




线性循环模型(如 Mamba)和线性注意力机制都具备这样一个显著优势:它们能够处理极长的序列,这一能力对长上下文推理任务至关重要。
事实上,这正是它们相较于 Transformer 的关键优势 —— 后者受限于有限的上下文窗口,且在序列长度上的计算复杂度是二次的,成为性能瓶颈。
过去,循环模型面临的主要问题是性能不足:在处理短序列时,它们的表现往往不如 Transformer。然而,随着架构上的一系列突破,循环模型的性能已经显著提升,在许多任务中已能与 Transformer 媲美,甚至已经被应用于多个工业场景中,如音频建模和代码补全等。
但近期的多项研究发现,循环模型仍存在一个关键短板:尽管它们在训练长度范围内表现良好,但在处理超出训练长度的序列时,往往难以泛化,表现明显下降。
事实也确实如此,举例来说,下图为 Mamba-2 检查点在不同序列位置上的性能变化(以困惑度 Perplexity 衡量,数值越低代表性能越好)。可以明显看到,一旦序列位置超出了训练上下文范围,这些模型几乎就变得毫无作用:它们无法实现长度泛化。
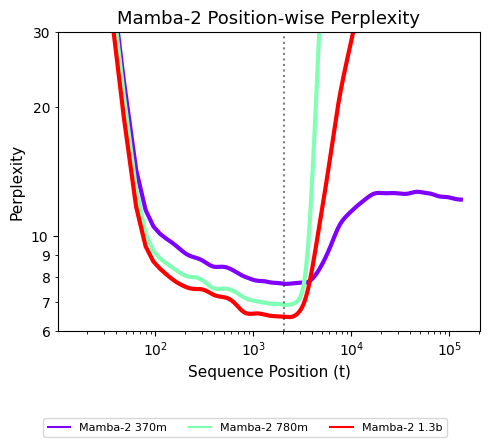
这就带来一个问题:现有的循环模型在长序列上表现较差,而在短序列上相比 Transformer 也没有明显的效率优势;换句话说,它们在两个维度上似乎都显得不够理想。
那这是否意味着循环模型就毫无用处了呢?
当然不是!
本文,来自 CMU、 Cartesia AI 的研究者证明了通过简单的训练干预,循环模型是完全可以实现长度泛化的。只需 500 步后训练(约占预训练预算的 0.1%),就能让模型在高达 256k 长度的序列上实现泛化!
因此,循环模型并不是存在根本性缺陷,而是拥有尚未被充分释放的潜力。
值得一提的是,Mamba 作者之一 Albert Gu 也参与了这项研究。2023 年他和 Karan Goel、Chris Ré、Arjun Desai、Brandon Yang 共同创立了 Cartesia 。公司的使命就是「构建具有长记忆能力的实时智能,无论你身在何处都能运行」,也和这篇文章的主题不谋而合。

论文地址:https://arxiv.org/pdf/2507.02782
博客地址:https://goombalab.github.io/blog/2025/improving-length-generalization/
论文标题: Understanding and Improving Length Generalization in Recurrent Models
为什么循环模型不能进行长度泛化?
对于一个包含 t 个元素的输入序列
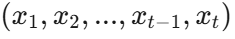
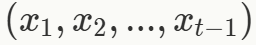
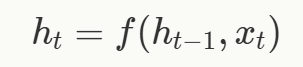
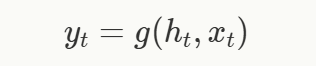
。同样地,时间 t 时的输出仅依赖于状态 h_t 和当前输入 x_t,即对于某个其他函数 g,输出 y_t 可以表示为:
,在时间 t=0 时,状态用某个值 h_(−1) 初始化,然后在每个时间步 t 通过更新函数 f 进行更新:
压缩成一个固定大小的循环状态
,循环模型将输入上下文
函数 f 和 g 不依赖于位置 t,因此理论上循环模型可以自然地处理任何序列长度。但是,当 t 很大时,它们为什么会失败呢?
