




选自oatllm.notion.site
机器之心编译
编译:杜伟、蛋酱
自我反思(尤其是肤浅的)有时对模型性能的助益不大。
在过去这半个月里,关于 DeepSeek 的一切都会迅速成为焦点。
一项非常鼓舞人心的发现是:DeepSeek-R1-Zero 通过纯强化学习(RL)实现了「顿悟」。在那个瞬间,模型学会了自我反思等涌现技能,帮助它进行上下文搜索,从而解决复杂的推理问题。
在 R1-Zero 发布后的短短几天内,连续几个项目都在较小规模(如 1B 到 7B)上独立「复制」了类似 R1-Zero 的训练,并且都观察到了「顿悟时刻」,这种时刻通常伴随着响应长度的增加。

原文链接:https://oatllm.notion.site/oat-zero
最近,来自新加坡 Sea AI Lab 等机构的研究者再次梳理了类 R1-Zero 的训练过程,并在一篇博客中分享了三项重要发现:
1. 在类似 R1-Zero 的训练中,可能并不存在「顿悟时刻」。相反,我们发现「顿悟时刻」(如自我反思模式)出现在 epoch 0,即基础模型中。
2. 他们从基础模型的响应中发现了肤浅的自我反思(SSR),在这种情况下,自我反思并不一定会导致正确的最终答案。
3. 仔细研究通过 RL 进行的类 R1-Zero 的训练,发现响应长度增加的现象并不是因为出现了自我反思,而是 RL 优化设计良好的基于规则的奖励函数的结果。
以下是博客的内容:
Epoch 0 的顿悟时刻
实验设置如下:
基础模型。我们研究了由不同组织开发的各种基础模型系列,包括 Qwen-2.5、Qwen-2.5-Math、DeepSeek-Math、Rho-Math 和 Llama-3.x。
提示模板。我们使用 R1-Zero 和 SimpleRL-Zero 中使用的模板直接提示基础模型:
模板 1(与 R1-Zero 相同)

模板 2(与 SimpleRL-Zero 相同)

