




犯错形成恶性循环,但也有良性循环,比如自己从困境中爬出来,不仅不再犯错,还通过良好的工程、努力和一点运气追赶并超越竞争对手。
英特尔在过去十年数据中心挣扎(主要是因为代工部门的失误)对AMD不利,就像AMD在前十年跌倒也没影响一样。由于多种问题,AMD十年前被彻底从bitbarns中彻底击败,不得不像初创公司一样赢得CIO的信任,先是用CPU,现在则凭借GPU以及通过收购Xilinx、Pensando和ZT Systems获得的部分网络协议栈和系统设计。
现在,AMD首席执行官苏淑娟及其核心高管团队表示,AMD已准备好搭乘AI浪潮,获得超过其份额的传统企业计算。
这是本周在纽约为华尔街观众举办的金融分析师日的主要信息。AMD不主办FAD活动,因此它们对于帮助大家同步预期和调整预测非常重要。第一次会议是在2009年举行的,那年英特尔的Xeon系列非常出色,而Opteron系列则不太理想。前首席执行官罗里·里德在2012年公司淡化数据中心业务时曾举办过一次重要会议,但到2015年,苏成为CEO,首席技术官马克·佩珀马斯特公布了AMD的“禅”架构和数据中心的救赎目标。2017、2020、2022 以及现在的 2025 年的 FAD 活动都为这一救赎之路划定了里程碑,现在可以肯定地说,AMD 比宿敌英特尔更可靠地供应高性能 CPU 和 GPU,并且是 GPU 和 DPU 的可信替代品,从明年开始, 针对Rackscale AI系统。
我们已经思考了近五小时的FAD 2025演示,现在很高兴基于AMD高层本周的说法以及我们对英伟达的期待,分享我们自己的模型。
AMD对数据中心总可覆盖市场的外壳更新,以及公司对其CPU和GPU计算引擎相较整体TAM表现的评估——这主要是针对销售给数据中心的硅片,而非由硅片构建的系统或添加的软件,从而真正构建一个可运行的系统。AMD卖芯片并免费赠送软件,所以它只计算CPU、GPU(包括其HBM内存,且转售)、DPU、机架级系统扩展网络,以及扩展网络的DPU。
直到现在,苏氏一直为数据中心AI加速器提供TAM(计量计量)和预测,供您参考,以下是过去两年所有的预测:
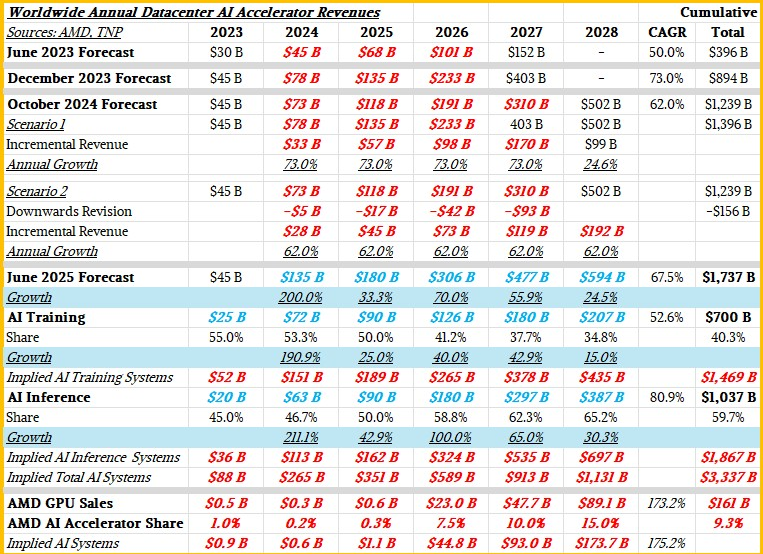
我们在六月时对预测做了很多“巫术”,试图将AI训练硅与AI推理硅分开,然后将这些数据与AI推理和训练系统可能带来的收入相匹配。粗体红色和粗体蓝色斜体数字是The Next Platform为填补空白、进一步认证和量化AMD的TAM模型所做的估算。
这次在FAD 2025上,AMD只是谈论数据中心整体,然后向华尔街展示其CPU和GPU业务的表现。以下是苏氏的新数据中心TAM图表:

“说TAM是什么总是很难,”苏在开场白中承认。“当我们最初开始讨论人工智能TAM时,我记得我们最初是3000亿美元,然后更新到4000亿美元,再到5000亿美元,我想你们很多人都说,'Lisa,这似乎太高了。你为什么会认为这些数字会这么高?”事实证明,就人工智能加速发展而言,我们可能更接近正确而非错误。这实际上是通过与众多客户的大量讨论,了解他们如何看待自己的计算需求。”
