




目前大语言模型(Large Language Models, LLMs)的推理能力备受关注。从思维链(Chain of Thought,CoT)技术提出,到以 o1 为代表的长思考模型发布,大模型正在展现出接近人类甚至领域专家的水平,其中数学推理是一个典型任务。
然而,与大模型能够理解和求解各种复杂数学问题相对的,是其羸弱的数字处理能力。尽管大模型能够提出看似合理的解决方案,但在实际运算之中,却常常难以在不借助工具的情况下计算出准确的数值结果。此前引发广泛讨论的 “9.11>9.9” 就是典型例子。这种 “事实幻觉” 已经成为制约大模型实际应用的一个重大障碍。
过去的研究工作很少将 “数字理解和处理能力”(Number Understanding and Processing,NUPA)作为独立任务进行研究。以往的研究更多聚焦于数学推理,涉及数学工具和定理应用,例如 GSM8K。对于数字本身的基础理解和处理,如四则运算、比较大小、数位提取等,鲜有研究将其单独衡量。同时,在现有的数学数据集中,数字相关的部分往往被简化处理。许多数据集中的数字通常仅限于简单的整数和小数,而较长的整数、小数和分数等较复杂的数字形式往往被忽视,这与现实中复杂多变的应用场景存在较大差距。实际应用中,若遇到涉及更复杂任务的情况,如金融、物理等领域的应用,这种简化后的数字能力可能无法有效应对。
尽管大模型可以通过调用外部计算器一定程度上弥补数字处理能力的不足,这个问题本身仍然值得深入探讨。首先,考虑到数字处理作为各种复杂推理的基础,在涉及高频数字处理的情况下频繁调用外部工具会显著减慢模型响应,模型应当具备自我解决较为简单问题的能力(如判断 9.11 < 9.9)。更重要的是,从发展通用人工智能的角度出发,如果模型不具备最基础的数字理解能力而只能依赖计算器,那么不可能指望其真正掌握复杂推理、帮助人类发现新定理或发明新工具,达到人类级别的通用智能更是无从谈起。这是因为,人类正是在充分理解、掌握数字和运算的基础上才发明的计算器。
近日,北京大学张牧涵团队在投稿至 ICLR-2025 的论文中,关注了这一问题。作者将数字理解和处理能力(number understanding and processing ability, NUPA)从数学或常识推理能力等任务中分离出来,单独衡量大模型的数字能力。基于中小学数学课本范围,作者提出了一个涉及四种数字表式(整数、浮点数、分数、科学计数法)和四个能力范畴下的 17 个任务类型,共计 41 个数字理解和处理任务的基准集 NUPA(图 1)。这些任务基本覆盖了日常生活中常用的数学知识(如计算、大小比较、单位转换、位操作等),亦是支撑 AGI 的必要能力之一。

论文标题:Number Cookbook: Number Understanding of Language Models and How to Improve It
论文地址:https://arxiv.org/abs/2411.03766
项目主页:https://github.com/GraphPKU/number_cookbook

图 1:NUPA benchmark 的 41 个任务;其中√表示包括的任务;—, O, X 分别表示因不适用、可由其它任务组合得到、以及因过于复杂而不实际,而被排除的任务。
现有大模型性能测试
作者首先在不借助额外工具和思维链帮助的情况下,测试了模型在不同难度(数字长度)下的表现。部分结果如图 2 所示,准确率根据生成的数字与基准答案的严格一致来评估。测试涵盖了多种常见的大模型,包括 GPT-4o、Llama-3.1、Qwen(千问)-2、Llama-2、Mixtral。测试结果显示,最新的大模型在常见的数字表示、任务和长度范围表现良好。如图 2 所示,在整数加法这一典型任务上,以及较短数字长度(1-4 位)情况下,各模型的准确率均超过 90%,其中,GPT-4o、Qwen2-72B 等模型甚至达到了接近 100% 的准确率。在浮点数加法、整数大小比较、整数长度判断等任务上,各模型也普遍展现出超过 90% 的准确率。

然而,涉及稍微复杂或者不常见的数字表示或任务时,模型的性能明显下降。图 3 进一步展示了部分任务上的准确率,S、M、L、XL 分别对应从短到长不同的数字长度范围(所示任务分别对应 1-4 位、5-8 位、9-14 位、15-20 位)。尽管大部分模型在较短的数位范围内能够较好地解决整数和浮点数的加法问题,但在分数和科学计数法的加法上,模型的表现很差,准确率普遍低于 20%。此外,当任务涉及乘除运算、取模运算等稍微复杂的运算时,即使是在较短的长度范围内,大模型也难以有效解决问题。