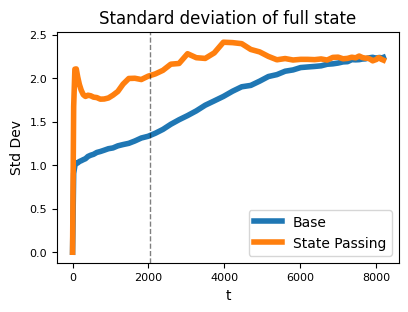
本文展示了状态 h_t 的分布会随时间的变化。因此,即使 g 和 f 在某个 T 之前工作正常,其他 t>T 的 h_t 可能会有显著不同,从而导致模型无法产生正确的输出。实际上,下图展示了 Mamba-2 的状态范数随时间显著增加:
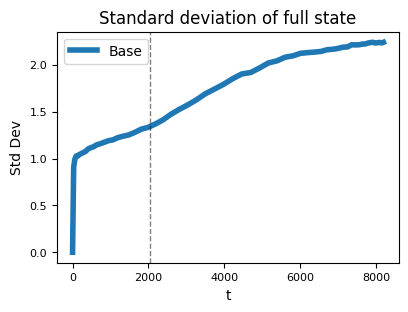
这就解释了为什么循环模型无法实现长度泛化:当处理超过训练长度的序列时,模型会遇到在训练过程中从未接触过的状态 h_t,因此模型并没有学会如何处理这些状态。
基于这一观察,本文提出了一个新的解释框架 —— 未探索状态假说(unexplored states hypothesis),用于说明循环模型在长度泛化上失败的根本原因。
未探索状态假说(Unexplored States Hypothesis)
当循环模型只在所有可能状态分布的一个子集上进行训练时,它们就难以实现长度泛化 —— 也就是说,模型只学习了在有限训练步数内可能出现的状态,而未曾接触那些在无限时间展开状态递推后可能出现的状态分布。
当训练时间足够长时,模型会过拟合于这一有限状态子集,从而在处理更长序列时表现不佳,因为它们会遭遇未被探索过的状态分布,从而导致性能下降。
训练干预,使长度泛化
未探索状态假说指出:要实现长度泛化,并不需要改变模型的架构或机制,而是应该让模型在训练阶段接触到更加多样的状态分布 —— 尤其是那些在长序列状态递推过程中自然产生的分布。
为此,最直接的方法是让模型直接在更长的序列上进行训练,但这在实际中往往不可行,原因包括:
GPU 显存限制;
缺乏足够长的训练数据。
因此,我们需要寻找更高效的训练方法来覆盖这些状态分布,从而提升模型的长度泛化能力。
实现长度泛化的方法是:对初始状态进行干预。
