




近日,Waymo 发布了一篇深度博客,详细介绍了该公司的 AI 战略以及以 Waymo 基础模型为核心的整体 AI 方法。
谷歌首席科学家 Jeff Dean 也在 X 上分享了这篇博客,并重点介绍了 Waymo 用到的蒸馏方法,他写到:「就像我们使用蒸馏从更大规模的专业模型中创建高质量、计算效率极高的 Gemini Flash 模型一样,Waymo 也类似地使用了蒸馏,来基于更大的模型创建可机载运行的高计算效率模型。」
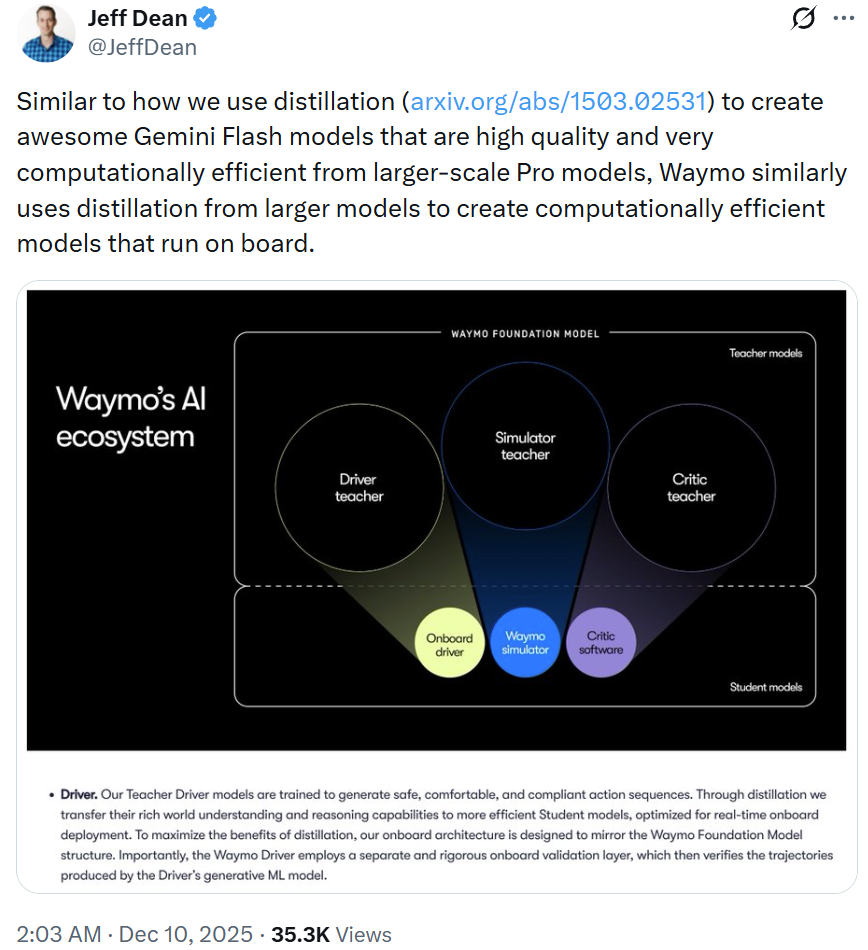
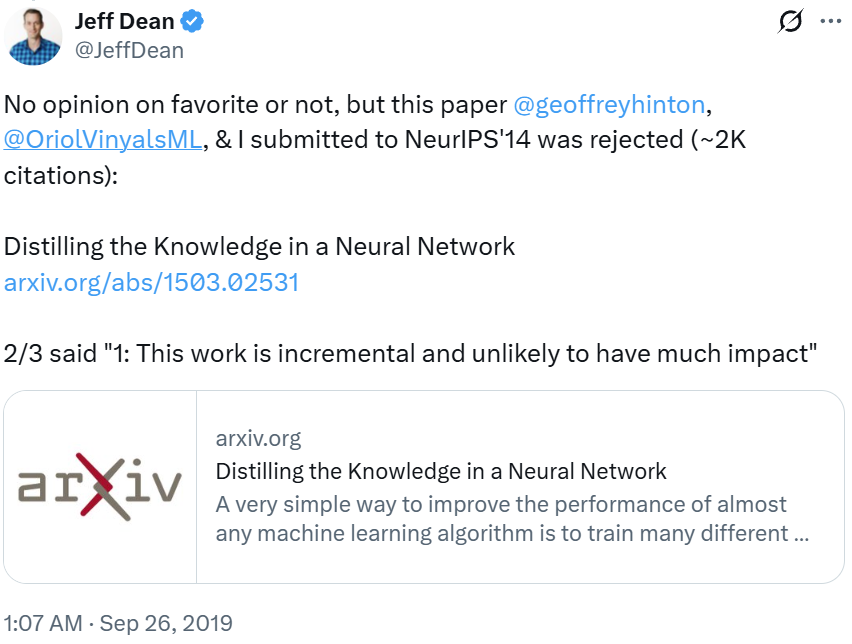
而在这条帖子下方,Jeff Dean 又再一次回忆了最初那篇蒸馏论文的悲惨遭遇:被 NeurIPS 2014 拒收了。而他收到的拒收理由是它「不太可能产生重大影响」。

