




Deepseek-R1 的卓越表现引发了广泛关注,但其训练方法始终未曾公开。虽然 Deepseek 的模型已开源,但其训练方法、数据和脚本等关键信息仍未对外披露。
根据 Deepseek 公布的信息,许多人认为,只有训练更大规模的模型,才能真正发挥强化学习(RL)的威力。然而,训练大模型需要庞大的计算资源,让开源社区望而却步。目前的工作(如 TinyZero)仅在简单任务上复现了所谓的 “Aha moment”,或者仅提供训练基础设施和数据(如 OpenR)。
一个由伯克利团队领衔的研究小组提出了一个大胆的想法:能否用仅 1.5B 参数的小模型,以低成本复现 Deepseek 的训练秘方?他们发现,简单复现 Deepseek-R1 的训练方法需要巨大成本,即使在最小的模型上也需要数十万美元。但通过一系列训练技巧,团队成功将成本大幅降低,最终仅用 4500 美元,就在一个 1.5B 参数的模型上复现了 Deepseek 的关键训练方法。
他们的成果 ——DeepScaleR-1.5B-Preview,基于 Deepseek-R1-Distilled-Qwen-1.5B 模型,通过强化学习(RL)微调,实现了惊人的 43.1% Pass@1 准确率,提升了 14.3%,并在 AIME 2024 竞赛中超越了 O1-Preview。
这一成果不仅打破了 “大模型才能强大” 的固有认知,更展示了 RL 在小型模型中的无限可能。
更重要的是,伯克利团队开源了所有的训练秘方,包括模型、数据、训练代码和训练日志,为推动 LLM 强化学习训练的普及迈出了重要一步。

博客地址:https://pretty-radio-b75.notion.site/DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2
项目地址:https://github.com/agentica-project/deepscaler
项目网站:https://agentica-project.com/
Hugging Face 模型:https://huggingface.co/agentica-org/DeepScaleR-1.5B-Preview
Hugging Face 数据集:https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset
Wandb 训练日志:https://wandb.ai/mluo/deepscaler-1.5b?nw=nwusermluo
这项研究一经公布,受到网友广泛好评,有网友表示:「DeepScaleR-1.5B-Preview 正在撼动人工智能领域。」
「DeepScaleR 开创了 AI 扩展的新时代。」
「开源界又赢了一局。」

