RNN遍历每一行和每一列,并将它们全部汇总为h1维的1×1体素,第二个RNN双向遍历这些体素,并且生成一个最终的1×4×h2向量。其中,h1是第一遍RNN隐藏状态的大小,其中h2是第二个RNN隐藏状态的大小。
因此,它可以在不损失准确度的情况下大幅降低激活图的采样率。

由于RNNPool与池化算子等价,所以它可用于替换CNN中的所有池化运算符,降低对内存需求。
将RNNPool放在CNN架构的开头,可以快速采样激活图,降低峰值内存需求。
在大多数情况下,研究人员发现基于RNNPool的模型所需的内存可以减少至原来的10~20%。同时,仍能保持几乎相同的准确度。
实验测试结果
研究人员将基于RNNPool的人脸检测模型(称为RNNPool-Face-M4)在一个叫做SeeDot的工具上编译。
RNNPool-Face-M4用在Arm Cortex-M4微控制器的STM32F439-M4器件上,通过测试,它能在10.45秒内处理单个图像,它的峰值内存仅需要188 KB。
再通过跟EagleEye(小型设备领域的SOTA技术)比较,可以看到,RNNPool-Face-Quant在内存消耗上的225KB明显明显优于EagleEye的1.17MB。

Demo
微软团队还基于RNNPool制作了两个图像任务Demo。
其中一个是脸部识别。
在训练时,根据参数不同,输入图像将为640x640的RGB图,或者为320x320的的单色图。
在测试时,主要运用了两种模式。一是为一组样本图像生成边界框的评估模式,二是计算诸如mAP分数之类的测试模式。
测试方法一是将图像保存在特定的文件夹中,并在具有高置信度的脸部周围标志上边框。如下图所示:

测试方法二对于每个图像,都提供了单独的预测文件,文件中的每一行都对应一个标识框。对于每个框,将生成五个数字:框的长度,框的高度,x轴偏移,y轴偏移,存在脸部的置信度值。
除了面部识别的程序代码外,他们还贴出了一个Visual_Wakeword的代码库,这是一个二元的识别程序,即判断图像里面,是否有人的出现。
官方介绍:
https://www.microsoft.com/en-us/research/blog/seeing-on-tiny-battery-powered-microcontrollers-with-rnnpool/
论文地址:
https://www.microsoft.com/en-us/research/publication/rnnpool-efficient-non-linear-pooling-for-ram-constrained-inference/
开源代码:
https://github.com/microsoft/EdgeML/blob/master/pytorch/edgeml_pytorch/graph/rnnpool.py
https://github.com/microsoft/EdgeML/tree/master/examples/pytorch/vision

(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介
作者文章
推荐阅读
- 华为“造车”背后的阳谋
-

- 华为造车有句名言:华为不造车,但我们聚焦ICT技术,帮助车企造好车。详细>>
- 共享办公没做错什么,为何仍以失败告终?
-

- 两三年前,创业者青睐共享办公,很大的原因在于租一个工位可以享受咖啡区、多形式休闲讨论区、会议室等多个公共区域,但现在这些似乎将不复存在。详细>>
- 警惕以“效率”为名的无限掠夺
-

- 社区团购舆论战硝烟弥漫,不少人以拥护自由市场的姿态纷纷站出来,为美团优选等辩护,他们逻辑是:社区团购本质上是提高生鲜等零售流通的效率,这是电商创新,我们不能因噎废食。详细>>
- 被资本收割前,不妨多薅一把社区团购羊毛
-

- 当资本和媒体都在关注社区团购这条赛道时,那些真正的用户和“团长”们却并不在乎这些。详细>>