




机构: 北京大学人工智能研究院 北京通用人工智能研究院
作者: 毛彦升 徐宇飞 李佳琪 孟繁续 杨昊桐 郑子隆 王希元 张牧涵
长文本任务是当下大模型研究的重点之一。在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。扩充模型的长文本能力不仅意味着可以在上下文窗口中装入更长的文本,更是能够更好地建模文本段落间信息的长程依赖关系,增强对长文的阅读理解和推理。
现有大模型解决长文本任务的难点之一是传统的 dot-product attention 对输入长度呈平方复杂度,且存储 KV cache 的开销随输入长度增加,时间和空间开销都较高。
此外,模型难以真正理解散落在长文本各处信息间的长程依赖。主流的长文本解决方法包括 Retrieval-Augmented Generation(RAG)[1]、long-context adaption 等。
RAG 从长文本中抽取与问题相关的信息放入 context window 进行推理,但它依赖准确的检索方法,大量的噪声和无关信息会进一步引起模型幻觉。
long-context adaption 通过在大量长文本的数据集上后训练[2]扩展模型的 context window,但其推理复杂度随文本长度平方增长、显存占用高,且 context window 仍然有限。
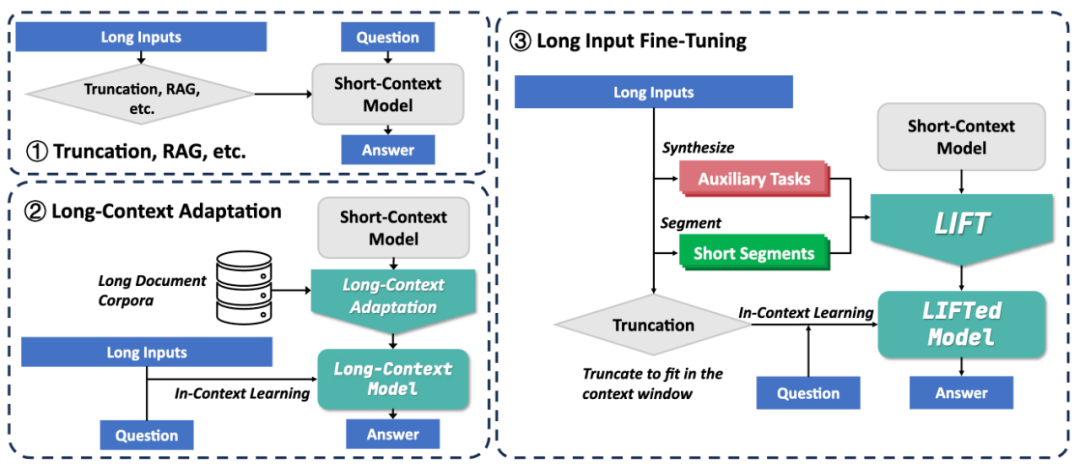
为了应对长文本开销大、难以建立长程依赖的挑战,北京大学张牧涵团队提出全新的框架 Long Input Fine-Tuning(LIFT)。通过将长输入文本训练进模型参数中,LIFT 可以使任意短上下文窗口模型获得长文本能力。

题目: LIFT: Improving Long Context Understanding of Large Language Models through Long Input Fine-Tuning
文章链接: https://arxiv.org/abs/2502.14644
表 1 是 LIFT 和现有常见方法的对比。

LIFT 首次提出将长文本知识存储在模型参数中,而不是外部数据库或上下文窗口中,类比人类将 working memory 转成 long-term memory,实现知识的内化。
与此相比,我们认为无限地扩充 context window 无法真正解决长文本、长历史的挑战,因为无论再长的 context window 仍然有耗尽的一天,而只有将上下文持续地转变成 parametric knowledge,才能实现无限地学习。
研究创新
我们的方案具有以下优势:
动态高效的长输入训练。LIFT 能够通过调整模型参数,动态适应新的长输入文本,将其作为新的知识源,无需进行资源密集型的 long-context adaptation。针对每一篇需要处理的长文本,LIFT 通过分段的 language modeling 以及精心设计的辅助任务来微调模型,实现用模型参数来记忆和理解长文本,从而避免过长的 context 造成的推理复杂度提升和长程依赖丢失。