还有人盛赞:「这才是研究者想要的东西。」
1. 小模型的反击:DeepScaleR 的秘密
挑战 RL 的极限
强化学习一直被视为大模型的 “专属武器”,高昂的计算成本让很多人望而却步。研究团队发现,假如直接复现 Deepseek-R1 的结果 (32K 上下文长度,8000 训练步数),即使在一个 1.5B 的小模型上,需要的 A100 GPU 时长高达 70,000 小时。但研究团队并未退缩,他们提出了一种巧妙的策略,让 RL 的训练成本降低至常规方法的 5%,最终只用了 3800 A100 GPU 小时和 4500 美元,就在 1.5B 的模型上训练出了一个超越 OpenAI o1-preview 的模型,DeepScaleR 的秘密,在于提出了一个迭代式上下文扩展的训练策略。
迭代式上下文扩展:小步快跑,突破瓶颈
在 RL 训练中,上下文窗口的选择至关重要。选择一个比较长的上下文会导致训练变慢,而选择一个短的上下文则可能导致模型没有足够的上下文去思考困难的问题。
研究团队在训练前进行了先验测试,发现错误答案的平均长度是正确答案的 3 倍。这表明,如果直接在大窗口上进行训练,不仅训练速度慢,效果也可能受限,因为有效训练的字符(token) 数量较少。
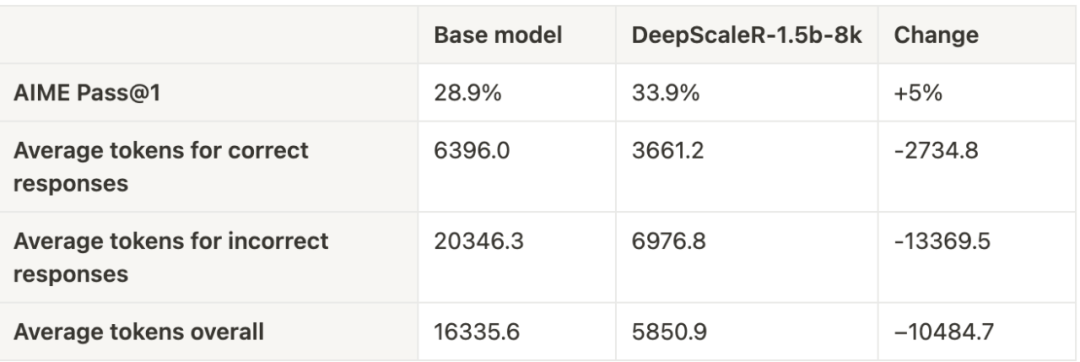
基于这个发现,因此他们采用了迭代式上下文扩展策略:
1.8K 上下文窗口:模型先在较短的上下文中简化自己的推理,精进推理技巧。
2. 扩展至 16K & 24K:逐步加大窗口,让模型适应更复杂的数学推理任务。
这种策略证明是有效的 —— 在第一轮 8K 上下文训练后,模型的平均回答长度从 9000 字符降至 3000 字符,而 AIME 测试集上的正确率提高了 5%。随着上下文窗口扩展至 16K 和 24K,模型更简洁的回答方式使训练时间至少提升了两倍。
数据集:四万道数学难题的试炼
团队精心构建了一套高质量的数学训练集,包括:
AIME(1984-2023)
AMC(2023 年前)
Omni-MATH & Still 数据集
数据筛选的关键步骤:
1. 答案提取:利用 gemini-1.5-pro-002 自动提取标准答案。
2. 去重:采用 sentence-transformers/all-MiniLM-L6-v2 进行语义去重,避免数据污染。
3. 过滤不可评分题目:确保训练数据的高质量,使模型能够专注于可验证的答案。
奖励函数:精准激励模型进步
传统的 RL 训练往往使用过程奖励模型(PRM),但容易导致 “奖励滥用”,即模型学会取巧而非真正优化推理能力。为了解决这一问题,研究团队选择了跟 Deepseek-R1 一样的结果奖励模型(ORM),严格按照答案正确性和格式进行评分,确保模型真正提升推理能力。
2. 实验结果:数据不会说谎
在多项数学竞赛基准测试中,DeepScaleR-1.5B-Preview 展现了惊人的实力:
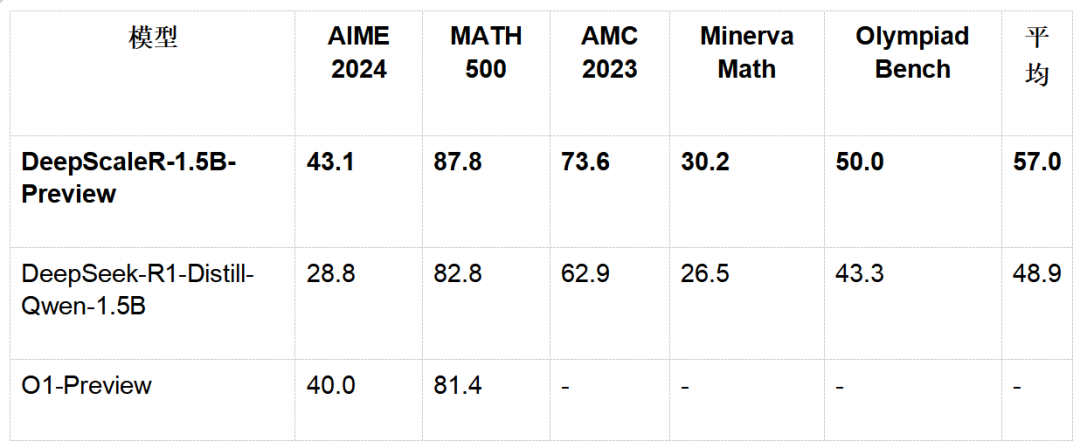
关键突破点:
1.DeepScaleR 在 AIME 2024 上超越 O1-Preview,证明了 RL 在小模型上的可行性。
2. 在所有测试集中,DeepScaleR 的平均表现远超基础模型,展现了强化学习的巨大潜力。
3. 关键发现:为什么 DeepScaleR 能成功?
(1)RL 并非大模型专属,小模型同样能崛起
DeepScaleR 的成功打破了强化学习只能用于大模型的迷思。研究团队通过高质量的 SFT 数据,让 1.5B 小模型的 AIME 准确率从 28.9% 提升至 43.1%,证明了小模型也能通过 RL 实现飞跃。
(2)迭代式上下文扩展:比暴力训练更高效
直接在 24K 上下文窗口中进行强化学习,效果远不如逐步扩展。先学短推理,再扩展长推理,可以让模型更稳定地适应复杂任务,同时减少训练成本。
4. 结论:RL 的新纪元
DeepScaleR-1.5B-Preview 的成功,不仅展示了小模型在强化学习中的无限潜力,也证明了高效训练策略的重要性。团队希望通过开源数据集、代码和训练日志,推动 RL 在 LLM 推理中的广泛应用。
下一步,他们计划在更大规模的模型上复现这一策略,并邀请社区共同探索 RL 的新可能。
或许,下一个挑战 OpenAI 的模型,就藏在这样一个小小的实验之中。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