一般而言,现代模型架构假设初始状态为 h_(-1)=0,本文考虑了对初始状态 h_(-1) 的四种简单干预。这四种训练干预措施可以看作是从四种不同的分布中采样初始状态 h_(-1) :
随机噪声(Random Noise):将模型状态初始化为独立同分布(IID)高斯噪声,均值为 0,标准差为常数。所有层和注意力头使用相同的均值和标准差。
拟合噪声(Fitted Noise):在训练过程中,记录所有层和注意力头上,序列最终状态的均值和标准差。然后使用与这些统计量相匹配的 IID 高斯分布来初始化状态,即为每一层和每一个头分别设置不同的均值和标准差。
状态传递(State Passing,SP):使用先前(不相关)序列的最终状态作为初始状态。这些最终状态是通过在给定序列上应用状态递归获得的,得到 h_T 并将其用作另一个序列的 h_(-1)。这类似于验证过程中发生的情况:模型不会在 T 停止,而是继续滚动状态并从 h_T 生成输出。
TBTT(Truncated Backpropagation Through Time): 将一条长序列划分为多个较小的片段,并将每个片段的最终状态作为下一个片段的初始状态。这等价于处理整条完整序列,但在片段之间停止梯度的反向传播。
下图展示了 Mamba-2 模型经过 500 步(约预训练总步数的 0.1%)后训练后,在不同干预措施下的结果:
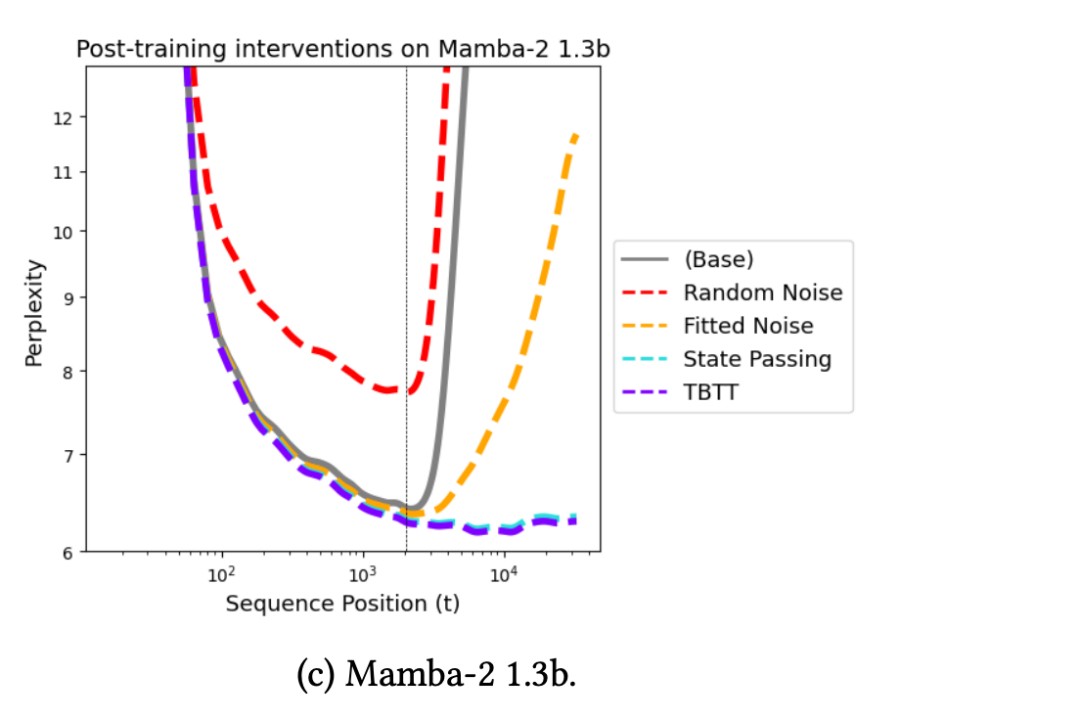
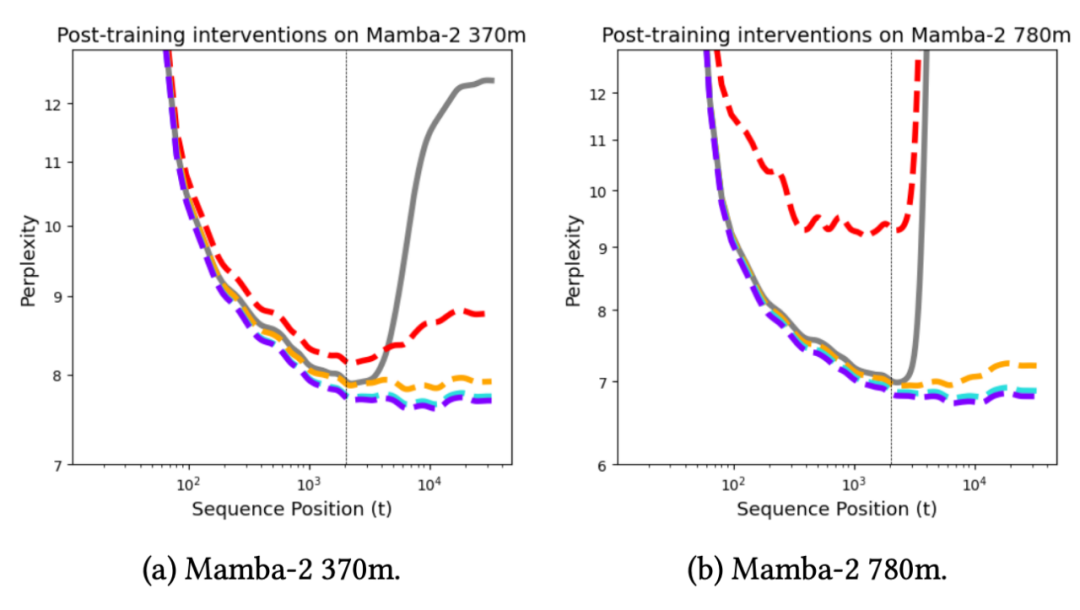
核心发现 1:SP 与 TBTT 机制可实现长度泛化。
SP 和 TBTT 这两种干预方法,能使模型在远超训练序列长度的情况下实现泛化。由此可见:长度泛化有望通过简单的训练干预在循环模型中容易实现。
请注意,结果只达到了原始预训练预算的 0.02% !