平衡模型参数知识和原有能力。由于模型原有参数(比如 Llama 3 8B)通常显著大于记忆长文本所需的参数量,全参数微调面临过拟合长文本而损失模型基础能力的风险。为了在模型原有能力和微调后新的参数内知识之间找到平衡,我们提出了一种专门的参数高效微调模块——门控记忆适配器(Gated Memory Adapter),它能平衡原始模型的 In-Context Learning(ICL)能力和 LIFT 训练后对长输入的记忆理解能力。
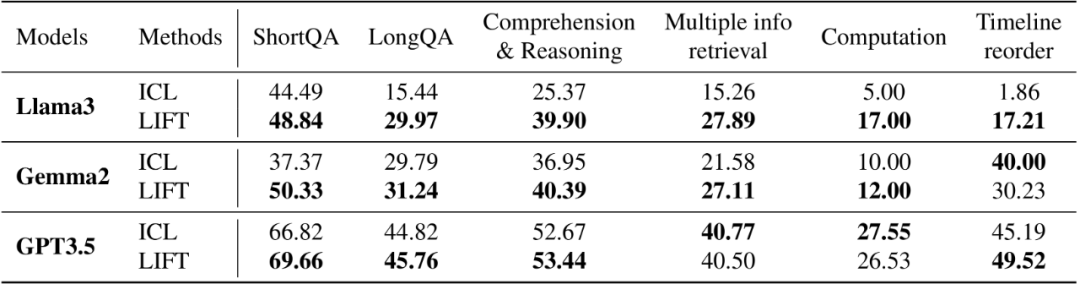
在流行的长上下文任务上取得了巨大提升。在几个广泛认可的长上下文基准集(例如 LooGLE [3]、Longbench [4])上的评估表明,不同 LLM 始终能通过 LIFT 在常见的长/短依赖问答和摘要等通用任务上受益。例如,在非常具有挑战性的 LooGLE 长依赖问答上,相较仅通过 ICL,LIFT 过后的 Llama 3 8B 的正确率从 15.44% 提升至 29.97%。在 LooGLE 短依赖问答上,LIFT 将 Gemma 2 9B 的正确率从 37.37% 提升至 50.33%。
LIFT 方法
长文本切段训练
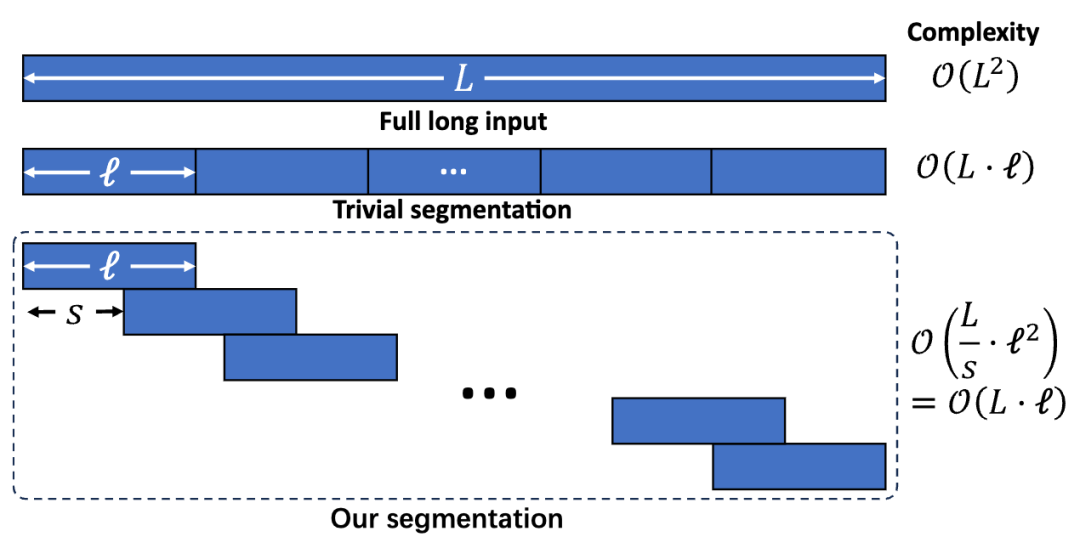
受 LLM 预训练的启发,LIFT 将「记忆长文本」的任务建模为语言建模(Language Modeling)任务。但在整篇长文本上进行语言建模训练开销过大,且短上下文模型不具备直接在长文本上训练的能力。为此,LIFT 将长文本切分为固定长度的片段,对所有片段并行进行语言建模训练。
如果将长文本切分为互不相交的片段(如图 2 中 Trivial segmentation 所示),模型将丢失片段间的正确顺序,而顺序对于长文本中的长程依赖和总体理解非常重要。因此,LIFT 要求相邻片段有一定重叠(如图 2 中的 Our segmentation 所示)——每个片段的末尾就是下一个片段的开头。
这样,如果模型能够记忆某个片段,那么它就能够续写出下一个片段,直到按顺序续写出全文。在实验中,我们取重叠的长度为片段长度的 5/8,因此训练的复杂度对长文本的长度呈线性。
辅助任务训练
在特定任务上微调 LLM 通常会导致其在其他任务上能力下降。同理,长文本切段训练可能导致 LLM 的 reasoning、instruction-following 等能力损失。
研究团队提出在合成的辅助任务上训练,一方面弥补模型的能力损失,另一方面帮助模型学会应用长文本中的信息回答问题。具体而言,研究团队用预训练的 LLM 基于长文本片段自动生成几十个问答类型的辅助任务。
于是 LIFT 训练分为两个阶段,第一个阶段只在长文本切段任务上进行语言建模训练,第二个阶段在辅助任务上训练模型基于长文本回答问题的能力。
Gated Memory 架构