数据。我们从 MATH 训练数据集中收集了 500 道题,这些题统一涵盖了五个难度级别和所有科目,用于填充上述模板中的 {Question}。
生成参数。我们在 0.1 至 1.0 之间对探索参数(温度)进行网格搜索,以便对选定的问题进行模型推理。在所有实验中,Top P 设置为 0.9。我们为每个问题生成 8 个回答。
经验结果
我们首先尝试了所有模型和提示模板(模板 1 或模板 2)的组合,然后根据每个模型的指令遵循能力为其选择了最佳模板,并将其固定用于所有实验。得出以下结论:
发现:「顿悟时刻」出现在 Epoch 0。我们观察到,所有模型(除了 Llama-3.x 系列)在没有任何后期训练的情况下就已经表现出了自我反思模式。
我们在下表中列出了所有观察到的表明自我反思模式的关键词。请注意,该列表可能并不详尽。这些关键词都是经过人工验证的,「等待」等词被过滤掉了,因为它们的出现并不一定意味着自我反思,而可能是幻觉的结果。我们注意到,不同的模型会显示与自我反思相关的不同关键词,我们假设这是受其预训练数据的影响。
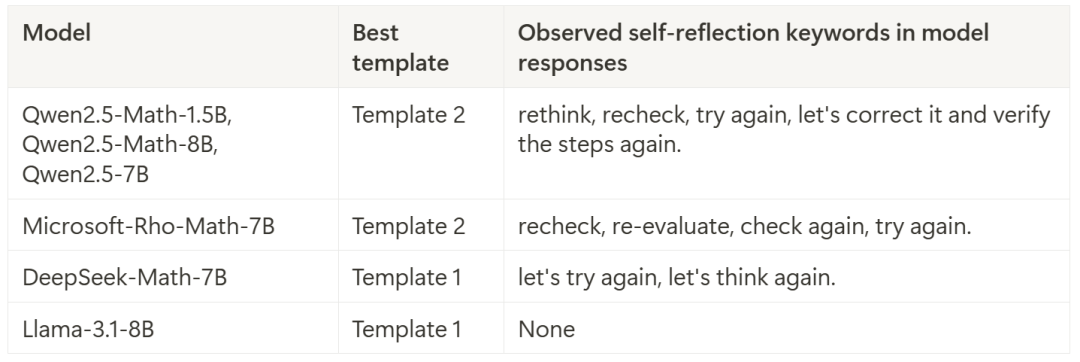
图 1a 展示了在不同基础模型中引发自我反思行为的问题数量。结果表明,在不同的温度下都能观察到自我反思行为,其中一个趋势是,温度越高,在 epoch 0 出现「顿悟时刻」的频率越高。
图 1b 展示了不同自我反思关键词的出现次数。我们可以观察到,Qwen2.5 系列的基础模型在产生自我反思行为方面最为活跃,这也部分解释了为什么大多数开源的 R1-Zero 复现都是基于 Qwen2.5 模型。
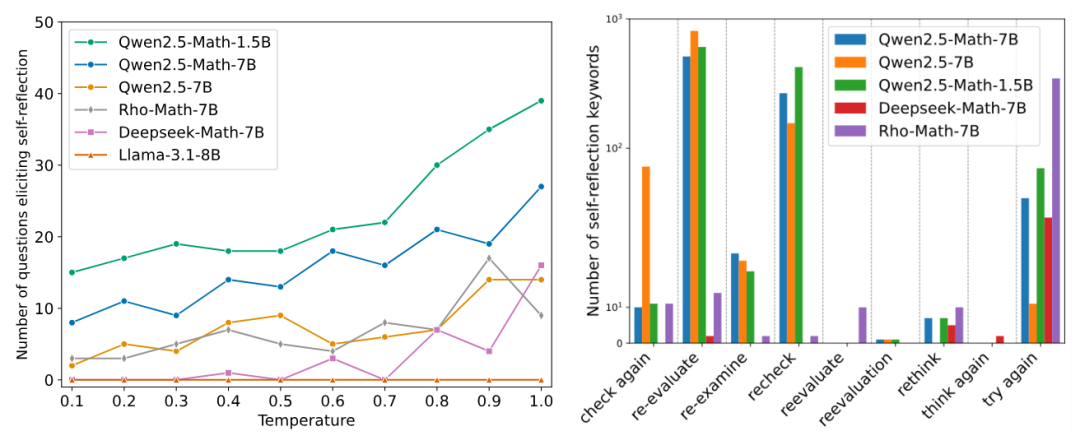
图 1a. 在不同基础模型中,500 道数学问题中引发自我反思行为的问题数量。图 1b. 40,000 个回答中出现的关键词数量(500 个问题 × 每个问题 8 个回答 × 10 个温度)。
在确认「顿悟时刻」确实是在没有任何训练的情况下出现在 epoch 0 后,我们想知道它是否如我们所期望的那样 —— 通过自我反思来纠正错误推理。因此,我们直接在 Qwen2.5-Math-7B 基础模型上测试了 SimpleRL-Zero 博客中使用的例题。令人惊讶的是,我们发现基础模型已经表现出了合理的自我纠正行为,如图 2 所示。

图 2. 我们直接在 Qwen2.5-Math-7B 基本模型上测试了 SimpleRL-Zero 博客中报告的同一问题,发现「顿悟时刻」已经出现。
肤浅的自我反思
尽管图 2 中的示例显示了基础模型通过自我修正 CoT 直接解决复杂推理问题的巨大潜力,但我们发现并非所有来自基础模型的自我反思都有效,也并不总能带来更好的解决方案。为了便于讨论,我们将它们称为肤浅的自我反思(Superficial Self-Reflection,SSR)。
就其定义而言,肤浅的自我反思(SSR)是指模型响应中缺乏建设性修改或改进的重评估模式。与没有自我反思的响应相比,SSR 不一定会带来更好的答案。
案例研究
为了进一步了解 SSR,我们进行了案例研究,并观察到 Qwen-2.5-Math-7B 基础模型响应中的四种自我反思模式:
行为 1:自我反思,反复检查以确认正确答案(图 3a);
行为 2:自我反思,纠正最初错误的想法(图 3b 和图 2);
行为 3:自我反思,在原本正确的答案中引入错误(图 3c);
行为 4:反复自我反思,但未能得出有效答案(图 3d)。
其中, 行为 3 和行为 4 是肤浅的自我反思,导致最终答案不正确。