这就是AMD,在很大程度上,英伟达都在追求的TAM。(英伟达的规模稍大一些,因为它在数据中心也销售扩展型和跨网络扩展功能。但我们暂且不谈这个。)
“毫无疑问,数据中心是最大的增长机会,AMD在这方面处于非常非常有利的位置,”苏继续说道。“我真正想强调的是,我们的策略一直非常非常一致。我认为在科技领域你必须这样做,因为坦率地说,这些产品周期很长。这些是我们的战略支柱。我们从计算技术领导力开始,这对我们所做的一切至关重要。我们非常专注于数据中心的领导力。而数据中心的领导力包括硅芯片、软件以及与之配套的机架级解决方案。”
苏在演讲中表示,AMD的数据中心AI收入在未来三到五年内将实现超过80%的复合年增长率(CAGR),并且同期公司可能拥有超过50%的服务器CPU收入份额,超过40%的客户端CPU收入份额。 以及超过70%的FPGA收入份额。她补充说,AMD数据中心部门在未来三到五年内将以超过60%的复合年增长率增长,核心客户、嵌入式、定制和FPGA业务同期将实现10%的复合年增长率,推动AMD整体收入复合年增长率超过35%。最后,苏表示,AMD预计2025年收入约为340亿美元,其中约160亿美元来自数据中心部门;我们预计今年它将在Instinct数据中心GPU销售额上达到约62亿美元,Epyc服务器CPU销售额约93亿美元,另外还有少量用于DPU和FPGA销售。
在把这些都输入神奇的电子表格之前,先聊聊复合年增长率(CAGR)。CAGR的原理是取数据集的任意两个端点,在该数据集上画一条直线,然后计算这条直线的斜率。它是一个非常粗糙的工具,完全忽视了任何市场中自然会出现的起伏。特别是在人工智能领域,我们认为——顺便说一句,苏也持相同观点——未来几年的增长将高于TAM模型后期。我们也认为2026年、2027年和2030年将是人工智能市场整体增长良好的年份。我们的模型也反映了这一点。
那么,废话不多说,这里是AMD型号,顺便说一句,我们还插入了Nvidia数据中心的日历销售数据。(请记住,英伟达的财政年度在1月结束,因此你需要将N、N-1和N-2财年的1月收入减去N-1财年的收入,再将N-2财年的1月收入加到N-1财年,才能得到当日历年的预估收入。)看看:
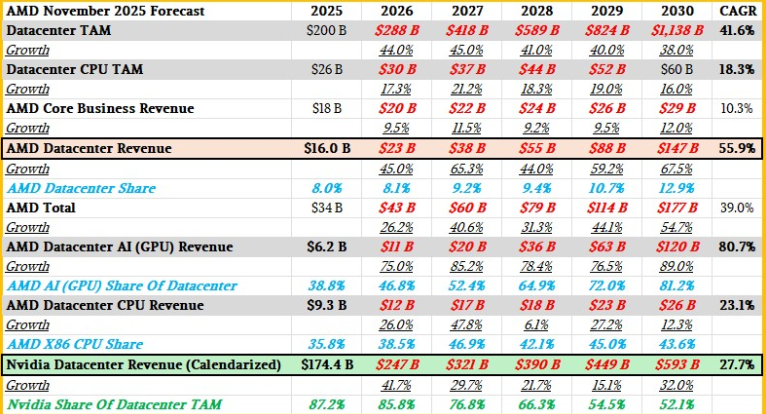
一些观察。从数学上讲,似乎不可能让AMD数据中心收入以60%的复合年增长率增长,同时AMD总收入增长速度远快于35%的复合年增长率,同时又要将核心AMD业务(PC、嵌入式和FPGA)的复合年增长率保持在10%。我们的模型试图平衡这一点,同时保持数据中心AI收入机会在预测结束时超过1000亿美元。
