





该项工作的作者分别是来自香港中文大学的博士生施柯煊,来自西湖大学的助理教授温研东,来自香港中文大学的计算机系助理教授刘威杨。
当前,基于通用基础模型进行任务特定微调已成为主流范式。这种范式虽然能够在各个特定任务上获得高性能的专家模型,但也带来新的挑战:如何将这些特定微调得到的专家模型的能力有效整合到单一模型中并且无需访问原始训练数据,实现多任务协通,同时最小化性能损失?
针对这一问题,研究者们提出了 FDA(Model Merging with Functional Dual Anchors)——一个全新的模型融合框架。与传统的参数空间操作不同,FDA 将专家模型的参数知识投射到输入-表征空间中的合成锚点,通过功能对偶的方式实现更高效的知识整合。

Title:Model Merging with Functional Dual Anchors
Arxiv:https://arxiv.org/pdf/2510.21223
Project page:https://spherelab.ai/fda/
FDA 的关键思想是:将参数中所蕴藏的任务知识,用输入空间的一组对偶的合成输入点(Dual Anchors)来表示;使用合成输入点所诱导的联合梯度,更新模型,以整合多任务知识。
具体来说,任务知识在参数空间上可以体现为模型最终的参数与初始参数的差异向量(任务向量,Task Vector)。FDA 为每一个专家模型,构造一组 Dual Anchors,使其能够在初始参数处诱导出与任务向量近似的梯度方向。相似的梯度方向,可以让 FDA 近似地模拟任务知识对预训练模型的函数偏移。
相比于任务向量将任务知识编码在参数空间,FDA 则通过诱导相似梯度在输入空间编码对应的任务知识。因此,FDA 相对于任务向量而言,是一组在函数功能上对偶的输入点。
FDA 将知识的整合过程,从参数空间迁移至输入空间。相比于先前的基于任务向量算术操作的框架,FDA 为当下的 Model Merging 问题提供了一种新的视角。为了兼顾性能与实用性,研究者还开发了基于分层策略的算法来部署 FDA 框架,使其可以扩展至超大规模的神经网络模型。实验结果表明,该方法在视觉、自然语言模型上表现出卓越的性能和可扩展性。
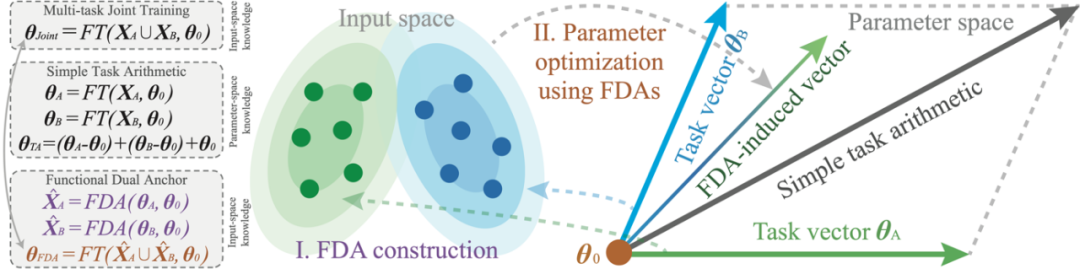 图 1:FDA 框架的示意图。
图 1:FDA 框架的示意图。FDA 框架的直觉理解与动机
当前的主流 Model Merging 方法,本质是基于任务向量的算术操作,即对不同的任务向量进行线性组合,然后加至预训练参数,以获得一个多任务模型。因此,任务向量的算术操作,只能产生固定的合并路径;然而,FDA 方法则提供了一个可以根据融合过程中的损失函数景观诱导新合并路径的机会。研究者们将获得的 FDA 视作微调数据,逐步优化预训练模型的参数。
如下图所示,使用 FDA 进行优化时,模型会逐步靠近在八个下游数据集上计算得到的损失函数局部最小值(local minima)区域。相比之下,任务向量(task vectors)虽然能够在一定程度上提供来自预训练模型的优化方向,但它们往往会迅速偏离原本的损失盆地;而 FDA 则能够持续地引导优化过程朝向更有利的区域。FDA 的这一优势类比于联合多任务训练的灵活性。
FDA 的另一项核心动机在于:对输入空间进行建模通常比对参数空间建模更容易,因为输入空间往往具有更强的结构性(structured)。在知识迁移(knowledge transfer)的研究中,基于输入空间建模的有效性已被广泛探讨并通过大量实证验证。例如,在数据集蒸馏 [1, 2, 5, 6]、迭代式教学 [3, 4] 以及持续学习 [7, 8] 等领域的研究中,都充分展示了输入空间建模在促进知识高效迁移与压缩方面的强大潜力。
FDA 提供更灵活和鲁棒的融合路径
为验证 FDA 的有效性,研究者们将 FDA 用于对多种不同尺寸的预训练模型(80M、125M、400M、13B)进行适配,并将其多任务性能与对应的对偶框架(即任务向量方法,Task Vectors, TA)进行比较。为进一步验证其鲁棒性,研究者们在实验中将预训练模型初始化为通过无数据(data-free)任务向量方法融合得到的参数。研究者们共考虑了三种无数据融合方法:TA [9]、TSVM [10] 和 WUDI [11]。其中,TA 是经典方法,而 TSVM 与 WUDI 则代表当前的 SOTA 方法。部分实验结果如上表所示,更多结果可参考论文正文。
 图 2:FDA 的部分实验的结果。
图 2:FDA 的部分实验的结果。从结果中,研究者们得到两个关键观察结论:
观察 1:FDA 能够更有效利用模型编码的知识,实现高效的多任务模型融合:
与对偶框架 TA 相比,FDA 带来了显著的性能提升。使用 FDA 适配后的预训练模型在多任务场景下的平均性能达到 87.26,而 TA 方法仅为 73.94,提升幅度接近 18%;与此同时,平均 GLUE 分数也提升了 15.4%。
观察 2:FDA 具备灵活的知识建模能力:
尽管 FDA 与其他无数据、以参数为中心的方法(如 TA、TSVM、WUDI)使用了相同的任务特定知识,FDA 仍能在此基础上进一步提升融合模型的性能。在 ViT-B/16 上,FDA 的平均提升约为 5.10%,而在 RoBERTa-Large 上则达到约 13%,展示出其在不同架构下的通用性与强大适配能力。
FDA 算法实现
FDA 的实际算法流程主要包括两个阶段:FDA 的构建(Construction)和基于 FDA 的参数更新(Adaptation)。
阶段一:针对每一个下游任务的微调模型(checkpoint)构建其对应的 FDA。具体来说,给定预训练模型以及对应的微调模型
研究者们通过求解以下优化问题构造 FDA 的样本集合 
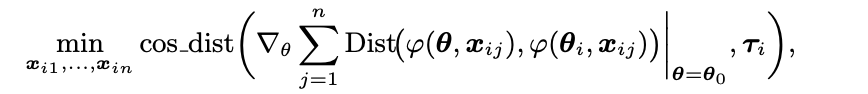
其中,

