




过去半年,国内外视频生成模型迎来了新一轮技术大爆发,也都总能在第一时间烧遍社交网络。
但与语言生成模型的「掉队」有所不同,近期趋势却显示国内在视频生成模型这一领域的进步大为超越了国际水平。不少国外网友表示,「中国的可灵 AI 视频」在引爆互联网,而 OpenAI 的 Sora 却在沉睡。
今天,国内头部大模型厂商智谱 AI 也发布了旗下 AI 视频生成产品「清影」。

当然,国内外的 AI 视频模型有一个算一个,瑕疵都真不少,但比起「期货」Sora 来说,这些 AI 视频产品看得见也摸得着,顶多可能需要多尝试几次才能「抽」到保底的视频。
而这种探索本身就是技术进步的一部分。
正如 GPT-3 在诞生之初也曾遭受过质疑和批评,最终用时间证明了自己继往开来的价值,同理再给这些 AI 视频生成工具一些时间,从玩具变成工具也许就在朝夕之间。
清影 PC 端访问链接:
https://chatglm.cn/video?fr=opt_homepage_PC
清影移动端访问链接:
https://chatglm.cn/video?&fr=opt_888_qy3
半分钟生成 6s 视频,「智谱清影」正式发布
相较于今天发布的智谱清影,可能很多人更为了解智谱清言,但不看广告看疗效,不妨先来看看由「清影」一手打造的演示 demo。
在葱郁的森林里,树叶的缝隙中洒下一些阳光,产生丁达尔效应,光便有了形状。

当海啸如同发飙的怪兽咆哮而来,整个村子瞬间被海水吞噬,犹如末日电影里的经典桥段。

霓虹灯闪烁的城市夜景中,一只充满机械美感的小猴手持高科技工具,修理着同样闪烁、超未来的电子设备。

再换个画风,小猫张大嘴巴,人性化地露出困惑表情,脸上写满了问号。

没有宫斗戏码、没有尔虞我诈,甄嬛眉庄穿越时空的跨屏拥抱,只有真挚的姐妹情深。

另外,得益于智谱大模型团队自研高效打造的视频生成大模型 CogVideo,清影现已支持多种生成方式,包括文本生成视频、图片生成视频,甚至也可应用于广告制作、电影剪辑、短视频制作等领域。
清影具有强大的指令跟随能力,能够充分理解和执行用户给出的指令。
据介绍,智谱 AI 自研了一个端到端视频理解模型,用于为海量的视频数据生成详细的、贴合内容的描述,从而增强模型的文本理解和指令遵循能力,生成符合用户需求的视频。

在内容连贯性上,智谱 AI 自研高效三维变分自编码器结构(3D VAE),将原视频空间压缩至 2% 大小,配合 3D RoPE 位置编码模块,更有利于在时间维度上捕捉帧间关系,建立起视频中的长程依赖。
比如从土豆变成薯条一般需要几步?不需要「动火」,只需一句简单的提示词,土豆就变成了金黄诱人的薯条。官方表示,无论你的想法有多么天马行空,它都能一一地将其变成现实。

此外,参考了 Sora 算法设计的 CogVideoX 也是 DiT 架构,能将文本、时间、空间三个维度融合起来,通过技术优化后,CogVideoX 相比前代(CogVideo)推理速度提升了 6 倍。理论上,模型侧生成 6 秒视频仅需 30 秒时间。
作为对比,目前处在第一梯队的可灵 AI 生成单个 5s 的视频一般耗时 2 到 5 分钟。
在今天发布会现场,智谱 AI CEO 张鹏让清影生成一个猎豹在地上睡觉,身体在微微地起伏的视频,大约 30 秒时间大功告成,不过,让一朵静态的玫瑰「绽开」,则需要更多的时间。
此外,清影生成视频的清晰度可达 1440×960(3:2),帧率为 16fps。
清影还贴心地提供了配乐功能,生成视频可以添上音乐即可直接发布。
本以为宇航员弹吉他的静态图已经足够天马行空,而当它动起来,再配上悠然的旋律,仿佛航天员在太空中举办了一场演唱会。
与「期货」Sora 有所不同,「清影」不搞饥饿营销,一上线就全面开放,任何人都可以体验尝试,不用预约也不用排队,并且还将在后续版本中,陆续推出更高分辨率、更长时长的生成视频功能。
张鹏也在智谱 Open Day 上表示,「所有用户,都能通过清影(Ying)体验 AI 文生视频、图生视频能力。」
现在,清影处于首发测试期间,所有用户都可以免费使用。若追求更流畅的体验,花上 5 块钱就能解锁一天(24 小时)的高速通道权益,要是愿意付费 199 元,就能解锁一年的付费高速通道权益。
另外,清影(Ying)API 也同步上线大模型开放平台 bigmodel.cn,企业和开发者通过调用 API 的方式,体验和使用文生视频以及图生视频的模型能力。
上手门槛低但还要「抽卡」,小白再也不用担心写不好指令了
APPSO 也第一时间体验了清影,在测试了一些场景后,我们也总结出关于使用清影的一些心得:
- 视频生成像「炼丹」,输出不稳,建议多试几次
- 效果上限得看提示词,提示词结构要尽可能清晰
- 镜头画面效果最好的是近景,其它景别不太稳定
- 实体类型实现排序:动物> 植物> 物品> 建筑> 人物
不懂艺术的科学家不是好科学家,爱因斯坦弹起吉他来如鱼得水,摇头晃脑自带节奏,不像是演的。

