




AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇综述的作者团队包括亚利桑那州立大学的博士研究生李大卫,蒋博涵,Alimohammad Beigi, 赵成帅,谭箴,Amrita Bhattacharje, 指导老师刘欢教授,来自伊利诺伊大学芝加哥分校的黄良杰,程璐教授,来自马里兰大学巴尔的摩郡分校的江宇轩,来自伊利诺伊理工的陈灿宇,来自加州大学伯克利分校的吴天昊以及来自埃默里大学的舒凯教授。
摘要:评估和评价长期以来一直是人工智能 (AI) 和自然语言处理 (NLP) 中的关键挑战。然而,传统方法,无论是基于匹配还是基于词嵌入,往往无法判断精妙的属性并提供令人满意的结果。大型语言模型 (LLM) 的最新进展启发了 “LLM-as-a-judge” 范式,其中 LLM 被用于在各种任务和应用程序中执行评分、排名或选择。本文对基于 LLM 的判断和评估进行了全面的调查,为推动这一新兴领域的发展提供了深入的概述。我们首先从输入和输出的角度给出详细的定义。然后,我们介绍一个全面的分类法,从三个维度探索 LLM-as-a-judge:评判什么(what to judge)、如何评判(how to judge)以及在哪里评判(where to judge)。最后,我们归纳了评估 LLM 作为评判者的基准数据集,并强调了关键挑战和有希望的方向,旨在提供有价值的见解并启发这一有希望的研究领域的未来研究。

论文链接:https://arxiv.org/abs/2411.16594
网站链接:https://llm-as-a-judge.github.io/
论文列表:https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge
文章结构

LLM-as-a-judge 的定义

在这篇工作中,我们提出根据输入和输出格式的区别对 LLM-as-a-judge 进行了定义。首先,根据输入候选样本个数的不同,在输入的层面 LLM-as-a-judge 可以分为逐点和成对 / 列表输入;另外,根据模型输出格式的不同,在输出的层面 LLM-as-a-judge 的目的可以分为评分,排序和选择。
Attribute:评判什么

LLM-as-a-judge 已经被证明可以在多种不同类型的属性上提供可靠的评判,在这个章节中,我们对他们进行了总结,它们包括:回复的帮助性,无害性,可靠性,生成 / 检索文档的相关性,推理过程中每一步的可行性,以及生成文本的综合质量。
Methodology:如何评判

(1)微调:最近许多工作开始探索如何使用微调技术来训练一个专门的评判大模型,我们在这一章节中对这些技术进行了总结归纳,包括它们的数据源,标注者,数据类型,数据规模,微调技术及技巧等(表 1)。其中我们根据数据来源(人工标注和模型反馈)和微调技术(有监督微调和偏好学习)对这些工作进行了详细讨论。

