




 我们仍在思考近几个月在圣路易斯SC25超级计算会议前后宣布的所有新型
我们仍在思考近几个月在圣路易斯SC25超级计算会议前后宣布的所有新型-AI超级计算机系统,特别是HPC国家实验室发布的一系列新机器不仅推动技术进步,还将降低仍驱动大量高性能计算仿真和建模工作的FP64浮点运算成本。
和你们许多人一样,我们认为高性能计算的本质正在发生变化,这不仅因为机器学习和现在的生成式人工智能,还包括混合精度的出现,以及可以更换求解器以使用它,或者使用更低精度的数学单元模拟FP64处理。这肯定会是十年后半段的有趣表现。
与此同时,鉴于仍有大量FP64原生代码存在,我们认为有必要从长远角度观察FP64计算引擎的性能如何随着引擎数量不断扩展和淘汰而逐步提升。我们也认为机器所需的资本投入越来越高,但幸运的是,生成式人工智能让花费数十亿美元打造超级计算机变得“正常”。
如果你能让他们预算四倍于计算机,因为电脑一半时间都在做生成式人工智能,那么你最终还是能获得两倍的高性能计算性能......而且你不需要超级计算机来做这些计算。
无论如何。
正如我们在一篇名为《Show Me The Money: What Money For The HPC Buck?》的报道中指出的。 早在2015年,也就是我和我亲爱的妻子Nicole创立The Next Platform的时候,建造一台更快的超级计算机比降低计算成本容易得多。生成式AI的兴起使GPU加速器的成本远高于预期,同时GPU网络规模也大幅提升,类似于超级计算机制造商如SGI、Cray和IBM在1990年代中期研发的紧密耦合联邦互连,这也显著增加了集群成本。
将这些庞大的GPU服务器扩展成集群所需的带宽需求也非常高,远比过去要高得多。稀缺性、高需求以及技术复杂性正在推高规模化成本,尽管FP64计算的单位成本确实以曲折方式持续下降。
我们分别对 FP16 和 FP4 的 AI 工作负载机制进行了比较,因此请注意,本文仅聚焦于那些仍高度依赖双精度浮点数学的高性能计算中心。我们知道求解器正在以混合精度重铸,以及尾崎方法,该方法允许用更低精度的INT8单元模拟FP64,提升仿真和建模应用的整体有效吞吐量。那是另一个故事了。(事实上,我们正在努力解决这个问题。)
此外,比较旨在说明,而非详尽。自从Cray 1A矢量超级计算机问世48年来,它实际上创造了与大型机和小型计算系统区分开来的超级计算市场,后者可以通过辅助协处理器进行计算,因此很难获得系统成本。是的,还有变化,还有,我不仅选择了定价不精确的问题,还涉及超级计算的混合架构,正如1989年IBM System/3090与向量设施对抗Cray X-MP所体现的那样。这是我职业生涯初期写的第一篇高性能计算(HPC)决选。(我也是混合型,一直都是,我一直做企业计算和超级计算,后来加入了超大规模工具、云构建器,现在又加入了人工智能模型构建器。)
我们一直认为高性能计算是性能的代价,而生成式人工智能的繁荣,按这个定义,无疑是一种高性能计算。云计算和超大规模企业通常会优化最佳的性价比,而普通企业、政府和学术机构则倾向于在有限预算内优化计算。话虽如此,高性能计算社区在对大型系统在各种工作负载下的性能进行基准测试,并将这些结果公开给公众,同时也提供了部分定价信息。这不仅仅是数据利他主义,更反映了国家和州高性能计算中心由公共资金支持,因此其预算属于公开记录。此外,政客和高性能计算中心理所当然地喜欢吹嘘他们在制造超级计算机方面的实力——就像如今几乎每天都在做的超大规模模型制造者一样。
我们知道这些数字并不完美,而且每一个重要的高性能计算系统都没有被展示出来。但所选机器都是当时的旗舰系统,既反映了架构选择,也反映了当时预算的限制。我们调整了旧机器的成本以适应通胀,我们认为这对长期来说很重要。下表和图表中的性能为FP64精度下的理论顶峰兆浮点浮点。我们还展示了机器中的并发——即GPU和XPU中包含的核心总数,以及如今流式多处理器或混合核心。随着25年前时钟频率停滞,节点和互联节点系统中对性能的需求越来越高,并发显然大幅增长。