让我们先聊聊CPU业务,同时深入分析这张表。首先,AMD计算与企业AI总经理Dan McNamara介绍了未来基于Zen 6和Zen 6c核心的“Venice”Epyc处理器的规格,这些处理器将于2026年发布。
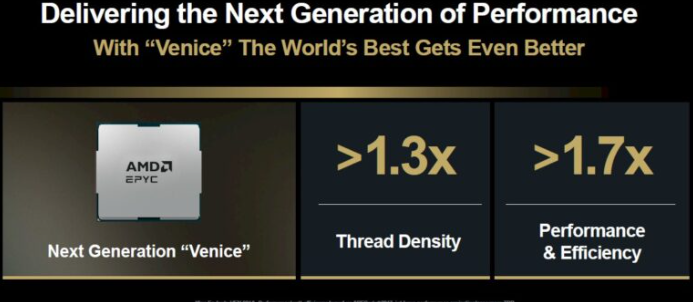
当我们计算“线程密度”语句并以1.33作为乘数时,Zen 6版本有172个核心,Zen 6c半缓存版本有256个核心。Zen 5版本的“Turin”Epyc 9005芯片最高为128核,Zen 5c版本则有192核心。
McNamara还介绍了另一张有趣的图表,那就是由于由GPU驱动的生成式AI工作负载,服务器CPU市场的复兴。我们早就说过,如果把AI系统排除在外,通用服务器市场正处于衰退状态,正如你从下面的数据中看到的,情况确实如此:
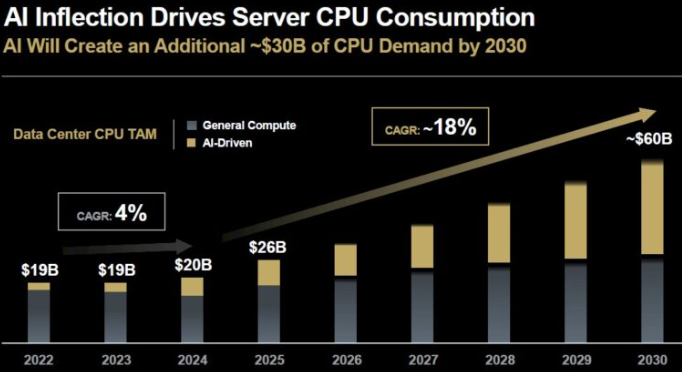
只有高端AI系统服务器CPU销售使市场从2022年到2023年保持平稳,实际上2024年通用服务器收入下降更快,但这得益于AI系统CPU销售。(我们认为同样的总体趋势也反映在系统收入层面,甚至因每台GPU销量增加及其更高成本而被放大。)
今年,得益于需要升级和整合工作负载以提升效率的老旧机器群,从而释放了电力、空间和预算给AI系统,通用服务器市场(及其CPU子集)再次崛起,AMD预计增长将持续到2030年。但预计AI服务器CPU市场的份额将从2025年的约82亿美元增长到2030年的约300亿美元,按服务器CPU标准来说这是一个巨大的激增。
关键是,AI工作负载需要大量串行处理,而它们需要快速且昂贵的处理器来完成。
在AMD数据中心GPU方面,MI350和MI355X GPU正在逐步升级,但所有目光都集中在明年的MI400系列上,这些系列将接入AMD与Meta Platforms合作打造的“Helios”机架,且不少关注者还在更远的未来展望2027年,届时新一代机架搭载MI500系列GPU。
以下是“Altair”MI450系列的基本规格,我们之所以将其代号命名,是因为AMD拒绝相信其GPU的代号:

虽然在FP4和FP8精度下,flop很重要,但更重要的是HBM4存储器的容量和性能。我们认为这意味着,FP16训练将获得比GPU更高效的内存容量和带宽,而且在FP8和FP4模式下,还将有足够的内存带宽,能够更快处理上下文令牌,输出答案令牌的速度超过了之前甚至现有的Nvidia和AMD显卡。
据我们所知,MI400系列有三个变体,均采用台湾电路制造股份有限公司的2纳米(N2)工艺蚀刻,正如苏斌本周指出的,是全球首批采用该工艺的芯片。MI450 旨在实现八路开放式主板设计,采用由 Microsoft 和 Meta Platform 开发、AMD 和 Intel 目前采用的 OAM 模块(但未被 Nvidia 采用)。上图所示的MI450X集成在Helios机架系统中,AMD则开始推出72块GPU串联在一起的Helios机架(类似Nvidia“Oberon”机架中的NVL72配置),但也有64块GPU和128块GPU的版本。MI455X是高端型号,我们认为它拥有432 GB的HBM4容量——远超今年早些时候讨论的288 GB。
