




AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
随着当前大语言模型的广泛应用和推理时扩展的新范式的崛起,如何实现高效的大规模推理成为了一个巨大挑战。特别是在语言模型的推理阶段,传统注意力机制中的键值缓存(KV Cache)会随着批处理大小和序列长度线性增长,俨然成为制约大语言模型规模化应用和推理时扩展的「内存杀手」。
虽然业界已有 MQA、GQA、MLA 等多种注意力机制变体试图解决这一问题,但这些方案要么难以在严格的显存限制下保持理想性能,要么在模型结构上引入额外复杂度,带来巨大的工程挑战和生态兼容性问题。
在近期由阶跃星辰、清华大学等机构完成的论文《Multi-matrix Factorization Attention》中,研究人员提出新型注意力机制架构 —— 多矩阵分解注意力(MFA)及其变体 MFA-Key-Reuse,在大幅降低语言模型推理成本的同时,还实现了性能的显著提升。

链接:https://arxiv.org/abs/2412.19255
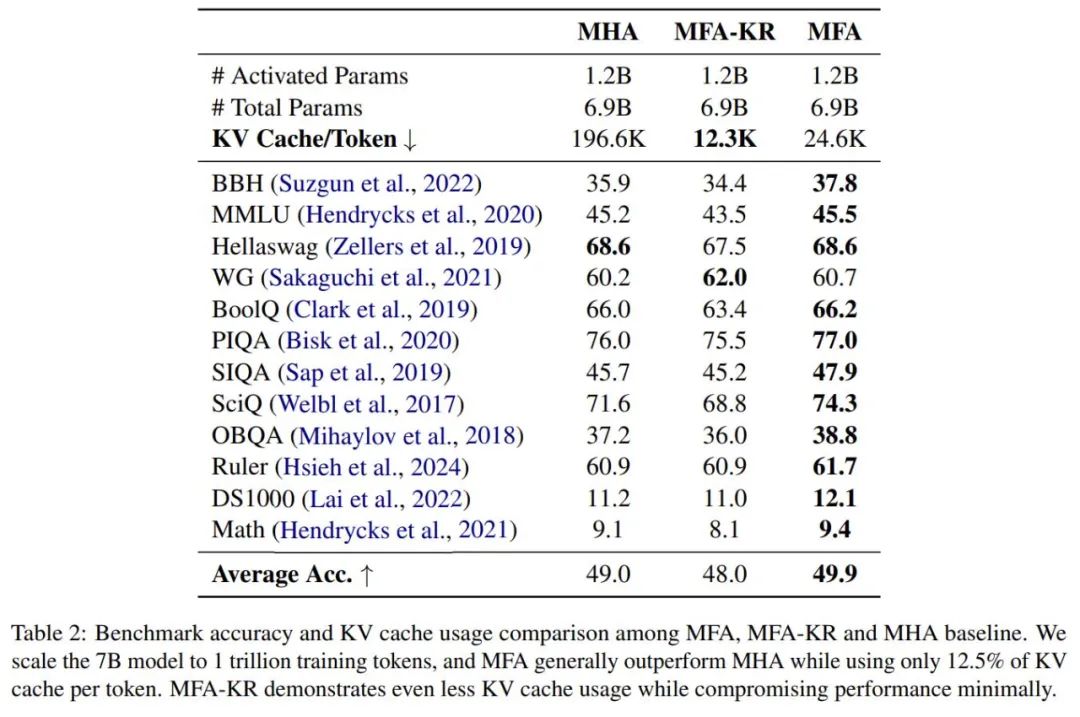
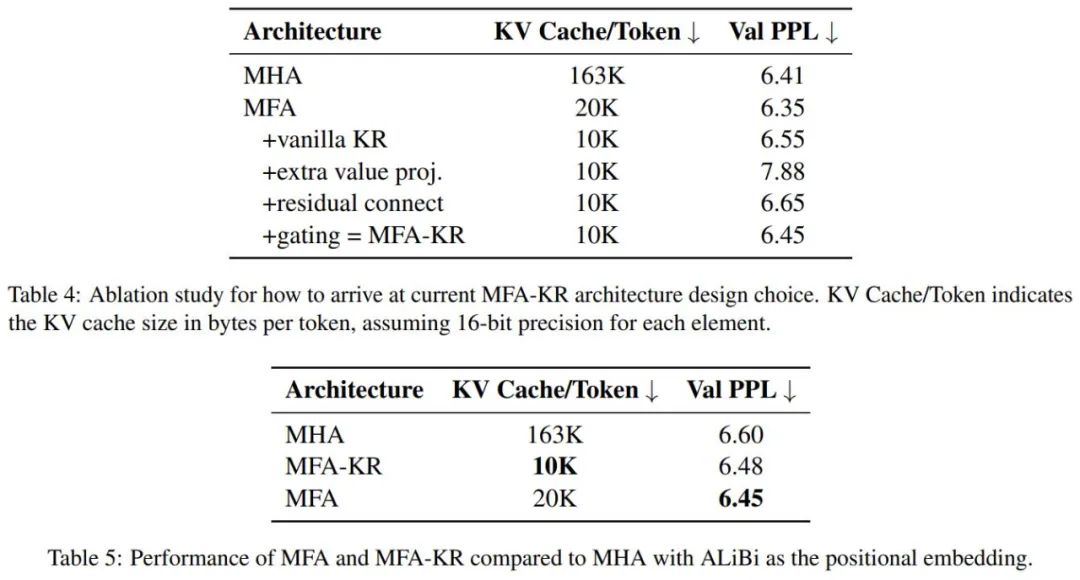
实验中,MFA 和 MFA-KR 不仅超越了 MLA 的性能,还在减少了高达 93.7% 的 KV Cache 使用量的情况下,与传统的 MHA 性能相当。于此同时,MFA 实现简单,容易复现,对超参敏感度低,且兼容各种 Pos-embedding。
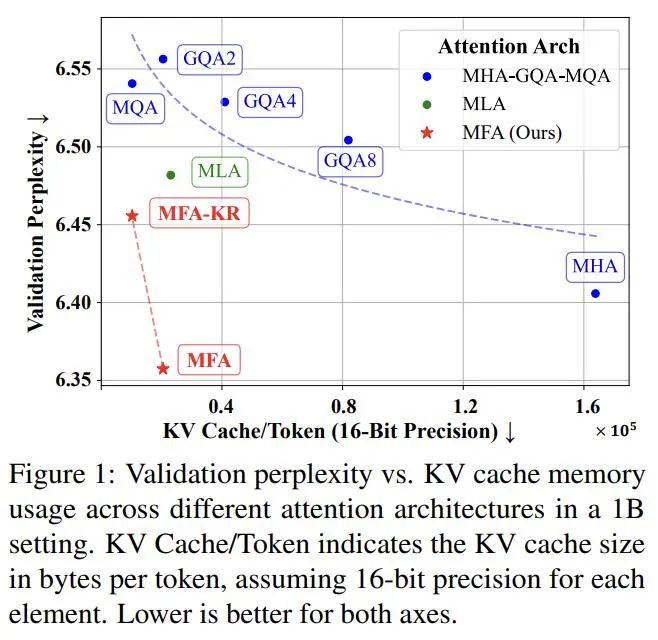
MFA 方法与分析