同时,数字长度仍然是大模型尚未解决的难题,从图 3 中可以看出,随着数字长度的增加,模型性能明显下降。以整数加法为例,当输入数字长度达到 9-14 位(即图中 L 范围)时,除 GPT-4o 和 Qwen2-72B 的准确率维持在约 40% 外,其余模型的准确率仅约为 10%;而当涉及 15-20 位整数的加法(图中 XL 范围)时,GPT-4o 和 Qwen2-72B 的性能进一步下降至约 15%,其余模型几乎无法给出正确答案。
此外,这一测试还发现大模型在处理最简单的数位相关任务时存在明显不足。具体而言,在诸如 “数字长度”(length)、“返回给定数位的数字”(get digit)、“数位比较大小”(digit max)等任务上,模型的表现均不能令人满意,尤其是在数字较长时,性能下降尤为明显。例如,当询问一个长 60-100 位长整数的长度和特定数位的数字时,包括 GPT-4o 在内的模型准确率均不超过 20%;而在 digit max 任务上,几乎所有模型均无法正确回答。考虑到数位是数字处理中的基本概念,这表明现有大模型在数字处理上存在本质缺陷,这也可能是模型在实际任务中频繁出现 “事实幻觉” 的原因。

作者在原文中还提供了更多的观察,并基于更多任务、长度范围和准确度度量的进行了分析。此外,考虑到该测试涉及数字表示、任务类别、数字长度和度量等多个方面,作者还提供了一个可交互式的网站,便于更清楚地展示结果,详情请访问:https://huggingface.co/spaces/kangshijia/NUPA-Performance。
提升大模型数字能力的三个方面
测试结果显示,现有大模型在数字理解和处理方面存在系统性不足。为此,作者研究了提升大模型数字理解能力的三个方向,包括预训练阶段的数字相关技术、预训练后的微调,以及思维链技术。
预训练中分词器对数字性能的影响
首先,一种普遍的猜想是,大模型在数字能力上的薄弱与其对数字的分词(tokenization)方式有关。目前大多数流行的大模型由于词汇表固定,需要将长数字分拆为多个 token,这种方式可能会削弱模型对数字的理解。在早期的 GPT-2 和 GPT-3 等模型中,采用的 BPE tokenizer 对数字分词没有特殊优化。这种分词方式会生成不固定长度的数字 token,研究已证明这对大模型的数位对齐有负面影响 [1]。后续的 Llama 等模型均采用了从左到右的贪心式分词器,其机制是对于预设的最大长度 k,从左到右依次截取 k 个数字组成一个 token,直至遇到非数字字符为止。在 k 的选取上,较早的 Llama-2 模型采用 k=1,即每个数位作为一个 token 的策略;而更新的 GPT-3.5,GPT-4 和 Llama-3 均选取了 k=3 的策略。近来的研究 [1] 又进一步改进了分词方向,将整数部分的分词方向改为从右到左,以更贴合人类对数字的理解习惯。

图 5:四种不同的分词器设计,从上到下分别为(a)GPT-2 使用的未经处理的 BPE 分词器、(b)Llama-2 使用的单数位分词器、(c)Llama-3 和 GPT-3.5、GPT-4 使用的 3 数位贪心分词器,以及(d)改进对齐后的 3 数位分词器。
尽管针对分词器的设定有所不同,但最新模型普遍倾向于使用更大的词汇表,即更大 k 和更长的 token。然而,这一趋势未经充分验证和解释。为此,作者基于 NUPA 提供的数据集,针对不同的分词器大小进行了系统验证。实验中,作者改进对齐分词器,设置 k 为 1、2、3,分别训练不同参数规模的 Transformer 模型,并在 1-8 位整数或浮点数的加法、乘法等任务上进行学习,再测试其在 1-20 位数字任务上的性能。实验结果显示(图 6),无论是在训练的数字长度范围内(in-domain)还是超出训练长度(out-of-domain)的长度泛化性能上,词汇表更小的分词器(k=1)的性能均优于或接近 2 位或 3 位分词器,同时具备更快的收敛速度。

图 6:以整数乘法为例,1-3 位分词器的性能对比;横轴为训练所见样本数,纵轴为生成准确率;从左到右分别为 6 位 - 10 位数字加法的测试集准确率。
此外,作者还研究了最近提出的概率分词器(即在分词时不采用贪心算法,而是随机取不超过 k 个数字组成一个 token)。实验结果表明,尽管概率分词器在长度泛化上表现出一定优势,但总体性能仍然不如一位分词器。综上,作者认为,目前流行的扩大数字词汇表的倾向实际上不利于数字处理,相反,更早期的一位分词器可能才是更优选项。
其它预训练中的数字相关技术
除分词器的影响之外,过去的研究还从位置编码(positional encoding,PE)和数字格式等角度分析了数字能力,特别是在数字的长度泛化方面。作者在 NUPA 任务上测试了这些典型技术,结果显示:
从位置编码的角度,以 NoPE 和 Alibi 为代表的改进型位置编码能够有效解决长度泛化问题。这些方法适用于多种数字表示和任务类型,虽然会牺牲一定的训练速度,但能提升模型在超出训练长度范围时的性能。
针对数字格式,研究发现补零对齐(zero-padding)和反向数字表示(reverse representation)等技术有助于数位对齐。其中,仅针对整数部分进行反向表示能够显著提升结果。这一部分的结论较多,感兴趣的读者可以参考原文进行深入阅读。