Helios机架在FP8精度下可实现1.45亿次浮点次,FP4精度下为2.9亿次浮点次,配备31TB的HBM4总内存,MI455X的总带宽为1.4 PB/秒。UALink over Ethernet(UALoE)扩展网络作为Nvidia NVSwitch的替代方案,提供260 TB/秒的总带宽,覆盖72块GPU(每块3.6 TB/秒),机架扩展网络带宽为300 GB/秒。
以下是AMD如何比较其Oberon机架中未来Vera-Rubin计算引擎与Helios机架中Venice-Altair计算引擎的比较:
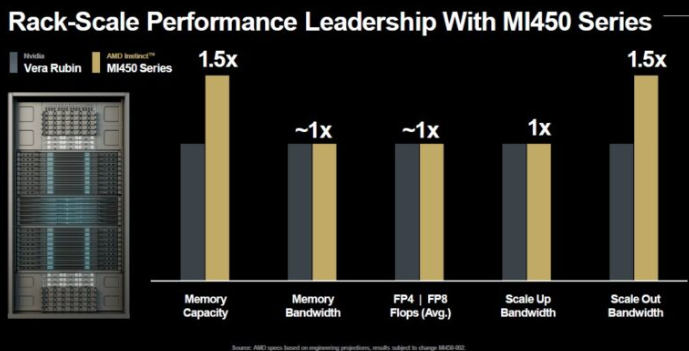
在我们看来,这看起来相当平手......
关于Altair GPU的MI430X变体知之甚少,只知道它面向正在成为国家实验室AI中心的高性能计算中心:

我们强烈预期MI430在单位能源和成本下能拥有更高的64位浮点性能,但AMD如何实现还有待观察。今年早些时候,我们从AMDGPU平台副总裁、IBM Power CPU项目长期经理Brad McCredie那里得到了一些提示。在我们的对话中——Brad McCredie是AMD数据中心GPU金属的踏板——我们建议将芯片组拆分为具有不同浮点精度的计算单元,然后根据需要添加具有FP64/FP32、FP16、FP8和FP6/FP4精度的芯片组,同时在不同的芯片组上保留向量和张量的数学单元。 太。他暗示AMD可能在策划某些事情,但并不具体。
这就引出了最后一个重要图表,AMD机架级GPU系统的近期未来:

除了“Verano”一代Zen 7和Zen 7c处理器外,AMD还将推出MI500系列——我们还未决定代号,因为我们给AMD机会自行决定——同时坚持使用为Helios机架打造的“Vulcano”一代DPU。
AMD对MI500系列GPU没有太多透露,但这里有一个相对的性能路线图:
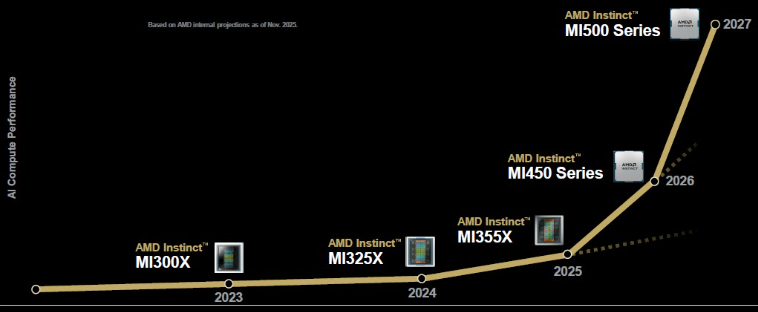
如果按比例绘制,MI500系列的浮点数峰值峰值约为72千万亿次浮点,比MI455X高出80%,比刚开始升级的MI355X高出7.8倍。
公司确实会购买路线图,而不是点点产品,但他们总得买点东西才能完成任何事情。你总是想等待下一代计算引擎完成更多工作,但如果你想完成工作,就不能让买家的后悔阻碍你。AMD、英伟达等公司可以指望这一点——事实证明,这一切都会一直支持。
看看我们上面做的表格里AMD和英伟达的全部资金。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