大熊猫弹起吉他也是有模有样,多才多艺。

平时不苟言笑的唐僧跟你挥手打招呼,随着节奏摇摆起来。

当然,以上还算是一些效果比较好的视频,在视频生成的过程中,我们也积攒了不少废片。
比如说,让躺在床上的皇上用右手吃个鸡腿,结果凭空多出了一只手,视频最后一秒,我感觉皇上快要露出他的女性妆发了。

又或者张国荣看向我的那一刻,心中的哥哥已经变成了「那个男的」。

在复杂场景中,人物动作过渡不自然、无法准确模拟复杂场景的物理特性、生成内容的准确性不足等等,这些缺点并非是清影的「专利」,而是视频生成模型目前的局限。
在实际应用中,尽管用户能通过优化提示词来提升视频质量,但「翻车」也是常有的事,好在质量尚可的提示词能够在很大程度上保证了视频生成模型的下限。
为了照顾部分小白玩家,我们也特地准备了一些提示词的小诀窍:
- 简单公式:[摄像机移动]+[建立场景]+[更多细节]
- 复杂公式:[镜头语言] + [光影] + [主体 (主体描述)] + [主体运动] +[场景 (场景描述)] +[情绪/氛围]
摄影机平移(镜头移动),一个小男孩坐在公园的长椅上(主体描述),手里拿着一杯热气腾腾的咖啡(主体动作)。他穿着一件蓝色的衬衫,看起来很愉快(主体细节描述),背景是绿树成荫的公园,阳光透过树叶洒在男孩身上(所处环境描述)。
如果你还是没有头绪,那么我推荐你使用智谱清言提供的帮写视频提示词的智能体,哪怕是输入生活中常见的普通场景,都能获得三个优质提示词。
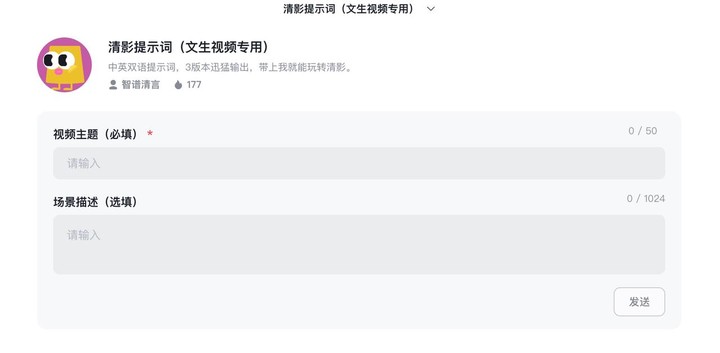
比如,随手的一句「柯基在沙滩上晒太阳」,然后就能得到如下自然风光摄影风格中英文提示词,并且还有水彩画风格、3D 动画风格等多种风格提示词供你挑选:
中文:在阳光明媚的沙滩上,一只柯基犬懒洋洋地躺在沙滩巾上,享受着温暖的阳光。镜头从低角度拍摄,背景是广阔的蓝色海洋和洁白的沙滩,海浪轻轻拍打着岸边,气氛宁静,画质 4K 超清。
英文:On a sunny beach, a Corgi lies lazily on a beach towel, basking in the warm sunlight. The camera captures the scene from a low angle, showcasing the vast blue ocean and pristine white sand in the background, with gentle waves lapping at the shore. The atmosphere is tranquil, captured in 4K ultra-high definition.
看到如此令人满意的提示词,不错,我当时也确实是想这么写的。
附上清影提示词智能体地址(文生视频):https://chatglm.cn/main/gdetail/669911fe0bef38883947d3c6
图片生成视频同理,输入图像主体,选择图像风格,就能让智谱清言帮你写出对应的提示词。从无提示词、到「戴眼镜」,再到「唐僧伸出手,戴上眼镜」的进化,效果嘛,也是天壤之别。

