




近日,在 2024 Inclusion・外滩大会 “超越平面思维,图计算让 AI 洞悉复杂世界” 见解论坛上,蚂蚁集团知识图谱负责人梁磊分享了 “构建知识增强的专业智能体” 相关工作,并带来了知识图谱与大模型结合最新研发成果 —— 知识增强大模型服务框架 KAG。
梁磊介绍,专业领域增强大模型服务框架 KAG 通过图谱逻辑符号引导决策和检索,显著提升了垂直领域决策的精准性和逻辑严谨性;通过信息检索可补全知识图谱的稀疏性和知识覆盖的不足,同时充分利用大语言模型的理解和生成能力降低领域知识图谱的构造门槛。KAG 框架在垂直领域的适用性得到了有效验证。比如,支付宝最新推出的 AI 原生 App “支小宝” 采用这套框架,在政务问答场景的准确率提升到了 91%,医疗问答垂直的指标解读准确率可达 90% 以上。梁磊还透露,KAG 框架会进一步向社区开放,并在开源框架 OpenSPG (https://github.com/OpenSPG/openspg) 中原生支持,也欢迎社区共建。
以下是梁磊在外滩大会上的演讲内容摘要,机器之心做了不改变原意的整理。
1、可信是大语言模型真正落地应用的前提
大语言模型有着很好的理解和生成能力,在垂直领域的应用有巨大的机会,但同时也存在着非常大的挑战。比如在垂直领域跟专家经验、一些具体业务结合的时候,依然存在着不懂领域知识、做不了复杂决策、不可靠等问题。

首先,大语言模型本身不具备比较严谨的思考能力。在一些测试中,我们让大语言模型做复杂问题的拆解,问两部电影之间的共同主演是谁,结果显示总体上回复的准确性和一致性相对较低,甚至还有一些拆解错误。这种情况下,大语言模型很难严格遵从人类的指令。此外,大语言模型还存在事实性不足的问题。今年以来行业尝试把 RAG、搜索引擎之类的技术引入到大语言模型,来补充事实性不足的问题,以及 GraphRAG,用图的方式去重新组织它的检索。但问题是,即便引入了一些外部知识库,把一些垂直领域的知识库和事实文档给到语言模型,模型也不见得能够完全生成一个准确的答案。
除此以外,大模型在外部知识库召回的时候,也依然会存在召回不准的问题。举个基于向量计算的 RAG 的例子。比如问 “怎么查找我的养老金”,常见的有两种做法,一种是直接基于向量计算去召回文档,但是往往和业务专家定义的知识不相关。但在垂直领域,有很多知识在字面上不相似,但却是很相关的。比如政策明确规定了五险一金的范围,大模型不能对这些内容做胡乱生成,这就必须有一些预定义的领域知识和预定义的知识结构,来约束大模型的行为,甚至给它提供一个更有效的知识注入,而这些都是模型在文本上不相似,但却是强相关的。在这种情况下,今年讨论引入知识图谱技术的也越来越多。通过知识图谱的语义相关性来提升模型内容的相关性,以此可以做更好的语义计算和语义的召回。
大模型幻觉也是阻碍应用的关键挑战之一。那么,引入了 RAG、知识库之后,大模型就能解决幻觉问题了吗?其实不然,而且有些幻觉问题不仔细观察便难以察觉。举个例子,比如原文提到功能饮料中的维生素、矿物质等,对运动后补充身体营养、消除疲劳具有一定作用,而大模型重新生成以后,可能会改写成对于增加疲劳有一定作用。这种其实就会给一个错误的引导,但这种错误的引导,尤其是大模型生成的文案可能是几百字,甚至上千字的,这时候就很难从里面观察到这类细节问题。通过测评发现,大语言模型即便是加入 RAG 以后,依然有大概 30% 到 40% 的幻觉率。
在真实业务决策场景,挑战就更多了。以金融场景为例,无论是研报生成,还是医疗问诊等等,业务上都有比较严格的问题规划、信息获取、决策建议,甚至生成和反馈的过程。也就是说,因为大语言模型还是要为人类服务,应用在一个个垂直业务场景,每一类都需要准确的决策过程,如果这个决策过程不能得到很好的控制的话,就很难真正意义上用在垂直领域。在专业性的知识服务场景,大语言模型服务的首要前提是知识精准。这就包括知识的边界是完备的,知识的结构及语义清晰、逻辑严谨。另外,在垂直领域落地,也一定要对时间、数字和逻辑敏感,无论让它做多跳推理,还是逻辑规则数字计算,而这些恰好是大语言模型所不擅长的,包括前一段时间热议的 9.9 和 9.12 比大小的例子。
基于此,我们认为在垂直领域落地的时候,大语言模型一定确保专业和可信。可信是大语言模型真正意义上落地的前提。如果不能保证可信,我们可能不会迎来真正意义上的 AGI 的变革。这也是蚂蚁为什么要做知识增强的重要原因。
2、KAG:专业领域知识增强大模型服务框架
应对大模型在真实应用场景遇到的挑战,蚂蚁研发了基于知识增强在垂直领域的可控生成框架 KAG。

