




对于人工智能,有一个话题总会时而冒出来:「AI 是否或能否具有自我意识」?对于这个问题,目前还没人能给出非常确切的答案,但近日 Chandar Research Lab 和 Mila - 魁北克人工智能研究所等机构的一项研究却揭开了这神秘问题的一角。
他们发现,大型语言模型(LLM)有自知之明,也就是说,只要规模够大,它们就能够知道自己对某个主题的了解程度。该论文中写到:「虽然不同架构涌现这种能力的速率不同,但结果表明,知识意识(awareness of knowledge)可能是 LLM 的一个普遍属性。」

论文标题:Do Large Language Models Know How Much They Know?
论文地址:https://arxiv.org/pdf/2502.19573
方法
那么,该团队是如何发现这一点的呢?很容易想见,这个研究问题的核心在于分析了解模型记忆和回想信息的能力。为了避免现有数据的影响,该团队生成了一些新数据,从而可以确保模型在预训练阶段从未见过这些数据,由此防止结果被污染。
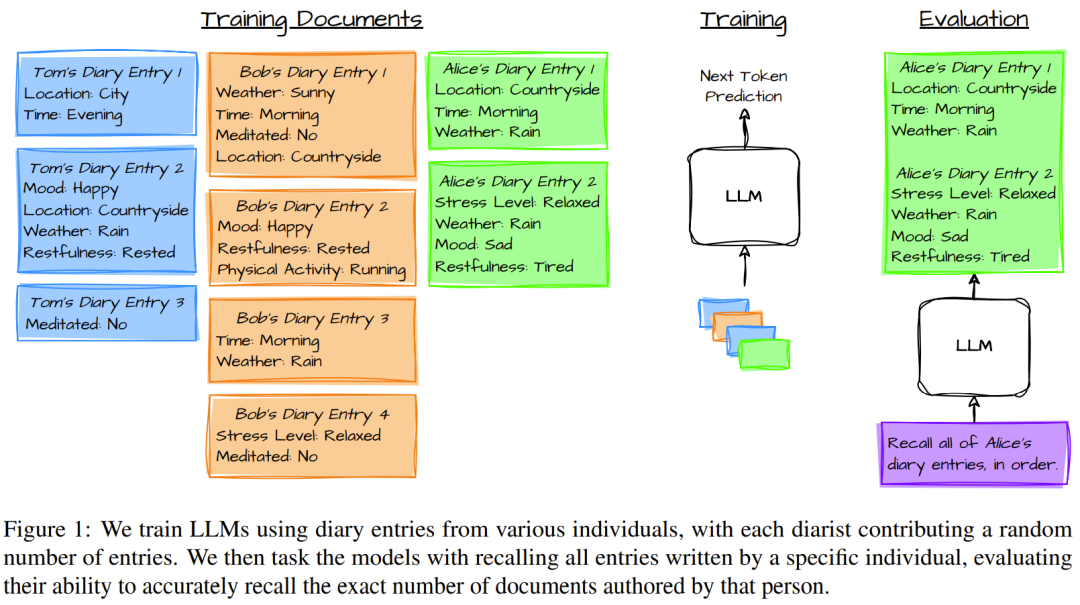
本质上讲,该方法包含三个阶段:
生成训练文档;(这里采用了日记作者的日记文档设定)
使用其预训练目标来微调语言模型,让其记住这些文档;
测试语言模型回忆所有相关文档的能力。
有关这些阶段的详细过程,请参阅原论文,这里我们更关注其得到的结果。
实验结果:LLM 有自知之明
实验中,该团队使用了两种类型的多个不同参数量的模型:
仅解码器模型:OPT(7M 到 2.7B)和 OPT(7M 到 2.7B);
编码器 - 解码器模型:Flan-T5(80M to 3B)。
架构和规模的影响
