




当前,人工智能技术正以其独特的魅力和巨大的潜力引领着新一轮科技革命。AI大模型的爆发带动了GPU市场的繁荣,从云端到边缘AI应用也催生边缘AI服务器及AI加速处理器的巨大需求。
本文引用地址:
在边缘AI应用场景中,大数据与大模型的运算、推理依靠GPU的运行效能和带宽,AI的训练与微调依赖显存容量。为支撑70B、405B甚至大于1000B模型的训练与微调任务,现有市场方案依靠多显卡集群的方式拼凑显存与算力。现行的多显卡集群方式投入成本昂贵,且高性能GPU算力卡国内限购,成本高,后续维护进阶难,极大程度阻碍AI应用场景落地,导致无法充分赋能企业。
铨兴科技的AI超大模型全参微调、训推一体解决方案
深圳市铨兴科技有限公司作为半导体存储领域的解决方案供应商,凭借二十余年深厚的存储技术底蕴与不懈的创新追求,结合AI人工智能技术原理,把存储技术和算力在训练超大模型全参微调、训练推理方面有机结合,创新推出铨兴超大模型AI训推一体解决方案。
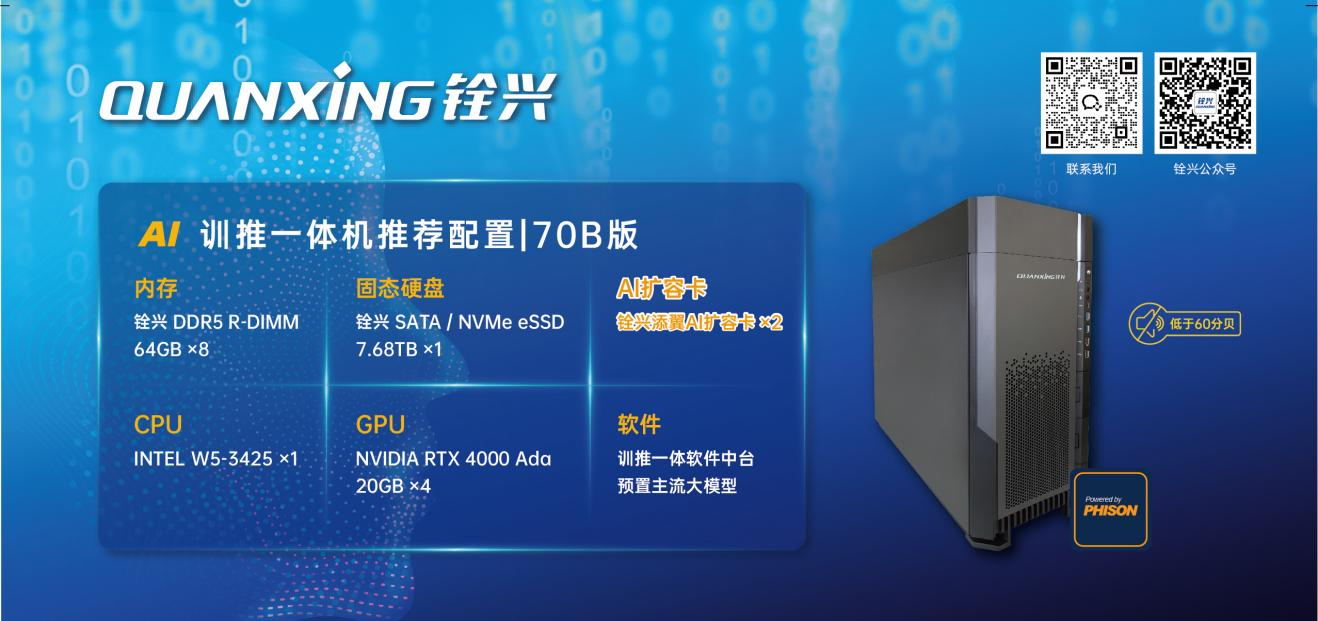
铨兴超大模型AI训推一体解决方案是由“铨兴添翼AI扩容卡、企业级固态硬盘、服务器内存”等核心组件的AI训推一体服务器解决方案,整体部署方案具备低成本、低功耗、安全等显著优势。