研究团队通过研究 Attention 机制的一般性设计和容量分析,明确了 Attention 机制的容量最相关的两个维度,并且提出了一系列的分析方法和设计原则。
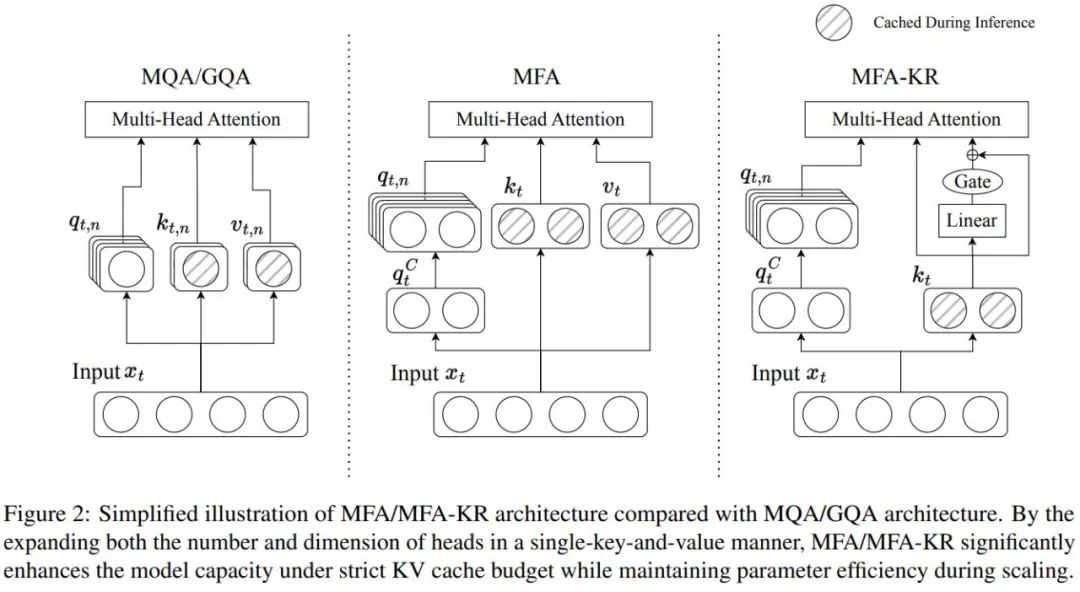
为了更好地理解注意力机制的本质,研究团队提出了广义多头注意力(GMHA)的概念框架,为理解不同的 MHA 变种注意力机制提供了一个统一的视角。进一步地,研究团队分别从推理角度研究键值的计算和存储方式,从分解角度探讨模型的容量特征。这种创新的分析方法为理解不同策略如何在模型性能和计算效率之间取得平衡提供了全新视角。
在此基础上,研究者们确立了完全参数化双线性注意力(FPBA)作为理论上的性能上限标准。他们发现,目前广泛使用的 MHA 及其各种变体实际上都可以被视为 FPBA 的低秩分解版本。研究团队在分析现有解决方案时,重点考察了两个代表性的改进方案:多查询注意力(MQA)和多头潜在注意力(MLA)。
对于 MQA,研究人员发现它采用了一种更激进的参数共享策略。不同于 MHA 在头部之间保持独立的参数,MQA 让所有注意力头共享同一组键值参数。这种设计虽然将内存使用降到了极低的水平,但可能会影响模型的表达能力。研究团队指出,这种权衡实际上反映了一个更普遍的设计困境:如何在保持模型性能的同时减少资源消耗。
而对于更新的 MLA 方案,研究人员发现它采用了更为复杂的架构设计。MLA 引入了一个共享的潜在空间,通过在这个空间中进行参数压缩来节省内存。虽然这种设计看似提供了更大的灵活性(因为中间维度可以设置得更大),但研究团队的理论分析揭示了一个关键问题:模型的实际表达能力仍然受限于最小维度的约束,这意味着 MLA 的设计中增加中间维度并不能真正提升模型的性能上限。