当时,评审认为这篇由 Geoffrey Hinton、Oriol Vinyals、Jeff Dean 合著的论文只是对早期模型压缩(Model Compression)工作的增量改进。而事后来看,NeurIPS 2014 评审的这个决定可谓是错得非常离谱。如今,「知识蒸馏(Knowledge Distillation)」已然成为模型压缩和大模型落地的标配方法。其论文引用量也已经超过了 2.8 万!

这件事也成了 Jeff Dean 的意难平,让他每有机会就会拿出来晒一晒。
其实 Jeff Dean 的遭遇并非个例。
回顾 AI 的发展历程,同行评审制度虽然扮演着质量守门人的关键角色,但它并非全能。
事实上,当我们回溯历史,会发现一个令人深思的现象:许多当下支撑起万亿级 AI 产业的基石技术(从训练大模型的优化器,到计算机视觉的特征提取,再到自然语言处理的底层逻辑)在最初问世时,都曾被顶级会议拒之门外。
Geoffrey Hinton、Yann LeCun、Schmidhuber…… 这些如雷贯耳的名字,都曾站在拒稿信的对面。那些理由在今天看来甚至或许有些荒谬:「缺乏理论依据」、「只是工程技巧」、「太简单了不可能有效」。
今天,我们盘点一下那些曾经沦为「弃子」、后来却引发范式转移(Paradigm Shift)的殿堂级论文。这不仅是对历史的回顾,更是为了探寻一个问题的答案:当一项研究过于超前或离经叛道时,我们该如何识别它的价值?
LSTM:跨越 20 年的回响

论文:Long Short-Term Memory
作者:Sepp Hochreiter, Jürgen Schmidhuber
拒稿经历:NIPS 1996 Rejected
如今引用量:139707
作为处理序列数据的里程碑,LSTM 在 1996 年被 NIPS 拒之门外。
当时正值神经网络的寒冬(AI Winter),支持向量机(SVM)等统计方法大行其道。LSTM 引入的门控机制被认为参数过多、过于复杂且缺乏生物学合理性。
直到 2010 年代,随着算力和大数据的爆发,LSTM 才在语音识别和机器翻译中展现出统治级表现。这不仅是技术的胜利,更是对坚持者的奖赏。
SIFT:前深度学习时代的王者

论文:Object Recognition from Local Scale-Invariant Features
作者:David G. Lowe
拒稿经历:ICCV 1997, CVPR 1998 Rejected
如今引用量:27389
David Lowe 提出的 SIFT(尺度不变特征变换)算法,曾统治 CV 领域长达 15 年。但在 1997 年和 1998 年,它先后被 ICCV 和 CVPR 拒稿。
拒稿理由很有时代特色。当时的学术界偏好基于几何理论和严密数学推导的方法。SIFT 包含了一系列复杂的工程步骤(高斯差分金字塔、关键点定位等),被评审认为「过于繁琐」、「不够优雅」。
SIFT 最终以 Poster 形式发表。它证明了在处理现实世界图像的旋转、缩放和遮挡问题时,鲁棒的工程设计往往比完美的数学理论更有生命力。
Dropout:被误解的「有性繁殖」

论文:Dropout: A Simple Way to Prevent Neural Networks from Overfitting
作者:Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov
拒稿经历:NIPS 2012 Rejected
如今引用量:60231
如果说有一项技术定义了深度神经网络的正则化方法,那非 Dropout 莫属。然而,这项后来获得 NeurIPS 时间检验奖(Test of Time Award) 的技术,在 2012 年投稿 NIPS 时却遭遇了滑铁卢。
在这篇论文中,Geoffrey Hinton 团队提出的核心思想是在训练中随机「删掉」一半神经元,而这在当时的评审看来过于激进且缺乏数理逻辑。Hinton 使用了生物学中「有性繁殖」的隐喻来解释其有效性(基因不能依赖于特定的伙伴存在),这被一些严谨的评审人认为「不够科学」,更像是一个工程 Hack。
尽管被拒,Dropout 迅速成为了 AlexNet 夺冠 ImageNet 的秘密武器。它证明了在过参数化的深度网络中,通过引入随机性来打破特征间的共适应(Co-adaptation),比复杂的贝叶斯正则化更为有效。
Word2Vec:被质疑的「工程奇迹」