基础模型容易出现 SSR
接下来,我们分析了 Qwen2.5-Math-1.5B 正确和错误答案中自我反思关键词的出现情况。正如图 4 所示,在不同的采样温度下,大多数自我反思(以频率衡量)都没有得到正确答案。这表明基础模型容易产生肤浅的自我反思。
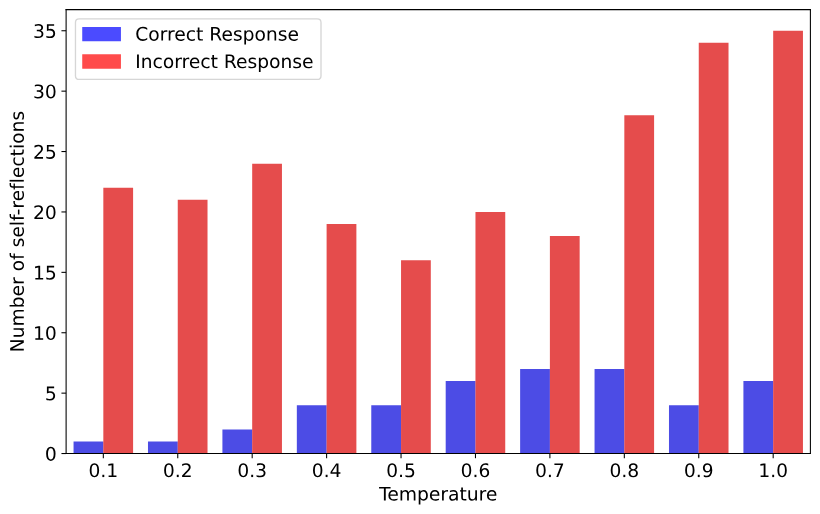
图 4:正确和错误答案中的自我反思次数。蓝色条表示正确答案中自我反思关键词的总出现次数,而红色条表示错误答案中自我反思关键词的总出现次数。
深入探讨类 R1-Zero 训练
虽然模型响应长度的突然增加通常被视为类 R1-Zero 训练中的顿悟时刻,但正如博客 Section 1 中的研究结果表明:即使没有 RL 训练,这种顿悟时刻也可能发生。因此,这自然引出了一个问题:为什么模型响应长度遵循一种独特的模式,即在训练初期减少,然后在某个点激增?
为了研究这一点,我们通过以下两种方法来研究类 R1-Zero 训练:
在倒计时(Countdown)任务上复制 R1-Zero 以分析输出长度动态;
在数学问题上复制 R1-Zero 以研究输出长度与自我反思之间的关系。
长度变化是 RL 动态的一部分
我们使用了支持类 R1-Zero 训练的 oat(一个研究友好的 LLM 在线对齐框架),以使用 GRPO 算法在倒计时任务(TinyZero 所用)上对 Qwen-2.5-3B 基础模型进行 RL 调整。
在该任务中,模型被赋予三到四个数字,并被要求使用算法运算(+、-、x、÷)来生成目标等式。这样不可避免地需要模型重试不同的方案,因此需要自我反思行为。
图 5 右显示了整个 RL 训练过程中奖励和响应长度的动态。与 TinyZero 和 SimpleRL-Zero 类似,我们观察到奖励持续增加,而长度先减少然后激增,现有工作将此归因于顿悟时刻。然而,我们观察到重试模式已经存在于基础模型的响应中(Section 1),但其中许多都是肤浅的(Section 2 ),因此奖励很低。
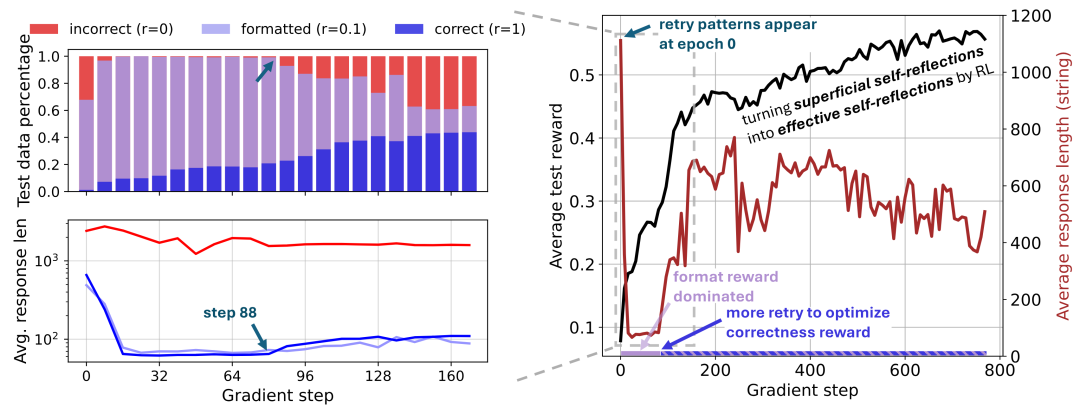
在初始学习阶段,我们分析了基于规则的奖励塑造对 RL 动态和响应长度变化的影响。图 5(左)根据奖励将模型响应分为了三个不同的组:

这种简单的分解揭示了一些关于 RL 动态的见解:
在 88 步之前的训练以塑造奖励 (r=0.1) 为主,通过调整模型使其在生成 token 预算内停止并在 块内格式化答案,从而可以更轻松地进行优化。在此期间,冗长的错误响应受到抑制,平均响应长度急剧下降。
在第 88 步,模型开始通过输出更多重试(retries)来「爬上奖励山」,朝着更高的奖励(r=1 表示正确性)攀登。因此,我们观察到正确响应的长度增加。伴随而来的副作用是,模型输出更多冗长的肤浅自我反思,导致平均响应长度激增。
整个 RL 过程是将原本肤浅的自我反思转变为有效的自我反思,以最大化预期奖励,从而提高推理能力。
输出长度和自我反思可能并不相关
按照 SimpleRL-Zero 的设置,我们使用 8K MATH 提示训练 Qwen2.5-Math-1.5B。在训练开始时,我们观察到输出长度减少,直到大约 1700 个梯度步,长度才开始增加(图 6)。然而,自我反思关键词的总数并没有表现出图 7 所示的与输出长度的单调关系。这表明单凭输出长度可能不是模型自我反思能力的可靠指标。
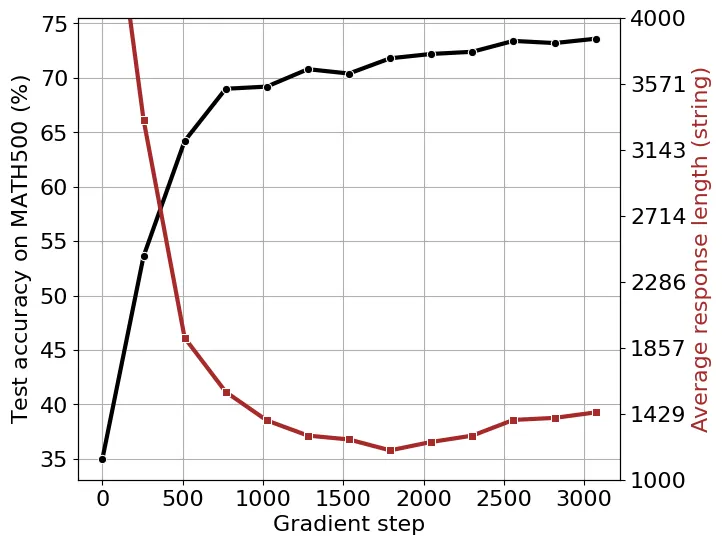
图 6:使用 8K MATH 提示的 Qwen2.5-Math-1.5B 训练动态。我们报告了 MATH500 上的测试准确率和平均响应长度。
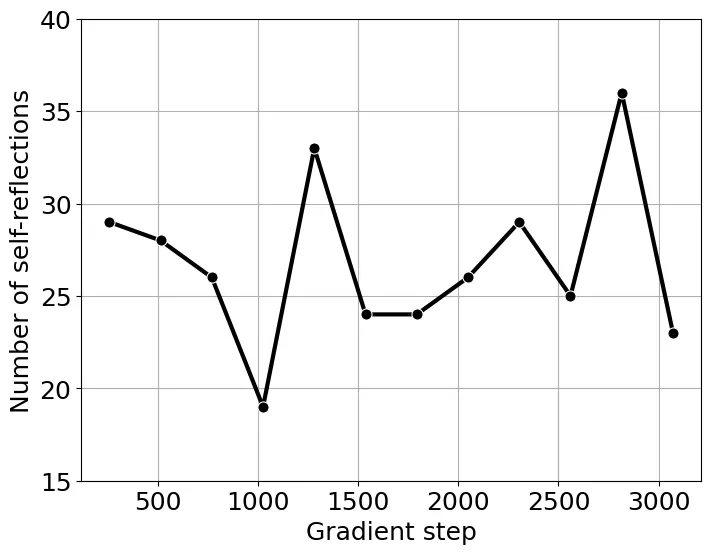 图 7:训练期间自我反思关键词的总数。
图 7:训练期间自我反思关键词的总数。在我们使用的单节点服务器上,完整训练过程大约需要 14 天,目前仍在进行中(进度相当于 SimpleRL-Zero 中的 48 个训练步)。我们将在完成后提供更详细的分析。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