附上清影提示词智能体地址(图生视频):https://chatglm.cn/main/gdetail/669fb16ffdf0683c86f7d903
工欲善其事,必先利其器,把格局再打开一点,你还可以在智谱清言里体验更多的内容创作工具。
从最初的选题材料收集阶段,到脚本撰写环节,图片与视频创作过程,再到推广文案,几乎能打通视频生成创意的全链条,就差没明说,你只顾想创意,剩下的交给它。
我们发现,包括可灵在内最近发布的 AI 视频产品,都在通过首尾帧控制等方式提升可控性。

AI 创作者陈坤曾告诉 APPSO,现在可用于商业化交付的 AI 视频,几乎全都是图生视频,因为文生视频还做不到,其实就是可控性的问题。
今天智谱 AI 发布的清影则进一步提升了文字生成视频的可控性,智谱 AI 接受 APPSO 采访时表示,文字生成视频体现了更通用的可控性。
AI 生成的视频大部分还是由人用语言的方式去控制的。所以如何让文字或者简单的语言指令的识别,是更高层面的控制性。
AI 视频,正在从玩具到创作者工具
如果去年是大模型爆发的元年,今年可是说 AI 视频走向应用的重要节点。
虽然引爆这一切的 Sora 至今仍未上线,但它给 AI 视频带来了一些启发。
Sora 通过合理的细节设计解决了帧间细节跳变的问题。同时直接生成了高分辨率(1080p)的视频图像,可以生成语义丰富的长达 60 秒的视频,说明背后训练的序列也比较长。

仅在这两个月,就有不下 10 家公司推出 AI 视频新产品或大更新。

就在智谱清影发布前几天,快手的可灵 AI 在全球开放内测, 而另外一个被认为 Sora 的 PixVerse 发布了 V2 版本,支持一键生成 1-5 段连续的视频内容。
不久前,Runway Gen 3 Alpha 也开启付费用户公测,细节的精致度和丝滑程度上有不错的提升。上个月刚刚发布的 电影级视频生成模型 Dream Machine,也在最近更新了首尾帧功能。
短短几个月内,AI 视频生成在物理模拟、运动流畅度、对提示词理解方面都有大幅的提升。 AI 玄幻剧导演陈坤对此的感受更为敏感,他认为 AI 视频生成技术的进步或许比想象得更快。
2023 年的 AI 视频,更像动态 PPT,人物在表演慢动作,靠蒙太奇剪辑拉分。但现在,AI 视频的「PPT 味」已经淡了不少。
陈坤导演的国内首部 AIGC 奇观剧《山海奇镜之劈波斩浪》最近刚刚上线,他用 AI 取代不少传统影视实拍的环节,他告诉 APPSO 以前要做类似的玄幻题材,至少需要 100 个人,而他的团队只有 10 多个人,大大缩短制作周期和成本。
这半年,可以看到更多专业的影视创作者开始尝试 AI 视频。国内快手抖音都上线 AI 短剧,50 位 AIGC 创作者合作完成的首部 AI 长篇电影《Our T2 Remake》在洛杉矶举行首映。

虽然 AI 视频生成在在人物和场景一致性、人物表演、动作交互等方面还有局限,但不否认 AI 视频正在从去年尝鲜的玩具,慢慢转变成创作者的工具。
这或许也是包括智谱清影、快手可灵、 Luma Dream Machine 等产品都开始推出会员体系的重要原因,要知道国内大模型面向 C 端的产品大都以免费为主,这和国内订阅付费习惯和优先追求用户增长策略有关,AI 视频的付费除了好奇的用户,必须有更多内容创作者支持才能持续。
当然,AI 视频生成还处于比较早期的阶段,所谓「一句话生成电影」只是标题党式的误导,视频模型需要具有更好的指令遵循能力和可控性,才能更好地理解物理世界。
智谱在今天的发布会也提到,多模态模型的探索还处于非常初级的阶段。
从生成视频的效果看,对物理世界规律的理解、高分辨率、镜头动作连贯性以及时长等,都有非常大的提升空间。
从模型本身角度看,需要更具突破式创新的新模型架构,它应该更高效压缩视频信息,更充分融合文本和视频内容,贴合用户指令的同时,让生成内容真实感更高。
「我们积极在模型层面探索更高效的 scaling 方式。」但张鹏也对多模态模型的发展充满信心,「随着算法、数据不断迭代,相信 Scaling Law 将继续发挥强大威力。」
AI 创作者陈坤认为,AI 生成的镜头要 100% 扛得住大银幕,只是时间问题。这个时间是多久并不是最值得关心的,参与这个过程反而更加重要,就像智谱 AI CEO 张鹏此前接受 APPSO 采访提到的:
很多事情要前赴后继地去探索,这个过程就很重要,不要只看到最终的结果,更重要的是我们采取行动,我觉得这才是目前大家更应该关注的事情。
作者:李超凡、莫崇宇



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