核心发现 2:循环模型状态的性质,可以通过观察干预的表现来推断循环模型状态分布的性质。
在 370M 参数规模的模型中,随机噪声干预未能实现长度泛化,而拟合噪声则有效。这表明,对于 370M 模型来说,模型可达状态的分布无法通过具有固定方差的高斯分布来近似,但可以通过在每一层和每个注意力头中使用拟合方差的 IID 高斯分布来近似。
然而,拟合噪声在 1.3B 模型中未能成功实现长度泛化,这说明大模型的状态在其元素之间可能存在更复杂的依赖关系,因此无法再用简单的 IID 分布来建模。
此外,这些干预方法还能解决此前展示的状态范数随时间增长的问题,使模型在所有时间步输出的状态保持相近的范数,从而提升整体稳定性。
长上下文任务的表现
本文观察到,这些干预措施能够实现长度鲁棒性(即在训练上下文长度 T 后,性能不会下降),但尚不清楚它们是否能实现长度泛化(即解决需要利用距离超过 T 个位置的 token 之间关系的任务)。
可能会有疑问,干预措施是否只是简单地通过阻止模型在训练上下文长度之外进行推理来实现长度鲁棒性 ?
这类似于滑动窗口注意力,无法推理超过滑动窗口的 token,模型在所有评估 t > T 的上下文中会保持恒定性能,但无法解决需要长上下文推理的任务。
在本文的工作中,通过在三个长上下文任务上的实验结果,展示了这些干预措施确实能够实现长度泛化。
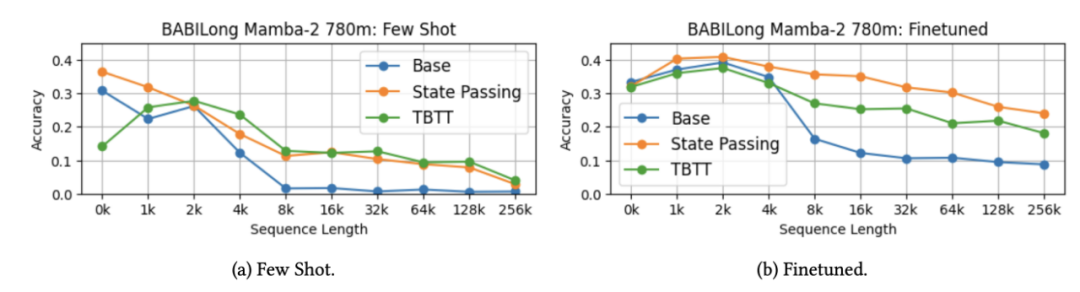
BABILong
BABILong 是一个具有挑战性的基准测试,它考察了模型的常识理解能力以及捕捉文本中长程依赖关系的能力。
从下图可以观察到,状态传递(State Passing)在少样本和微调设置下都增强了模型的长度泛化能力(模型是在长度为 2048 的序列上进行训练和微调的)。
因此,状态传递不仅有助于解决已建立语言模型的困惑度发散问题,还能增强它们解决长上下文推理任务的能力。
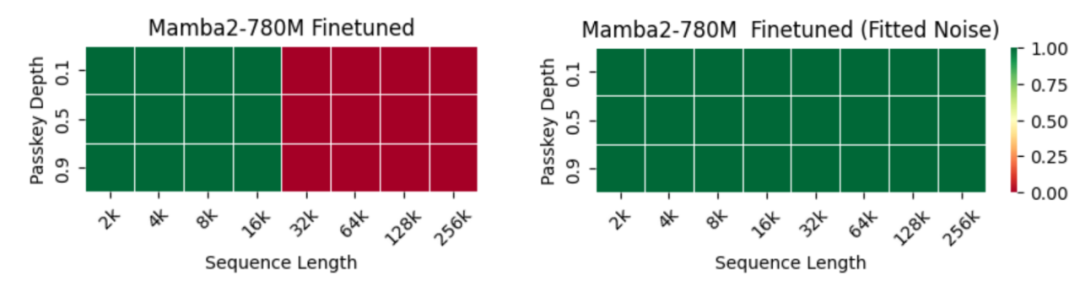
密码检索任务
密码检索任务要求模型在长上下文中的给定深度处检索一个 5 位数字的密码。
下图展示了 Mamba-2 370M 和 780M 官方检查点在三种设置下的表现:零样本、常规微调和使用拟合噪声进行微调。经过拟合噪声微调的模型能够利用超过 2048 个位置(训练上下文长度)之间的 token 关系。特别地,780M 模型能够完美地解决长度为 256k 的序列中的密码检索任务。
合成复制任务
合成复制任务要求模型复制一个任意的 token 序列。
下表展示了在训练过程中使用状态传递显著提高了模型在长度超过三倍的序列中的验证表现。因此,状态传递帮助模型实现长度泛化,解决了比训练过程中遇到的任务更为复杂的长上下文任务。

深入探讨循环模型如何处理上下文
本文已经展示了对初始状态的干预能够实现长度鲁棒性,并使模型能够解决长上下文任务。在这些发现的基础上,本文提出一个度量标准,帮助我们深入了解序列模型是如何处理上下文的。
理想情况下,在文本建模中,希望模型能够关注最近的上下文,而不是过多地关注那些距离过远的 token。那么,该如何量化这种行为呢?