诚然,我们本可以挖掘并填充更多1970年代、1980年代和1990年代初的机器,但最终选择了1977年的Cray 1A和1986年的Cray X-MP/48,来代表各自年代的巅峰。如果时间不是问题,我们就能做到。但时间始终是个物体。我们认为将所有内容与超级计算美学的标志Cray 1A进行比较非常有趣,我们的表格正是如此。
那么,废话不多说,以下是超级计算机与近年来加入的一些人工智能训练系统的历史对比,以增强对比:
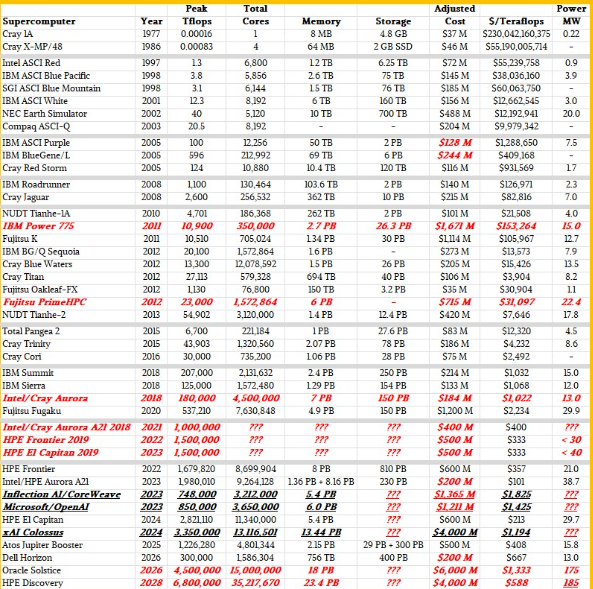
一如既往,粗体红色斜体显示的数据是我们的估计,???表示我们对做出猜测不确定(至少在本文时间限制内不确定)。同样以粗体红色斜体标示了美国能源部资助的前百亿和百亿亿超级计算机的初始预期配置。我们留下了阿贡国家实验室“极光”系统的两个临时架构方案,该系统最初于2018年交付,速度为180千万亿次,2021年则为1千万亿次浮点,但2023年上市时已接近2亿次浮点,价格大幅降低,因为英特尔因极光交付延误严重,对5亿美元订单进行了3亿美元减值进入实地。这导致了一台每FP64兆浮点运算成本极低的机器。
我们还加入了预期中的“Blue Waters”Power 775集群配置,IBM原本计划为伊利诺伊大学制造,但因成本为15亿美元而取消,而非国家超级计算应用中心为Cray公司提供的混合CPU-GPU系统支付的1880亿美元,该系统采用了Blue Waters名称。(按通胀调整,IBM蓝水公司成本为16.7亿美元,而小鱼蓝水公司成本为2.05亿美元。IBM 在许多方面都超越了时代的 GenAI,Power 775 集群设计中采用了液冷和高度集成。)
橡树岭国家实验室的“Frontier”百亿级系统和劳伦斯利弗莫尔国家实验室2019年规划的“El Capitan”系统的粗略配置也被保留在这里,以及它们的原始预算。能源部在这些机器上投入了20%,Frontier性能稍强,一年后安装的El Capitan性能提升了1.9倍。从 IBM 和 Nvidia GPU 转向 AMD CPU,以及从 IBM 和 Nvidia GPU 转变,性价比非常高。英伟达已认真重返高性能计算领域,全球各国政府正在将国家高性能计算实验室重新定位为主权人工智能数据中心。
我们将埃隆·马斯克的xAI公司“Colossus”系统加入名单,该系统在单一系统中集成了10万台英伟达的“Hopper” H100和H200 GPU加速器,作为去年性能和预算的基准。(Colossus今年规模翻倍,据报道该机总投入约70亿美元,部署超过20万块英伟达GPU。)
这份名单上的四台新机器包括德国尤利希研究中心“Jupiter”超级计算机的GPU增强器分区,这是欧洲未来将出现的众多百亿级机器中的第一台。Jupiter由Atos的Eviden部门使用Nvidia CPU和GPU制造,现已运行。
我们还新增了戴尔为德克萨斯先进计算中心制造的“Horizon”机器,这台机器是美国最强大的学术科学专属机器。我们知道Horizon的总预算为4.57亿美元,但这个数字包括帮助Sabey数据中心为高性能计算(HPC)改造数据中心,以及支付空间、电力、冷却和新机器的费用。我们认为其中约2亿美元用于Horizon系统本身,该系统基于基于Nvidia未来“Vera” CV100 Arm服务器CPU的CPU分区和基于Nvidia“Grace” CG100 CPU与“Blackwell” B200 GPU配对的GPU分区。