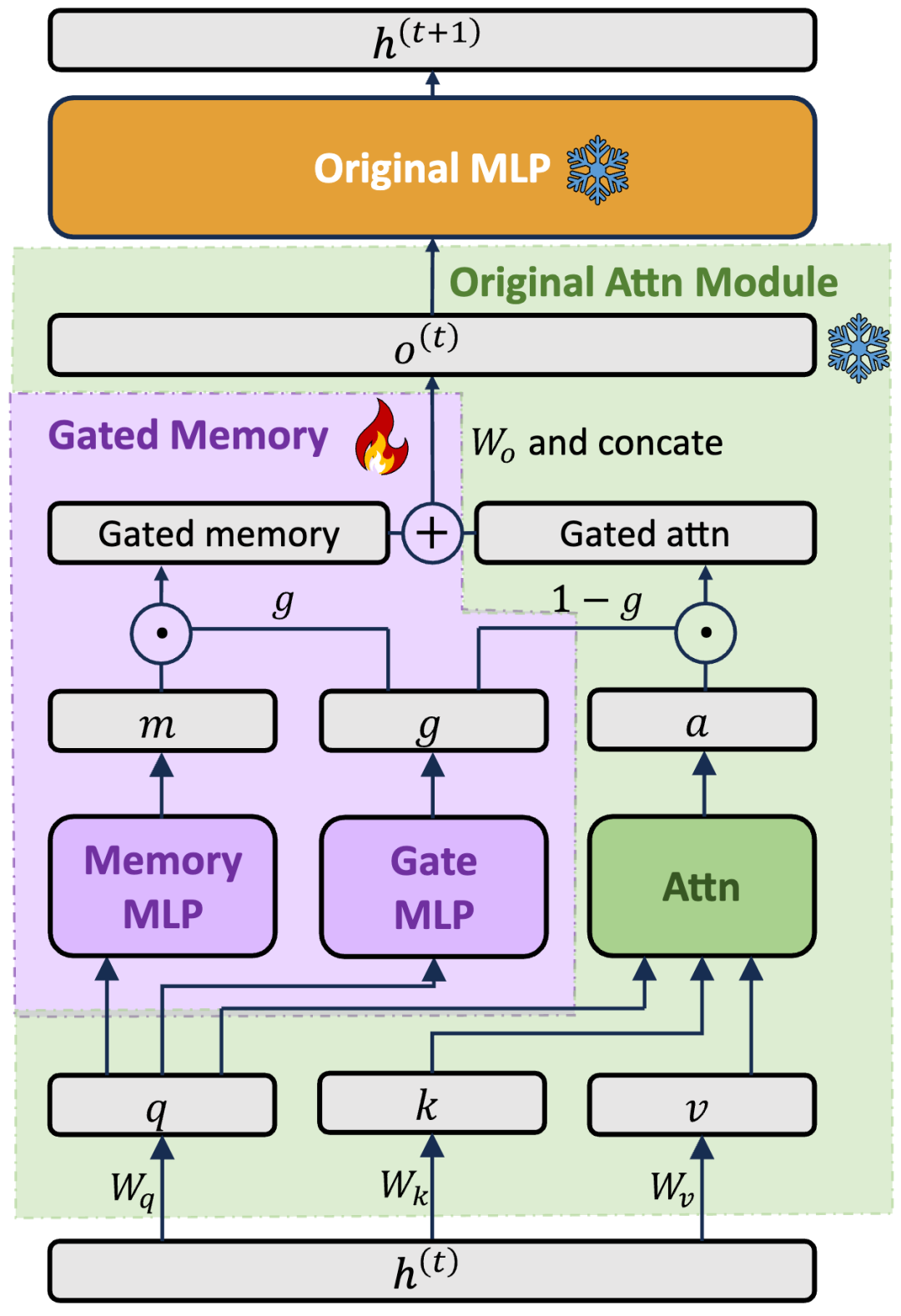
尽管 LIFT 可以任意使用全参数微调或 LoRA/PiSSA 等参数高效微调方法来训练模型,我们提出了一个专用的 Gated Memory Adapter 来平衡长文本记忆和能力。其核心在于用短窗口模型模拟假设长文本在上下文窗口中时模型的行为和内部表示。
为此我们将假设的「全上下文」分为窗口外(out-of-context)和窗口中(in-context)两部分——窗口外放置的是预计将通过微调放入参数中的长文本,而窗口中放置的是关于长文本的问题。
我们的目的是设计一个模型,用 LIFT 参数 + 窗口外内容(短上下文)去模拟全上下文的行为,以此达成只用短上下文模型实现长上下文的注意力机制。
为此,我们设计了一个门控记忆模块(Gated Memory)(见图 3)。该模块为每个注意力层增加了两个特殊的 MLP(图 3 中的 Memory MLP 和 Gate MLP),均以每个位置的 query vector 为输入,分别用于学习「窗口外部分的权重」(gate)和「窗口外部分的记忆提取内容」(memory)。
这样,当一个新的 query 进入,模型可以动态地调控其使用多少 LIFT 记忆的窗口外内容:当 gate=0,模型将恢复为纯 ICL,不用任何 LIFT 记忆的信息;当 gate=1,模型将完全依赖 LIFT 知识而忽略当前窗口中的上下文。
这种动态分配机制可以有效地平衡对长文本的记忆和模型原本的 ICL 能力。LIFT 训练过程中,我们将只微调 Gated Memory 中的参数,实现了模型在微调较小参数量的情况下,有效地记忆长文本内容并用于下游任务。
实验证明了这一结构的有效性(见下文表 4)。
实验测评
为了评估 LIFT 的有效性,研究团队在 Llama 3 8B 和 Gemma 2 9B 两个短文本开源模型(上下文窗口为 8k)上和 GPT 3.5 商用模型(上下文窗口为 16k)上比较了 LIFT 方法和使用截断 ICL 的 baselines。
baselines 使用原模型,尽可能将长文本填入模型的上下文窗口(优先填入开头和末尾 tokens,其余截断),并保证问题 prompt 全部填入。LIFT 在测试时的输入与 baseline 相同,但使用的模型为经过 LIFT 训练的模型,并默认使用 Gated Memory 适配器。
对于 GPT3.5,我们直接调用 GPT 3.5 的训练 API。我们主要在两个代表性的长文本评测集 LooGLE 和 LongBench 上评测,其中 LooGLE 包含大量人工标注的极具挑战性的长依赖问答(LongQA)和 LLM 自动生成的短依赖问答(ShortQA),LongBench 包含问答、摘要等多种任务。
结果如表 2、表 3 所示,实验表明:
LIFT 极大提升了短文本模型在 LooGLE 上的表现。LIFT 稳定提升了被测模型在 ShortQA 和 LongQA 中的平均指标。值得注意的是,Llama 3 在 LongQA 上的指标从 15.44% 提升至 29.97%,Gemma 2 在 ShortQA 上的指标从 37.37% 提升至 50.33%。