本文引入了「有效记忆(Effective Remembrance)」来衡量一个自回归模型在多大程度上有效地记住了先前的 token。用
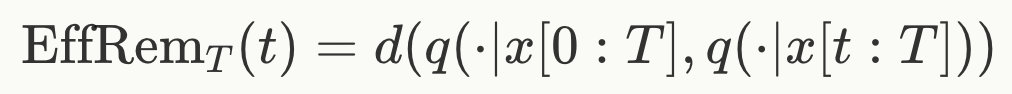
其中
,这意味着使用 x [0:T] 和 x [t:T] 进行预测的结果相同,即模型没有有效记住任何过去的 token。
是概率分布之间的距离度量。该度量大致衡量了模型在时间 T 时刻有效记住过去的 token x [0:t−1]。如果
表示在给定上下文的情况下,自回归序列模型为下一个 token 输出的概率。然后,定义
相反,如果
较高,则表示模型受到过去 token 的显著影响,因为从上下文中移除它们会显著改变预测结果。
下图展示了对于两个官方的 Mamba-2 检查点(它们无法进行长度泛化),在不同的 t 和 T=8192(训练上下文的四倍)下的
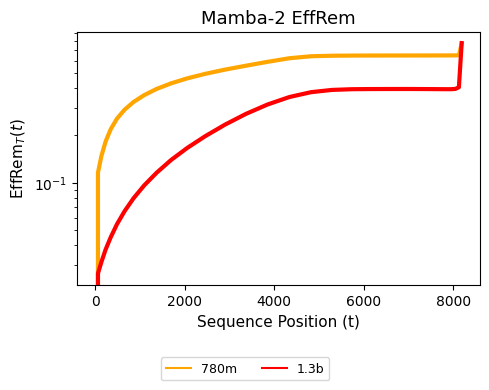
尽管每个 token 都会对模型的输出产生影响,但从直觉上我们会期望最近的 token 应该具有显著更强的影响力。
然而,注意到 EffRem 曲线在立即上升后逐渐平缓下去。这种情况显然是有问题的:在 T=8192 时,下一 token 的预测不应该因为模型是只看到最近的 token 还是完整的序列而发生剧烈变化。
在自然语言中,模型应该主要依赖于最近的上下文,而早期的 token 不应该完全改变预测,尤其不应该改变到两个输出概率分布之间的整体变差接近 1 的程度。这意味着模型在序列开头的 token 上受到了不成比例的影响。
状态传递修正了有效记忆
经过状态传递的后训练,EffRem 曲线显示出逐渐上升,表明模型对远程 token 的权重最小,并逐渐增加对最近 token 的权重。特别是,紧邻上下文中的 token(例如句子中的前一个词)对下一 token 的预测具有重要影响,这正是文本建模中期望的行为。
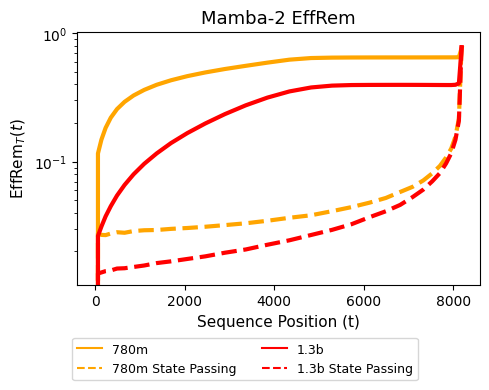
简而言之,通过有效记忆,我们可以确认状态传递帮助模型优先考虑最近的上下文,而不会被远处的过往 token 不必要地干扰。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