首先,该团队评估了架构、模型大小和数据集大小对性能的影响。结果见图 2,其中横轴表示模型大小,纵轴表示正确回答问题的百分比。图上的每条线对应于一个特定的架构(例如 OPT),从最小到最大的模型,并在一个特定的数据集大小上进行了训练。
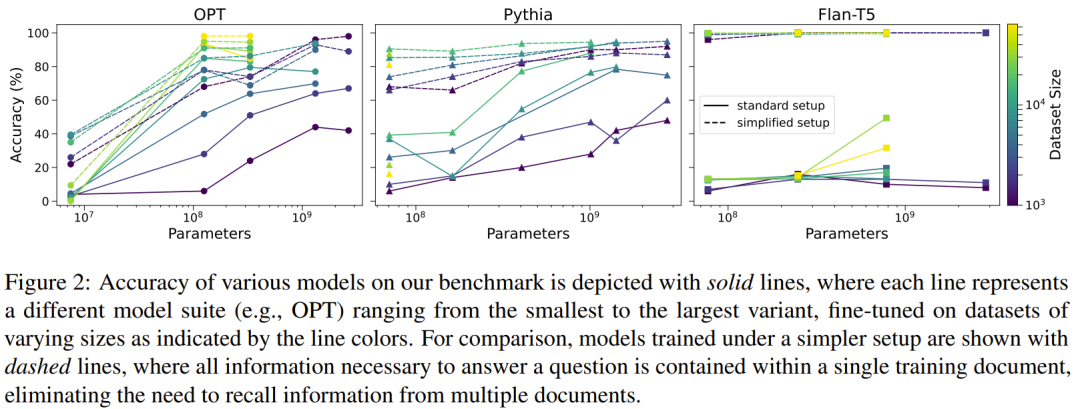
对于 OPT 模型,可以观察到一个总体趋势:随着模型大小和数据集规模增长,性能会提高。从由 7M 参数组成的最小变体开始,性能最初会随着数据集的扩大而提高,在 4K 个日记作者时达到峰值。但是,超过此阈值后,数据集的进一步扩展会导致性能下降。实验结果的这种模式表明,虽然更大的数据集可以增强泛化能力,但也会让模型的容量饱和,从而导致收益递减甚至效果下降。
相比之下,125M 参数的 OPT 模型表现明显不同。该模型足够大,即使数据集大小增加到最大测试值(64K 日记作者),性能也会持续提升。
此外,在保持数据集大小不变的情况下,增加模型大小通常可以带来性能提升。
Pythia 模型表现出了与 OPT 模型类似的趋势:随着模型大小和数据集大小的增加,性能会提高。
然而,在比较这两种架构时,出现了一个有趣的区别:OPT 模型的性能提升比 Pythia 更快出现。具体而言,在这里最大的数据集上训练时,125M 参数的 OPT 模型明显优于 160M 参数的 Pythia 模型。这种差异表明,所研究的能力出现的速度取决于底层模型架构的差异。
最后,与其他架构相比,Flan-T5 模型表现出了独特的模式。在最小的数据集上,仅增加模型大小不会带来任何明显的改进。性能提升仅在 783M 参数时才开始出现,即使如此,也只有在两个最大的数据集上训练时才会出现。
该团队也谈到了这个实验的局限性:「由于计算限制,我们无法在我们最大的数据集上测试具有 2.8B 参数的最大 Flan-T5 模型。然而,总体结果表明,这种能力确实会在足够规模下涌现 —— 尽管其发展速度因模型架构而有不同。」