为可微分的表示差异度量函数。该优化问题采用基于梯度的迭代优化方法求解。由于梯度优化过程对初始化敏感,
为矩阵的向量化操作;
表示梯度方向的余弦距离;
研究者们分析了线性编码器(linear encoder)下 Dual Anchors 的优化动态,并提出以下原则:
有效的初始化策略应当将初始点的能量限制在由任务向量(task vector)所张成的尾部子空间(tail subspace)。
研究者们进而导出两种实用的初始化方案:线性权重采样(Linear weight sampling)和缩放高斯采样(Scaled Gaussian sampling),来进行初始化。
阶段二:该阶段利用阶段 1 构造得到的 FDA 对参数进行更新。具体来说,是阶段一的对偶过程。当初始参数本身为预训练参数时,研究者们直接用 FDA 对参数进行更新:
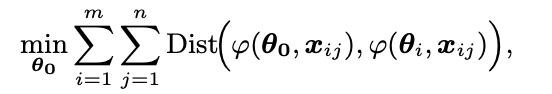
当初始参数初始化为基于任务向量方法的融合参数时,目标转变为对任务向量的调节:
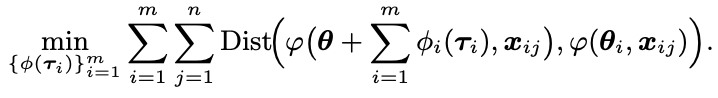
研究者们将具体的算法流程整理成如下伪代码:
 图 3:FDA 具体算法的伪代码。
图 3:FDA 具体算法的伪代码。FDA 所编码的任务知识
得益于 FDA 优越的性能,研究者们进一步探索 FDA 中编码知识的过程。研究者们通过系统的实证分析来揭示 FDA 背后潜在的机制:
观察一:在优化过程中,FDA 倾向于长尾结构。研究者们对 FDA 矩阵进行奇异值分解发现(图 4):无论采用何种初始化方式,在构建过程中归一化后的尾部奇异值均快速衰减。这表明:
FDA 有效捕捉了任务相关的主导表示方向;
自动抑制了冗余或噪声成分;
与任务特定知识在参数空间通常表现为低秩结构的观察一致。