在深入分析现有方案的基础上,研究团队提出了一个雄心勃勃的目标:开发一种新的注意力机制,既能最大限度地节省资源,又能尽可能接近理论性能上限。这个目标促使他们开发出了多矩阵分解注意力(MFA)。
MFA 的设计体现了研究团队的三个关键创新:
首先,他们突破传统设计的局限,显著增加了注意力头的数量和维度,极大增加了注意力模块的模型容量。
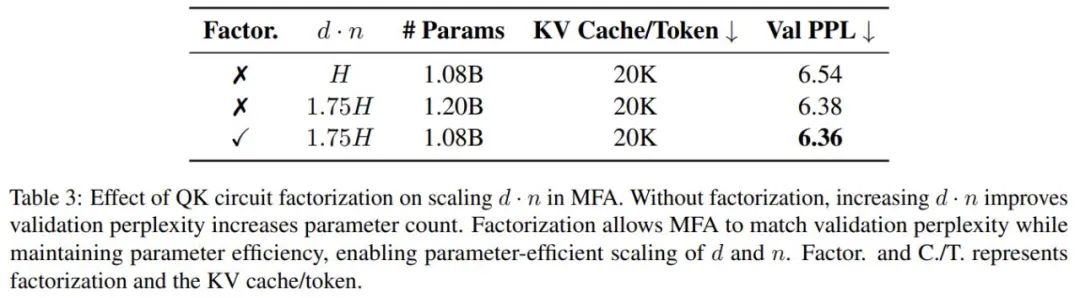
其次,研究团队在矩阵分解方面实现了创新性突破,采用激进的低秩分解策略,成功地在扩展模型注意力头的数量和维度时保持了极高的参数效率。
最后,研究团队采用单键值头设计,这个设计确保了即使在增加模型复杂度的情况下,内存使用仍然保持在最低水平。
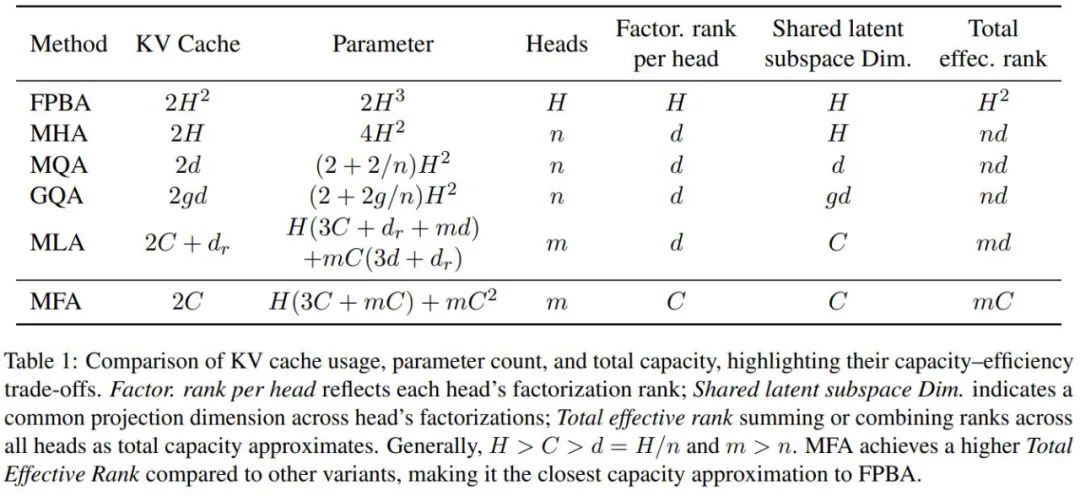
为了进一步分析 MFA 和其他注意力机制的不同,研究团队提供了一个清晰的对比表格。研究人员首先引入两个关键指标来度量 GMHA 系列模型的容量:模型总有效秩 TER ( Total Effective Rank ) 和 共享隐空间维度 SLSD(Shared latent subspace dim)。总有效秩 TER 定义为注意力头数量与每个头部分解秩(Factorization rank per head,简称 FRH)的乘积,而共享隐空间维度 SLSD 则代表了所有注意力头共同使用的隐空间维度,注意到 TER 和 SLSD 越大,模型具有更高的容量。同时注意到每个头的分解秩(FRH)不超过 SLSD,而 KV Cache 的占用受制于 FRH 和 SLSD 之间的较大值,这构成了容量和效率之间的关键权衡。