KAG 可控生成框架是基于开源系统 OpenSPG 升级,并且结合了蚂蚁自研的图数据库 TuGraph-DB 的能力。TuGraph-DB 作为 KAG 中知识图谱 SPG 的底层图引擎,为 KAG 提供了高效的知识存储与检索能力。KAG 将抽取的知识存储于 SPG 中,由 TuGraph-DB 提供图存储;在检索流程中,SPG 通过 TuGraph-DB 的 Cypher 接口检索与用户提问相关的知识信息,并将结果反馈给大模型生成回答。
KAG 框架针对大语言模型和图谱的结合做了五方面的增强:分别是知识表示的增强、图结构与文本互索引、符号引导的拆解和推理、基于概念的知识对齐、KAG Model。具体包括以下关键能力:
1) KAG: LLMs 友好的知识表示
今年,我们对语义表示进行了升级,旨在进一步发展 OpenSPG 项目,推动知识图谱从静态二元结构向多元动态结构持续升级。通过原始文本增强深度上下文感知,我们实现了更丰富的可解释文本的知识关联,对大语言模型也更友好,同时,参考 DIKW 层次范式在同一实体空间中支持 Schema 约束、无模式建模及文本结构的分层表示。

同时,我们探讨了 GraphRAG 范式的两种主要实现:微软的 GraphRAG 和 HippoRAG。尽管微软的 GraphRAG 在摘要生成类任务上有不错表现,但在事实问答准确率上表现不佳。而 HippoRAG 通过图结构构建倒排索引,显著提升了文档召回的相关性和事实问答的准确性。我们的目标是在专业领域内实现准确的事实性回答和报告生成,融合不同层级知识创建从严格到宽松的决策范式。
2) 互索引:结构化知识与文本数据互索引结构
我们将原有的 term-based 倒排索引升级为 graph-based 倒排索引,通过开放信息抽取获取原始文档中的关键元素和描述性信息,进行有效的语义切分,最终形成一个包含业务实体、通用概念知识和文本块的图结构。这种结构不仅便于遍历和检索文本块,还能有效分析文档间的关联。

3) 混合推理:符号决策、向量检索与大模型混合推理
我们在 KAG 中构建了一个混合推理引擎,旨在解决知识图谱在严谨决策中的应用问题。目标是开发一套技术范式,支持复杂推理决策的执行,同时通过信息检索来弥补知识图谱的不足。

该框架采用符号驱动的方法生成逻辑可执行的查询表达式(Logic form Query)。通过图结构操作,利用分层知识进行决策:先在逻辑知识层检索,若无解则转向开放信息层,再通过关联文档检索提高召回率和准确性。在生成阶段,我们应用 query-focused summary 方法,以通过查询结构提取答案,解决传统知识图谱与用户查询的粒度匹配问题。同时,基于知识图谱的反馈有助于抑制语言模型生成中的幻觉,提高准确性。系统将问题拆解为逻辑符号表达,可转化为 KGDSL 或 GQL。我们的两阶段规划包含图谱存储中的精确匹配和 SPO 子图检索,最后集成知识图谱以减轻幻觉。通过文本抽取的三元组注入语言模型,在生成时遵循结构范式,有效降低幻觉率。这种方法在内部业务中如区域风险报告生成中已显著改善,我们将继续深入探索这一方向。
4) 语义对齐:平衡信息检索与专业决策
问题的关键在于如何有效整合信息检索和专业决策。信息检索允许一定的错误率,而专业决策对准确性要求则是严格的。因此,我们通过开放信息抽取构建结构化知识,并应用 schema 约束以提升决策的严谨性。此外,基于概念的语义对齐让我们能兼顾这两者,形成一个基于 SPG 的领域知识图谱,从而改善信息检索和专业决策的能力。