分布式信息的影响
他们还使用一组更加简单的设置,训练了另外一组模型,并比较了它们的性能。
具体来说,这一组模型是在相同的数据集上进行训练的,但同一个人撰写的所有日记条目都会被合并到单个训练文档中,而不是每个条目都是一个单独的文档。
这种方法相当于直接在答案上训练模型,要求它们简单地记忆和回忆单个文档。
这两种设置之间的性能差异表明:处理分散在多个训练文档中的信息时,还会有额外的难度。这种分布式情况可能会影响信息在模型参数中的存储方式,可能会使模型在信息更分散时更难整合信息。
图 2 中以虚线展示了使用这种更简单设置训练的模型结果。在所有情况下,与使用分布式设置训练的相同基础模型相比,这些模型都有显著的性能提升。有趣的是,所有 Flan-T5 模型在这种简化设置下都实现了近乎完美的准确度,而 OPT 和 Pythia 模型则没有,不过它们的表现也不错并且会随着规模的扩大而不断改进。
图 3 中提供了清晰的可视化,可以更好地说明两种设置之间的性能差距。其中,纵轴给出了「简化」设置和「标准」设置之间的准确度差距。
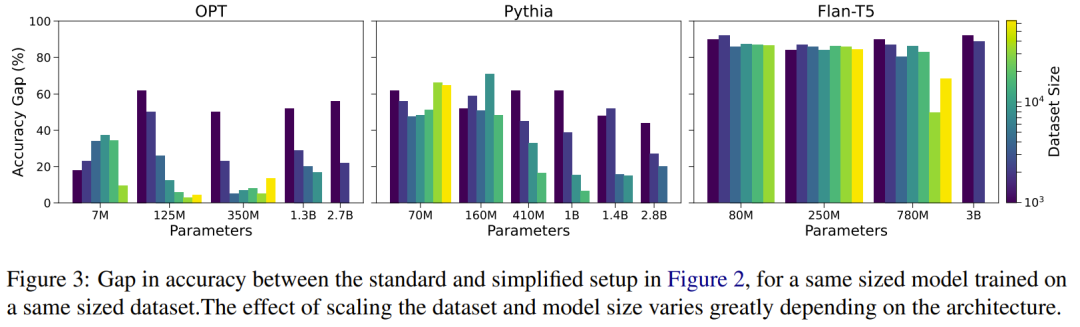
对于 OPT 模型,随着数据集大小的增加,差距会缩小,最小的模型除外。对于 Pythia ,似乎只有在足够大的数据集上训练更大模型,这个差距才会缩小。对于 Flan-T5,除了在最大数据集上训练的 780M 参数模型外,随着数据集和模型规模的扩大,性能差距几乎没有缩小。
目前尚不清楚为什么 Flan-T5 模型在更简单的设置中表现如此出色,但在标准设置中表现如此糟糕。鉴于该模型在前一种情况下具有近乎完美的准确性,其在后一种情况下的糟糕表现不能归因于方法论问题,因为两种情况下的过程是相同的。唯一的区别是,在后一种情况下,模型必须从多个文档而不是单个文档中回忆信息。因此,该模型可能在这方面存在问题。