通过这个框架进行分析,可以发现与 MQA 相比,MFA 同时实现了更高的 SLSD 和更高的 TER;与 MLA 相比,在相似的参数预算下,MFA 不仅达到了更小的 KV cache 尺寸,还实现了更高的 TER,同时保持了相当的 SLSD;与传统的 MHA 相比,虽然 MFA 的 SLSD 较小,但它的 TER 更高,这解释了为什么在实验中 MFA 能够获得更好的性能。
实验结果
为了研究新架构在可能的更大规模上的表现,研究团队开展了一系列深入的扩展性实验,系统地测试了从 1B 到 7B 参数的不同规模的模型,训练数据量从 10B 扩展到 1T。在性能扩展方面,研究团队的 MFA 方案展现出与传统 MHA 完全相当的扩展能力。这意味着,即使在更大规模下,MFA 依然能保持其优异的性能。而 MFA-KR 虽然在性能上略有降低,但其扩展趋势与 MHA 保持一致。而随着模型规模的增加,MFA 和 MFA-KR 在内存节省方面的优势不仅得到保持,还呈现出进一步扩大的趋势。在最大规模模型上,MFA 实现了 87.5% 的内存节省,而 MFA-KR 更是将内存使用降低到原来的 6.25%。
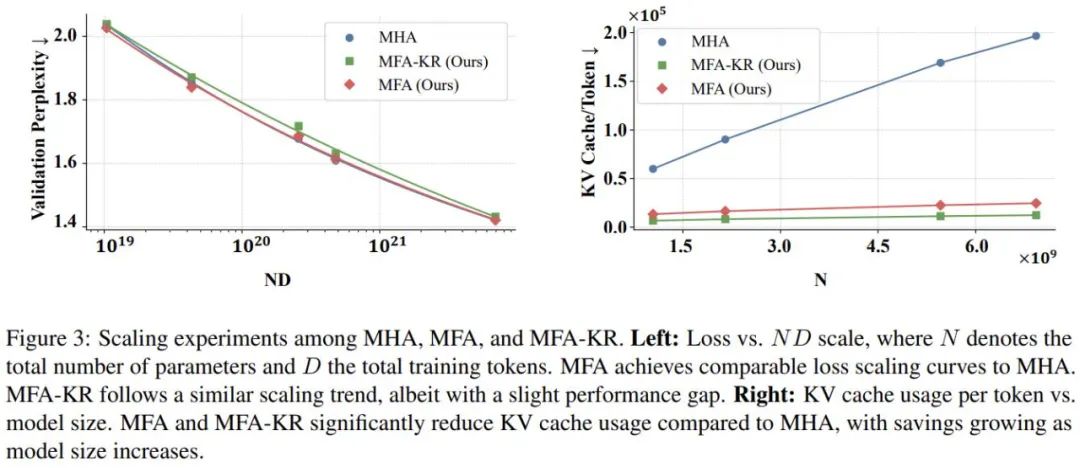
研究人员还进行了一系列的消融实验,证明 MFA 和 MFA-KR 的设计的有效性,并在其他的主流的位置编码上也验证了 MFA 和 MFA-KR 的性能优势。
展望
MFA 用最简洁的设计带来了最显著的提升,在不增加额外工程复杂度的前提下,优雅地解决了 LLM 的高效推理显存瓶颈问题,并能无缝集成到现有的 Transformer 生态中。这种简单而强大的创新,必将加速大语言模型在更多场景中的落地应用。
那么你觉得这项关于注意力机制的研究如何呢?欢迎在评论区留言讨论。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