我们通过传统图谱方法,如实体链接和概念分层等,提升了图结构的稠密性和语义完备性。借助与浙江大学的 OpenKG 合作,推进 OneGraph 项目,我们致力于通过增强知识对齐能力,降低构建成本。同时,在垂直领域的探索中,例如医疗和法律术语的应用,我们优化了开放抽取的效率,显著提升了与领域知识的对齐准确性。我们的框架在通用数据集上较现有 SOTA 的 F1 提高了 10-20 个百分点,并在实际应用中,比如政务和医疗问答场景,取得了显著的精度提升,表明其在专业决策中的有效性。
5) KAG 模型:定义 LLMs 与 KGs 之间的协同任务
KAG 模型旨在降低大型语言模型(LLMs)与知识图谱(KGs)结合的成本,利用指令合成技术使较小模型在性能上接近更大模型。我们对 LLMs 和 KGs 的能力进行对齐,强调自然语言理解、推理和生成能力,确保从文本中提取结构化信息并提升知识融合效率。结构化、语义化的知识图谱和原始文档之间形成了良好的双向映射,从文本到图谱则是刻画文本内的关键信息和符号结构,从图谱到文本则是描述文本生成中所必须满足的知识和逻辑约束。
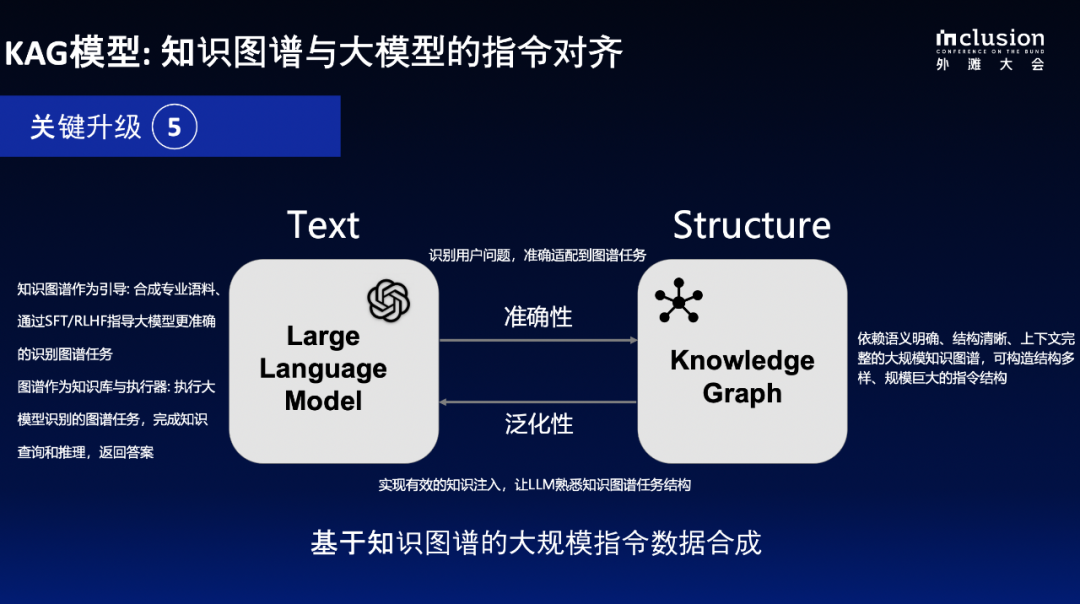
为构建知识图谱,我们注重知识点的文本可解释性,要求附带描述信息、关联原始文本段, 避免仅只有原始词条。知识图谱的结构化特性有助于生成高质量指令,通过逻辑拆解和语义关系合成提升大语言模型的自然语言理解和推理能力。此外,指令的合成和语义对齐使小参数量模型达到接近或超越更大参数模型的效果,同时大幅提升性能。实践中发现图谱指令合成微调后的小模型在概念补全、信息抽取等图谱专用任务上的准确率均高于更大参数模型。
3. KAG 在垂直领域的典型应用
今年以来,我们在业务应用中不断完善 KAG 框架。在支付宝 AI 生活管家 “支小宝” 的热点事件功能、政务民生场景,以及研报生成类任务,KAG 都能够生成逻辑上更为准确的内容。此外,支付宝今年在政务办事和医疗健康两个重要功能升级中也应用了知识图谱技术。例如,“去医院针灸能否报销?” 这一问题包含了特定条件,而带有条件的检索是传统搜索引擎或向量计算所不具备的功能。通过知识图谱的方式,我们可以更有效地找到相关知识并生成更加完备的回答。
近期,蚂蚁将发布 KAG 的整体技术报告。我们希望真正融合知识图谱的符号计算和向量检索的优势,因为它们在很多方面是互补的。同时,利用大型语言模型的理解和生成能力,构建一个知识增强的大语言模型生成系统。

在这个过程中,我们首先需要解决的是垂直领域应用的问题。系统既能进行复杂的符号决策,又能在复杂符号决策无法满足需求时,通过向量检索进行补充。在框架的后续版本中,我们将提供一些用户可调的参数。这意味着,如果用户对准确率有极高要求,可以减少基于信息检索生成的内容;如果对准确率有一定容忍度,则可以适当放宽标准。这为用户提供了一个可调节的垂直领域解决方案。因为并不是所有垂直领域应用场景都要求绝对的准确率,而是存在一定的容忍范围。因此,我们可以为用户提供更多的动态选择。
除了上述工作,为加速知识图谱与大语言模型的双向融通,蚂蚁集团也和浙江大学成立了知识图谱联合实验室。联合实验室已发布了大模型抽取框架 OneKE,下一步还将构建增强语言模型的 OneGraph。
后记:在 2024Inclusion・外滩大会 “超越平面思维,图计算让 AI 洞悉复杂世界” 见解论坛上,美国伊利诺伊大学芝加哥分校计算机科学与技术系特聘教授俞士纶、国际关联数据基准委员会(LDBC)副主席 Alastair Green、中国人寿财产保险有限公司人工智能开发团队负责人孔宇飞、蚂蚁数字科技 AI 技术负责人章鹏、蚂蚁集团图计算解决方案架构师崔安颀等嘉宾也带来了精彩分享,更多观点可点击阅读原文查看。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