后训练微调对数字性能的影响
微调是提升大模型在特定任务上表现的常见方法。作者针对 NUPA 进行了微调实验,使用 NUPA 提供的 41 个任务构建了包括多种数字表示、任务类型和数字长度的训练集,并在 Llama-3.1-8B 基础上进行参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)。为了测试数字长度上的泛化性能,作者只选择了 S 和 M 两个长度范围进行训练,并在 S、M、L、XL 四个长度范围内进行测试。
训练结果表明,模型通过少量的训练步数(约两千步)即可显著提升性能,如图 6 所示,经过微调的模型在多个任务上表现明显优于未经微调的 Llama-3.1-8B 模型;在一些任务上,微调后的模型甚至接近 GPT-4o 或超过了 GPT-4o 的性能。这表明,模型在某些任务上表现较差的原因可能是缺乏足够多样的任务和数字表示训练数据。增加这些数据有望改善模型表现。然而,即使经过微调,该模型的准确率也未能达到在整个区间上达到接近 100% 的水平。


然而,在后训练阶段,尝试通过微调调整位置编码、分词策略或数据格式的实验并未得到正面结果。具体而言,作者在微调阶段尝试修改原始模型使用的位置编码、分词器,或采用修改后的数字格式,但不同技术组合的微调结果均不如直接微调的结果,且改动越多性能下降越明显。作者认为,这可能与预训练阶段与微调阶段之间的差异过大有关。这表明,目前提出的大部分技术无法在微调阶段直接使用,因此必须在预训练阶段就考虑使用。
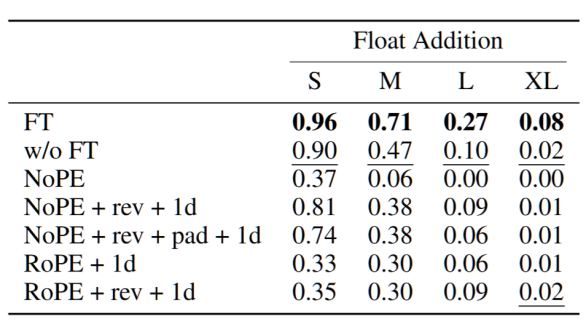
图 9:以浮点数加法为例,其中 rev 表示数字反向表示、pad 表示数字首位补零对齐,1d 表示使用 1 位 tokenizer;FT 和 w/o FT 分别为直接进行微调和不使用微调的原始参数。模型均采用 Llama-3.1-8B,可以看到所有组合的结果都劣于直接进行微调。
思维链是否足以解决数字处理难题
上述实验是在不使用思维链的情况下进行的,考虑到数字处理任务通常是更复杂任务的基础,生成思维链可能会导致过长的输出或分心。然而,考虑到思维链方法对推理任务普遍有效,作者进一步测试了思维链技术是否能够解决数字处理问题。
具体而言,作者采用了一种名为 “规则跟随”(Rule-Following)的思维链范式,将明确的计算规则以代码的方式提供给大模型,模型微调后按照这些规则解决问题。实验结果表明,训练得到的具有规则跟随能力的模型性能上普遍超过 GPT-4o 及一般微调的 Llama-3.1-8B。然而,该模型的推理时间、显存开销较大,使用思维链生成的平均耗时是直接生成的 10 倍以上,且容易受到显存或上下文长度限制,导致无法解决较长的问题。这表明,思维链技术并非解决数字处理问题的万能方法。

图 10:规则跟随的思维链大模型具有远超直接生成的性能,但受到长度限制明显,“-” 表示在两千个 token 限制内无法生成答案。

总结
本文提出了一系列独立于数学问题和常识问题之外的数字理解和处理任务,涵盖了 4 种数字表示和 17 种任务类型,并对常见的大模型进行了评测。结果表明,现有大模型在数字理解和处理方面的性能仍然局限于最常见的任务和较短的数字范围。作者从预训练技术、训练后微调和思维链三个方面探索了提升数字处理能力的可能性。尽管一些方法在提升模型性能上有一定效果,但仍存在不足,离彻底解决数字处理问题还有一定距离。
作者指出,大模型目前被视为通向 AGI 的重要工具,尽管其在解决最复杂问题的高级能力方面备受关注,但 “数字处理” 等基础能力的研究同样不可忽视,否则推理和思维将成为空中楼阁。作者希望本文提供的任务和数据集能够为大模型提升数字处理能力提供有力支持,并以此为基础进一步加强其在数学等领域的表现。这些任务和数据集,可以有效地为预训练过程中引入更多样的数字相关任务提供参考,也可以启发更好的数字分词、编码、格式处理等新技术的提出。
[1] Aaditya K. Singh, DJ Strouse, Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs. 2024



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