观察二:在优化过程中,FDA 的高能量子空间逐渐与真实数据的高能量子空间对齐。鉴于 FDA 具有长尾结构(long-tailed structure),研究者们进一步通过投影矩阵(Projection Matrix)来衡量真实数据与 FDA 之间前若干主奇异向量(top singular vectors)子空间的相似性。
从图 5 的示例可以看到,随着优化过程的进行,这种相似性逐渐提高。这一结果表明,FDA 中所编码的知识与真实任务数据之间存在潜在的关联——即在优化过程中,FDA 逐步对齐了由真实数据所定义的任务相关子空间,从而在功能层面有效捕获了任务知识的本质结构。

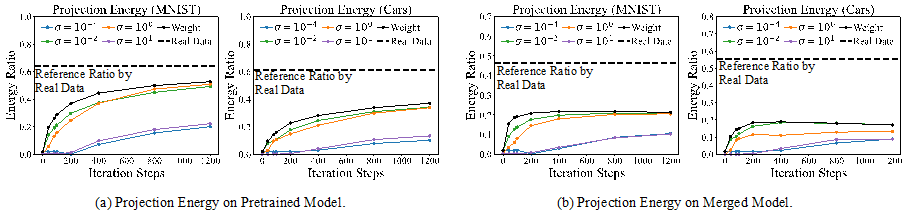
观察三:在优化过程中,FDA 所诱导的参数更新与真实数据所诱导的更新逐渐对齐。研究者们进一步从参数空间(parameter space)的角度分析 FDA 的性质,即考察其在模型参数上的诱导更新。具体而言,研究者们将这种由 FDA 引发的参数变化投影到由真实数据产生的参数更新向量所张成的非负锥空间(non-negative cone)中。
如图 6 所示,无论是在预训练模型还是融合模型中,投影能量(projection energy)都随着优化过程逐步上升。这一结果表明,FDA 在训练过程中不断产生稳定且具有方向性的任务特定功能偏移(task-specific functional shifts),即 FDA 的适配动态与真实任务学习过程在功能空间上形成一致性,从而体现出其在捕捉任务相关知识方面的稳健性与有效性。
更为详尽的讨论与实证结果见论文附录。
参考文献
[1] Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A Efros. Dataset distillation.
[2] George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories.
[3] Weiyang Liu, Bo Dai, Ahmad Humayun, Charlene Tay, Chen Yu, Linda B Smith, James M Rehg, and Le Song. Iterative machine teaching.
[4] Zeju Qiu, Weiyang Liu, Tim Z Xiao, Zhen Liu, Umang Bhatt, Yucen Luo, Adrian Weller, and Bernhard Sch¨olkopf. Iterative teaching by data hallucination.
[5] Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching.
[6] Bo Zhao and Hakan Bilen. Dataset condensation with distribution matching.
[7] Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay.
[8] Longhui Yu, Tianyang Hu, Lanqing Hong, Zhen Liu, Adrian Weller, and Weiyang Liu. Continual learning by modeling intra-class variation.
[9] Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.
[10] Antonio Andrea Gargiulo, Donato Crisostomi, Maria Sofia Bucarelli, Simone Scardapane, Fabrizio Silvestri, and Emanuele Rodola. Task singular vectors: Reducing task interference in model merging.
[11] Runxi Cheng, Feng Xiong, Yongxian Wei, Wanyun Zhu, and Chun Yuan. Whoever started the interference should end it: Guiding data-free model merging via task vectors.



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