LIFT 提升了短文本模型在 Longbench 的大多数子任务上的表现。研究团队从 LongBench 中选取了 5 个具有代表性的子任务进行测试,任务包括多篇文章间的多跳推理、阅读理解和概括、检索召回等,Llama 3 通过 LIFT 在其中 4 个子任务上均有提升。
LIFT 的效果与模型的原有能力以及测试任务有关。LIFT 虽然普遍提升了模型的长文本能力,但在部分子任务上仍有改进空间。通过分析各个子任务,研究团队认为与测试问题相似的辅助任务可以促进模型关注对测试任务有用的长上下文信息,有助于下游任务表现。

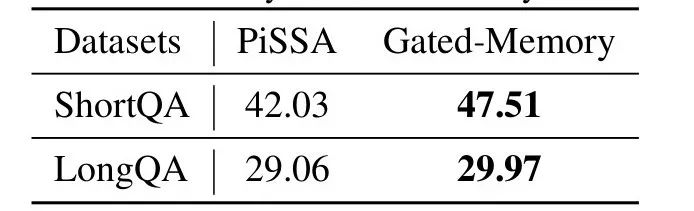
此外,我们通过消融实验验证了 Gated Memory 适配器的作用。如表 4 所示,在 LooGLE ShortQA 数据集上,Gated Memory 架构相比于使用 PiSSA[5](一种 LoRA 的改进版方法)微调的原模型,GPT-4 score 提升了 5.48%。
总结、展望和讨论
在本文中,我们提出了一种新颖的框架——LIFT,以增强 LLMs 的长上下文理解能力。LIFT 通过高效微调模型参数,利用参数内知识(in-parameter knowledge)来动态适应长输入,从而提升长上下文任务的能力。实验结果表明,在 LooGLE 和 LongBench 等流行基准测试中,LIFT 显著提升了短上下文 LLMs 在长上下文任务中的表现。
然而,LIFT 仍然存在一定局限性。首先,在 context window 不够的情况下,我们经常需要截断上下文来做长文本推理,但对于需要精确信息提取的任务,如「大海捞针任务」(Needle in a Haystack),该方法仍然性能欠佳。
其次,LIFT 通过将长文本输入注入模型参数,增强了模型对数据的熟悉度,但下游任务的效果仍然依赖于模型能否自主提取和利用 LIFT 过程中获得的参数化知识。分析表明,模型在「in-context」和「out-of-context」问题上的表现存在显著差距,表明 LIFT 后的参数化知识提取能力仍需进一步优化。
此外,我们发现在 LIFT 过程中引入辅助任务并不能总是显著提高模型能力,其性能严重依赖下游测试任务和辅助任务的相似程度,甚至可能因过拟合而导致性能下降。因此,如何设计更通用的辅助任务是未来的研究重点。
最后,尽管 Gated Memory 架构显著提升了长文本记忆和 ICL 能力的平衡,我们发现 LIFT 后的模型仍存在对原有能力的破坏,如何设计更好的适配器来平衡记忆和能力,也留作未来工作。
LIFT 的理念非常有趣,因为人类的短期记忆也会转化为长期记忆,这一过程类似于 LIFT 将上下文中的知识转换为参数化知识。虽然距离彻底解决 LLMs 的长上下文挑战仍然任重道远,但我们的初步结果表明,LIFT 提供了一个极具潜力和前景的研究方向。
我们鼓励社区一同探索 LIFT 在更广泛的训练数据、更丰富的模型、更先进的辅助任务设计以及更强计算资源支持下的潜在能力。
参考文献
[1] Jiang, Ziyan, Xueguang Ma, and Wenhu Chen. "Longrag: Enhancing retrieval-augmented generation with long-context llms." arXiv preprint arXiv:2406.15319 (2024).
[2] Chen, Yukang, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. "LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models." In The Twelfth International Conference on Learning Representations.
[3] Li, Jiaqi, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. "LooGLE: Can Long-Context Language Models Understand Long Contexts?." In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16304-16333. 2024.
[4] Bai, Yushi, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du et al. "LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding." In ACL (1). 2024.
[5] Meng, Fanxu, Zhaohui Wang, and Muhan Zhang. "PiSSA: Principal singular values and singular vectors adaptation of large language models." Advances in Neural Information Processing Systems 37 (2024): 121038-121072.
[6] Hong, Junyuan, Lingjuan Lyu, Jiayu Zhou, and Michael Spranger. "Mecta: Memory-economic continual test-time model adaptation." In 2023 International Conference on Learning Representations. 2023.



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