创新推出的添翼AI扩容卡,通过优化中间层驱动,打破显存墙,使得GPU可用显存空间直升20倍!
铨兴科技AI全参微调、训推一体解决方案解决什么问题
铨兴科技AI超大模型全参微调、训推一体解决方案,解决了高阶显卡购买难、硬件成本高、功耗大的痛点,解决了企业人工智能本地化部署最后一公里的难题,使本地端专属AI应用唾手可得,助力开启全民AI时代。
· 适配场景灵活多样
铨兴解决方案对Llama、Mistral、千问、智普等主流开源大模型实现了完美支持,可广泛应用于政府项目、数据中心、高校科研、企业专属服务等领域。
· 显著降低配置成本、能耗低
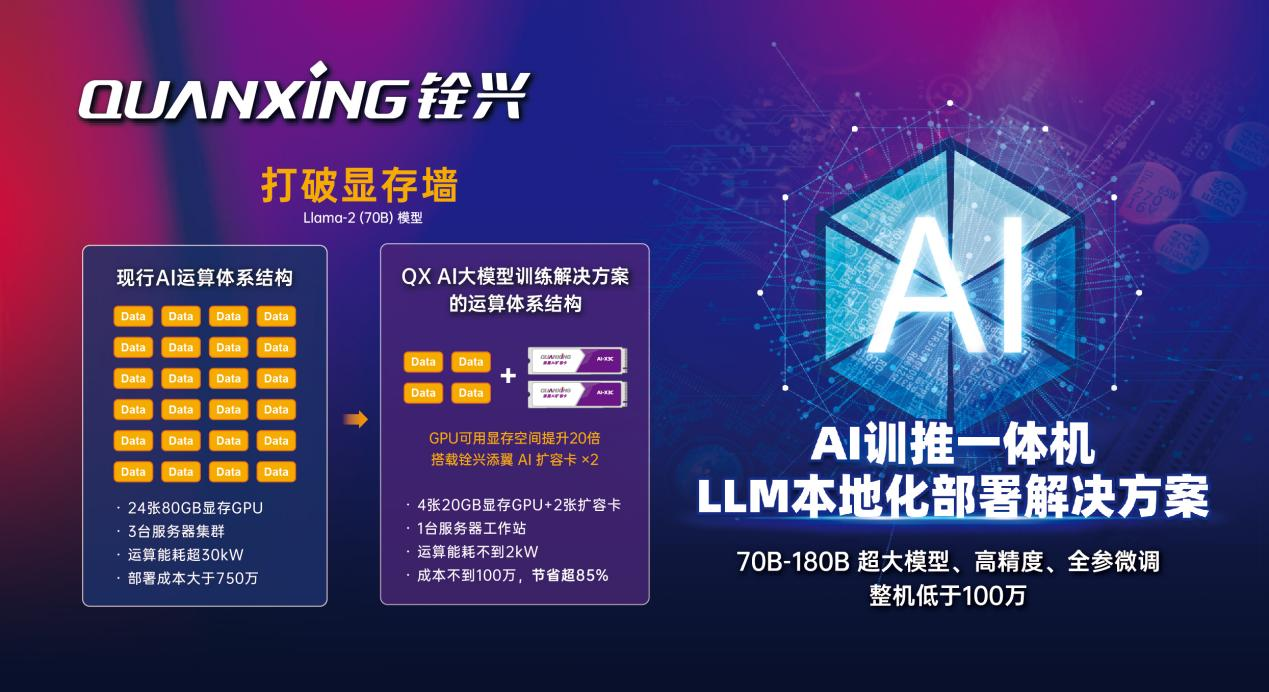
以实现Llama-3.1(70B)高算力的大模型训练为例,现行的市场方案所需GPU加速卡显存空间约1500GB,要配置二十四张80GB显存的GPU,使用叁台服务器集群,其运算能耗超30KW,存在显卡数量多、体积占地空间大、电力基础设施要求高、功耗大、整体部署成本超750万,价格昂贵等多样难题。
铨兴推出的运算体系机构配置两张铨兴添翼AI扩容卡,仅用四张不禁售的中阶显卡(20GB显存GPU),壹台服务器工作站即实现部署。铨兴AI大模型训推一体解决方案使用中阶显卡,解决高阶购买难的痛点,且显卡数量明显减少,噪声低于60dB,体积小巧灵活,整体部署价格低于100万,仅为传统方案价格的15%,功耗低至2kW,不到传统方案的10%,大大降低大模型训练的进入门槛成本,铨兴科技出色的技术实力和超前沿的存算解决方案,展现了人工智能产业算力和存力完美结合,给人工智能产业带来积极影响,推动铨民参与的AI低成本的时代的到来。
· 应用场景广泛
该方案适用70B-180B超大模型全参微调、训推一体,典型案例包括政府政务AI、科研AI、高校AI教学、法律AI、金融AI等多样B端客户专业服务等。
 目前已经与多家国产CPU、国产GPU、软件服务商、AI服务器整机厂商、厦门大学等高校以及政府部门建立了合作关系,共同推动AI
目前已经与多家国产CPU、国产GPU、软件服务商、AI服务器整机厂商、厦门大学等高校以及政府部门建立了合作关系,共同推动AI铨兴科技推动AI产业高质量
人工智能作为引领未来的战略性技术,已经成为发展新质生产力的主要阵地。铨兴科技精准解决中小企业AI人工智能落地部署的痛点,开发出前瞻性与实用性的半导体存储解决方案,为各行各业提供更加智能化、个性化、接地气的解决方案,驱动各企业的数字化与智能化,实现全域全时全场景应用持续深化,推动AI人工智能产业高质量加速发展!



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