我们还根据能源部提供的极少信息,尝试了未来阿贡“索尔蒂斯”系统以及橡树岭未来“探索”系统可能的样貌。Oracle是Solstice的主要承包商,该项目将配备10万块英伟达的Blackwell GPU。Discovery基于AMD“Venice”Epyc处理器和“Altair”MI430X GPU,据HPE和AMD称,这些GPU的性能将达到当前Frontier机器的3到5倍。目前尚未公布具体数量的Altair GPU型号,鉴于MI430X矢量发动机FP64的性能为120拍浮点,我们尝试了一下。我们曾读到发现号可能只需5亿美元,而发现号加上基于“Antares+”MI355X GPU的小型系统“Lux”,成本将超过10亿美元。
Solstice及其基于1万台Blackwell GPU的“Equinox”测试平台,以及Discovery及其Lux测试平台收购均未采用正常能源部流程,被描述为“公私合作伙伴关系”的一部分。我们认为能源部的意思是他们正在调试这些机器,但会租用部分——但绝不会全部——这些机器的产能。我们之所以知道这一点很简单。我们的初步猜测是,冬至号的造价是60亿美元,发现号将耗资40亿美元。买两台机器要花100亿美元。能源部科学办公室的预算在2025财年仅为82.4亿美元。和OpenAI一样,美国政府负担不起购买生成式人工智能级超级计算机,必须租赁它们,我们认为价格比拥有它们更为高。目前还没有人具体讨论这个问题,但我们会继续深入挖掘更好的定价数据,并了解如果能源部无法购买全部容量,谁将使用这些机器的剩余容量。
正如你所见,FP64的性能和并发性几十年来大幅提升,但每千万亿次浮点次的成本下降速度并没有像一台能力级超级计算机的价格不断上涨那样快。
按2023年调整后,1977年Cray 1A售价为3680万美元,九年后的1986年Cray X-MP/48售价为4600万美元。1997年的ASCI Red售价为7200万美元。2008年,洛斯阿拉莫斯国家实验室的“Roadrunner”混合CPU加速器系统突破了万亿次浮点放大,2023年造价为1.4亿美元;而基于AMD Opteron处理器和XT5互连的“Jaguar”系统,同样从2008年起,以相对现代的价值计算为215美元。
对于喜欢视觉效果的朋友,这里有一个散点图,X轴显示了万亿次浮点次(teraflops)的性能,Y轴显示系统每峰值万亿次浮点次的成本:
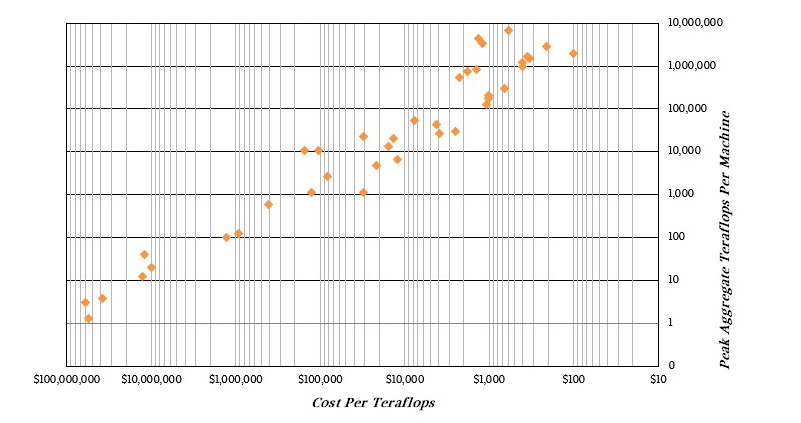
那个一直到每兆浮点100美元的系统是Aurora(交付时),扣除3亿美元成本后,成本为5亿美元。
如你所见,这是一条相当直的向上右侧线,这正是你希望在对数尺度上看到的,以提升超级计算机性能和降低每千万亿次浮次成本。不过,变化很大。
正如我们上面所说,将明年及以后推出的机器与五十年前的Cray 1A进行比较很有趣。Cray 1A与2028年将登陆橡树岭的Discovery系统性能差异为425亿,并发时间增加了352亿。系统成本在1977年至2028年间上涨了108.7倍,前提是我们对Discovery的估算大致准确。
顺便说一句:把这些数字颠倒过来,1997年购买1兆浮点浮点FP64计算需要2300亿美元,而在625万台Cray 1A机器中实现1兆浮点运算是不可能的。(同轴开关不起作用......)
为了更好地理解这些数据,我们制作了第二张表格,展示所有这些机器的性能和性价比,然后与Cray 1A进行比较。下表还显示了FP64精度下2亿美元(2023年美元)能获得多少万亿次浮点次:
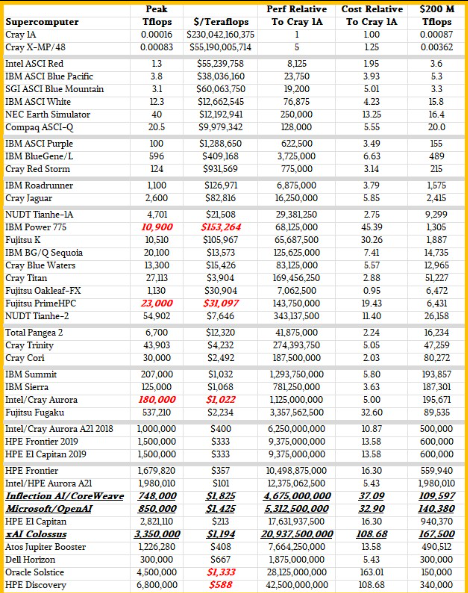
El Capitan为此设定了很高的标准,除非你把极光的折扣票数算进去。展望未来,这2亿美元的预算将大大减少HPC中心在向量上的FP64。所以,他们最好计划更多地使用张量核心,并让算法以混合精度工作。这将是继续前进的唯一途径。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