对于所有模型,研究者暂时无法确定它们在两种设置中的表现是否会随着规模的扩大而继续提高,以及差距是否会最终消失。
文档数量的影响
该团队研究了要合并和回忆的文档数量对模型性能的影响。
图 4 报告了按目标答案中的文档数量分组的准确度(横轴)。线条颜色表示模型大小。为了保持清晰度,这里仅给出在 8K 日记作者数据集上训练的模型的性能,因为在其上观察到的趋势与其他数据集一致。
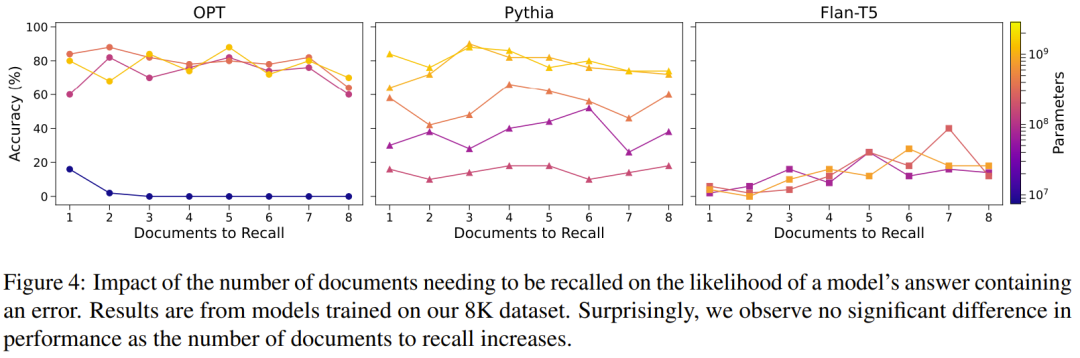
令人惊讶的是,当需要回忆更多日记条目时,模型并没有表现出性能下降。鉴于要生成的内容增加,人们可能会预期模型答案中出现错误的可能性会更高。然而,这一观察结果可能归因于模型的容量足够,并且只有在回忆更多数量的文档时才可能出现性能下降。
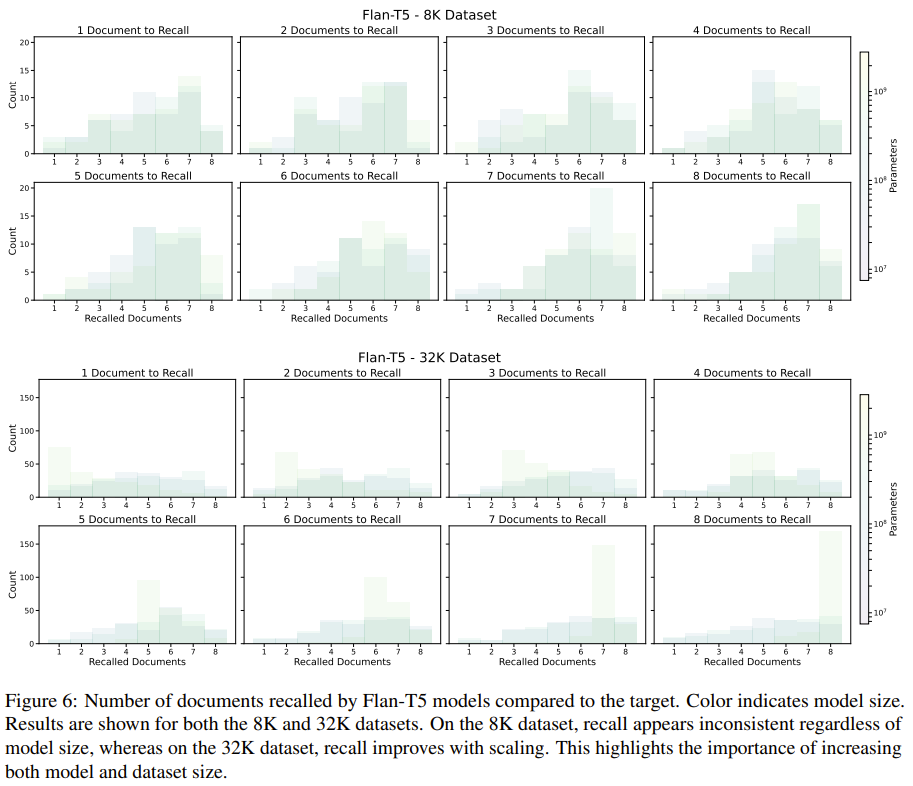
为了更深入地了解模型行为,该团队还分析了模型回忆的文档数量与目标文档数量的比较(图 5 和 6)。
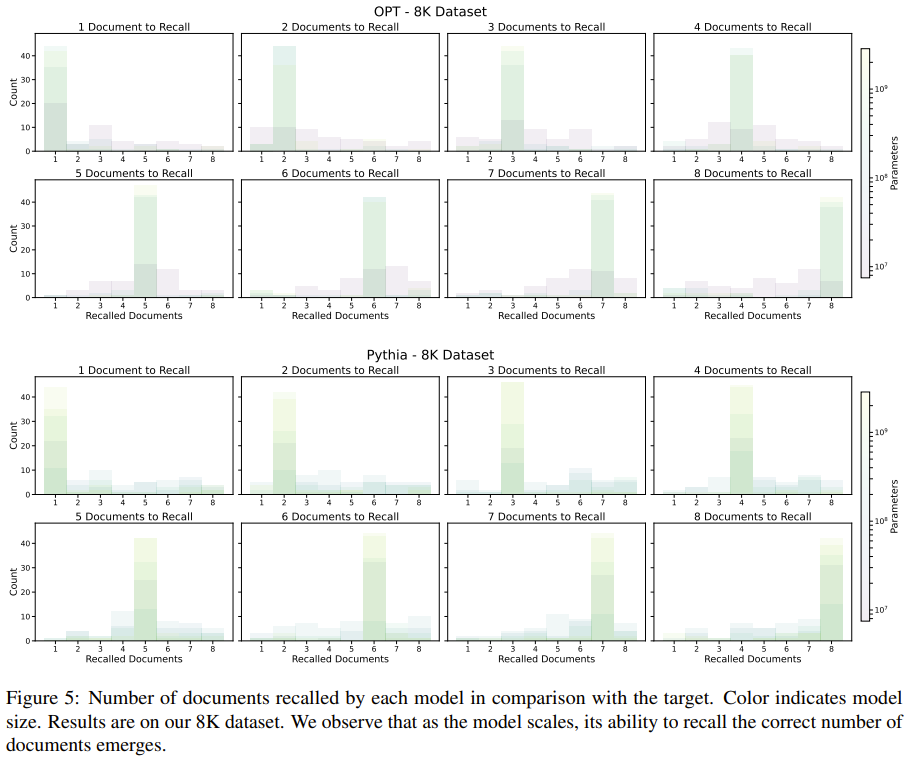
对于在 8K 日记作者数据集上训练的 OPT 和 Pythia 模型,较小的模型似乎可以回忆起随机数量的文档。然而,随着模型规模的增加,准确确定要回忆的适当文档数量的能力会逐渐显现。
相比之下,无论模型规模如何,在相同的 8K 日记作者数据集上训练的 Flan-T5 模型则会始终检索看似随机数量的文档。有趣的是,当扩展到 32K 日记作者的数据集时,Flan-T5 会表现出与 OPT 和 Pythia 类似的模式 —— 随着模型规模的增加,识别应回忆多少文档的能力会逐渐显现。
更多具体的实验数据请参看原论文。
综合分析
深挖前面的实验观察,可以看到这些模型的能力所在与失败之处,包括:
当规模足够大时,模型回忆的文档通常长度正确且没有错误。
在简化设置下训练的模型成功地回忆起了单个训练文档中的信息。因此,关键似乎不在于回忆的文档的内容,而在于回忆的文档数量。
如果规模不合适,模型似乎无法回忆正确数量的文档,而是会回忆随机数量的文档。
最小的 Pythia 模型如果从随机权重而不是预训练权重开始进行微调,其性能会更好,这表明预训练权重的糟糕表现不能完全归因于架构原因。相反,问题部分在于预训练权重未能学习到一种可以泛化到回忆正确数量文档问题的解决方案,而不仅仅是记住训练样本。
关于 Flan-T5,考虑到从头开始微调的最小模型的性能与从预训练权重微调的模型一样差,性能不佳的根本原因可能是架构或超参数设置不对。
此外,模型的大小似乎会影响其性能。由于 Flan-T5 采用编码器 - 解码器架构,与 OPT 和 Pythia 等模型的仅解码器结构不同,其参数在编码器和解码器之间大致相等。因此,第二大 Flan-T5 模型的解码器大小与第三小 Pythia 模型的解码器大小相当,这与 Pythia 性能开始提高的点相吻合(如图 2 所示)。Pythia 系列模型中小于此阈值的模型没有表现出显著的性能提升。然而,最小的 Pythia 模型在从头开始训练时,在类似条件下的表现优于 Flan-T5。这凸显出架构因素可能会阻碍相同大小模型的能力的涌现。
至于规模,该团队的假设是较小的模型缺乏开发执行此任务所需回路的能力,但要了解这些较小模型面临的挑战,还需要进一步的研究。
整体来说,这项研究证明了足够规模的 LLM 确实具有知识意识(awareness of knowledge),即能够知晓自己的知识范围。你认为这是否暗示了 LLM 存在自我意识呢?



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