论文:Efficient Estimation of Word Representations in Vector Space
作者:Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
拒稿经历:ICLR 2013 Strong Reject
如今引用量:50855
是的,这里又出现了 Jeff Dean 的名字。
Word2Vec 让 King - Man + Woman = Queen 成为了 AI 领域最著名的算式,但在首届 ICLR 会议上,它收到了「Strong Reject」。
其收到的评审意见极其尖锐,认为作者 Tomas Mikolov 等人「比较不科学」、「定义模糊」,且过度关注工程优化(如分层 Softmax、负采样),缺乏对「为何简单的线性映射能捕捉复杂语义」的理论解释。
而作者直接开源了代码。凭借极高的训练效率,Word2Vec 迅速横扫 NLP 社区,成为深度学习时代文本表示的基石。2023 年,NeurIPS 授予这篇曾被拒稿的论文「时间检验奖」,完成了历史性的「平反」。

知识蒸馏:被低估的「暗知识」

论文:Distilling the Knowledge in a Neural Network
作者:Geoffrey Hinton, Oriol Vinyals, Jeff Dean
拒稿经历:NIPS 2014 Rejected
如今引用量:28600
这正是前文提到的论文。
在当时,评审未能洞察到 Hinton 提出的 「暗知识」(Dark Knowledge) 这一概念的深远意义:神经网络学到的知识不仅存在于正确的预测中,更隐含在对错误类别的概率分布里(比如宝马像垃圾车的概率远高于像胡萝卜的概率)。

https://www.ttic.edu/dl/dark14.pdf
这篇论文最终仅在 Workshop 发表。它开启了模型压缩作为独立研究领域的序幕,更成为了如今大模型向小模型迁移能力的理论源头。
YOLO:速度与精度的偏见

论文:You Only Look Once: Unified, Real-Time Object Detection
作者:Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
拒稿经历:ICCV 2015 Rejected
如今引用量:69782
YOLO(You Only Look Once)彻底改变了物体检测的游戏规则,将检测问题从分类问题转化为回归问题。
其被拒理由也很简单。在 R-CNN 系列(双阶段检测器)统治的时代,评审们习惯了用 mAP(平均精度均值)的微小提升来衡量价值。YOLO 虽然实现了惊人的 45 FPS 实时检测,但其定位精度确实不如 R-CNN。评审因其「定位不准」而拒绝了它,却忽视了数量级的速度提升所开启的全新应用场景(如自动驾驶、实时监控)。
YOLO 系列如今已迭代至 v13,成为工业界最受欢迎的检测框架。它提醒我们:在工程应用中,速度本身就是一种精度。
RoBERTa:被嘲讽为「炒冷饭」的调参艺术

RoBERTa: A Robustly Optimized BERT Pretraining Approach
作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
拒稿经历:ICLR 2020 Rejected
如今引用量:23479
如果说前面的论文是因为「太超前」被拒,那么 RoBERTa 的被拒则是因为「看起来太平庸」。
2019 年,BERT 横空出世,风头无两。Facebook AI(现 Meta AI)的研究人员并没有急于提出一种全新的架构,而是耐心地对 BERT 的预训练过程进行了极其详尽的复现和优化。他们发现,BERT 实际上被「训练不足」了。通过调整超参数、增加数据量、去除 Next Sentence Prediction (NSP) 任务,RoBERTa 在所有基准测试上都超越了原始 BERT。
然而,这篇扎实的工作在投稿 ICLR 2020 时,却遭到了评审的冷遇。评审意见非常直白且刺耳:「这篇论文的新颖性和技术贡献相当有限」。在评审看来,只是发现「仔细调参很有用」和「更多数据很有用」,并不足以登上顶会的舞台。
最终,RoBERTa 只能再次以被拒稿的身份流传于世。但历史证明了它的价值:RoBERTa 不仅成为了后续 NLP 研究的标准基线,更向业界揭示了一个朴素的真理 —— 在深度学习时代,清洗数据和优化训练细节,往往比设计花哨的新架构更具实战价值。
Mamba:挑战 Transformer 霸权的「落选者」

论文:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
作者:Albert Gu, Tri Dao



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