(2)提示:提示(prompting)技术可以有效提升 LLM-as-a-judge 的性能和效率。在这一章节中,我们总结了目前工作中常用到几类提示策略,分别是:交换操作,规则增强,多智能体合作,演示增强,多轮动态交互和对比加速。
Application:何时评判
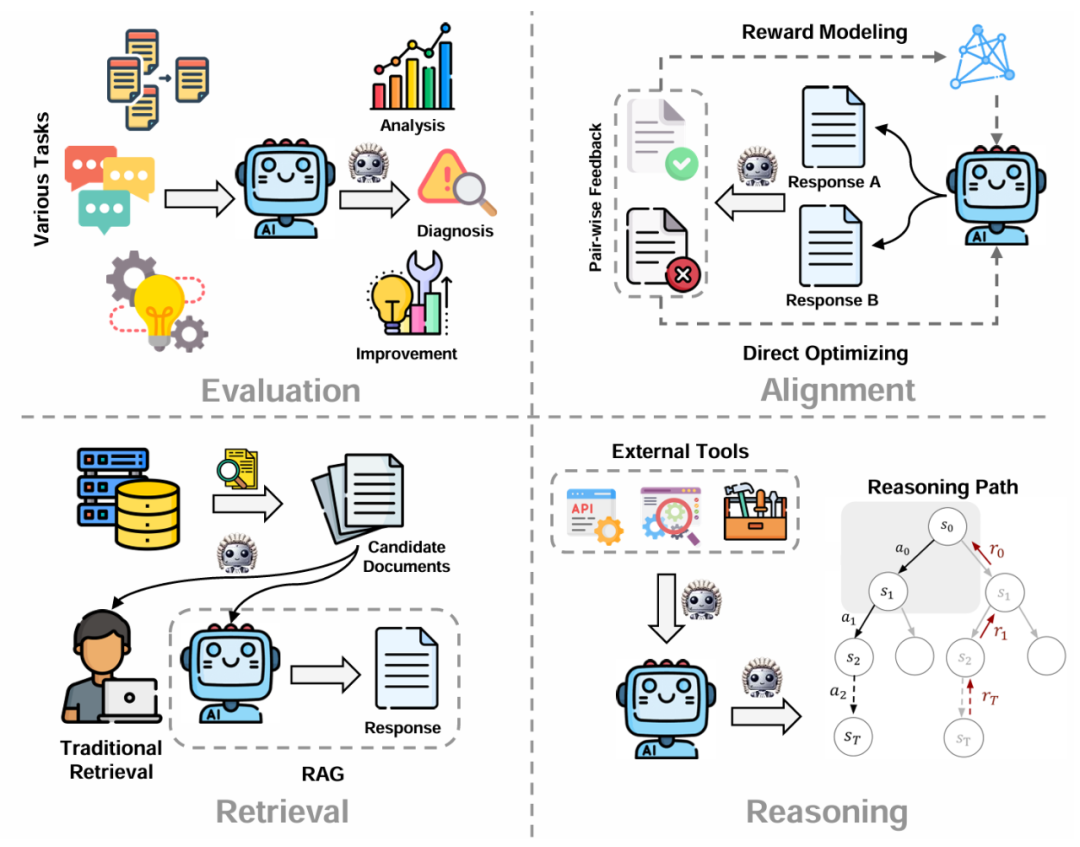
(1)评估:传统 NLP 中的评估通常采用静态的指标作为依据,然而它们常常不能够很好的捕捉细粒度的语义信息。因此,LLM-as-a-judge 被广泛引入到模型评估的场景中,进行开放式生成,推理过程以及各种新兴 NLP 任务的评测。
(2)对齐:对齐技术通常需要大量人工标注的成对偏好数据来训练奖励或者策略模型,通过引入 LLM-as-a-judge 技术,采用更大的模型或者策略模型本身作为评估者,这一标注过程的时间和人力成本被大大优化。
(3)检索:检索场景同样得益于 LLM-as-a-judge 对于文本相关性和帮助性强大的判别能力。其中对于传统的检索应用,LLM-as-a-judge 通过判断文档和用户请求的相关性来选择最符合用户喜好的一组文档。另外,LLM-as-a-judge 还被应用于检索增强生成(RAG)的过程中,通过 LLM 自己来选择对后续生成最有帮助的辅助文档。
(4)推理:在推理过程中,LLM 在很多场景下会被赋予使用工具,API 或者搜索引擎的权限。在这些任务中,LLM-as-a-judge 可以依据当前的上下文和状态选择最合理可行的外部工具。另外,LLM-as-a-judge 还被广泛引用于推理路径的选择,通过过程奖励指导模型进行状态步骤转移。
基准:评判 LLM-as-a-judge
如表 2 所示,我们总结了不同针对 LLM-as-a-judge 的基准测试集,并从数据 / 任务类型,数据规模,参考文本来源,指标等多个方面对这些数据集做了总结归纳。其中,根据基准测试集目的的不同,大致可以分为:偏见量化基准,挑战性任务基准,领域特定基准,以及其他多语言,多模态,指令跟随基准等等。

展望:挑战和机遇
(1)偏见与脆弱性:大模型作为评判者,一直受困扰于各种各样影响评价公平性的偏见,例如顺序偏见,自我偏好偏见,长度偏见等。同时,基于大模型的评价系统在面对外部攻击时的鲁棒性也存在一定不足。因此,LLM-as-a-judge 未来工作的一个方向是研究如何揭露和改善这些偏见,并提升系统面对攻击的鲁棒性。
(2)更动态,复杂的评判:早期的 LLM-as-a-judge 通常只采用比较简单的指令来 prompt 大模型。随着技术的发展,越来越多复杂且动态的 LLM-as-a-judge 框架被开发出来,例如多智能体判断和 LLM-as-a-examiner。在未来,一个有前景的研究方向是开发具有人类评判思维的大模型智能体;另外,开发一个基于大模型自适应难度的评判系统也很重要。
(3)自我判断:LLM-as-a-judge 长期以来一直受困扰于 “先有鸡还是先有蛋” 的困境:强大的评估者对于训练强大的 LLM 至关重要,但通过偏好学习提升 LLM 则需要公正的评估者。理想状况下,我们希望最强大的大模型能够进行公正的自我判断,从而不断优化它自身。然而,大模型具有的各种判断偏见偏好使得它们往往不能够客观的评价自己输出的内容。在未来,开发能够进行自我评判的(一组)大模型对于模型自我进化至关重要。
(4)人类协同大模型共同判断:直觉上,人工的参与和校对可以缓解 LLM-as-a-judge 存在偏见和脆弱性。然而,只有少数几篇工作关注这个方向。未来的工作可以关注如何用 LLM 来进行数据选择,通过选择一个很小但很具有代表性的测试子集来进行人工评测;同时,LLM-as-a-judge 也可以从其他具有成熟的人机协同方案的领域受益。
总结
本文探讨了 LLM-as-a-judge 的惊喜微妙之处。我们首先根据输入格式(逐点、成对和列表)和输出格式(包括评分、排名和选择)对现有的基于 LLM-as-a-judge 进行定义。然后,我们提出了一个全面的 LLM-as-a-judge 的分类法,涵盖了判断属性、方法和应用。此后,我们介绍了 LLM-as-a-judge 的详细基准集合,并结合了对当前挑战和未来方向的深思熟虑的分析,旨在为这一新兴领域的未来工作提供更多资源和见解。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











