




本文作者来自浙江大学、上海人工智能实验室、香港中文大学、悉尼大学和牛津大学。作者列表:吴逸璇,王逸舟,唐诗翔,吴文灏,贺通,Wanli Ouyang,Philip Torr,Jian Wu。其中,共同第一作者吴逸璇是浙江大学博士生,王逸舟是上海人工智能实验室科研助理。通讯作者唐诗翔是香港中文大学博士后研究员。
多模态大模型(Multimodal Large Language Models,MLLMs)在不同的任务中表现出了令人印象深刻的能力,尽管如此,这些模型在检测任务中的潜力仍被低估。在复杂的目标检测任务中需要精确坐标时,MLLMs 带有的幻觉又让它常常错过目标物体或给出不准确的边界框。为了让 MLLMs 赋能检测,现有的工作不仅需要收集大量高质量的指令数据集,还需要对开源模型进行微调。费时费力的同时,也无法利用闭源模型更强大的视觉理解能力。为此,浙江大学联合上海人工智能实验室和牛津大学提出了 DetToolChain,一种释放多模态大语言模型检测能力的新提示范式。不需要训练就能让多模态大模型学会精确检测。相关研究已经被 ECCV 2024 收录。
为了解决 MLLM 在检测任务上的问题,DetToolChain 从三个点出发:(1)针对检测设计视觉提示(visual prompts),比传统的文字提示(textual prompts)更直接有效的让 MLLM 理解位置信息,(2)把精细的检测任务拆解成小而简单的任务,(3)利用 chain-of-thought 逐步优化检测结果,也尽可能的避免多模态大模型的幻觉。
与上述的 insights 对应,DetToolChain 包含两个关键设计:(1)一套全面的视觉处理提示(visual processing prompts),直接在图像中绘制,可以显著缩小视觉信息和文本信息之间的差距。(2)一套全面的检测推理提示 (detection reasoning prompts),增强对检测目标的空间理解,并通过样本自适应的检测工具链逐步确定最终的目标精确位置。
通过将 DetToolChain 与 MLLM 结合,如 GPT-4V 和 Gemini,可以在无需指令调优的情况下支持各种检测任务,包括开放词汇检测、描述目标检测、指称表达理解和定向目标检测。

论文标题:DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
论文链接:https://arxiv.org/abs/2403.12488
什么是 DetToolChain?
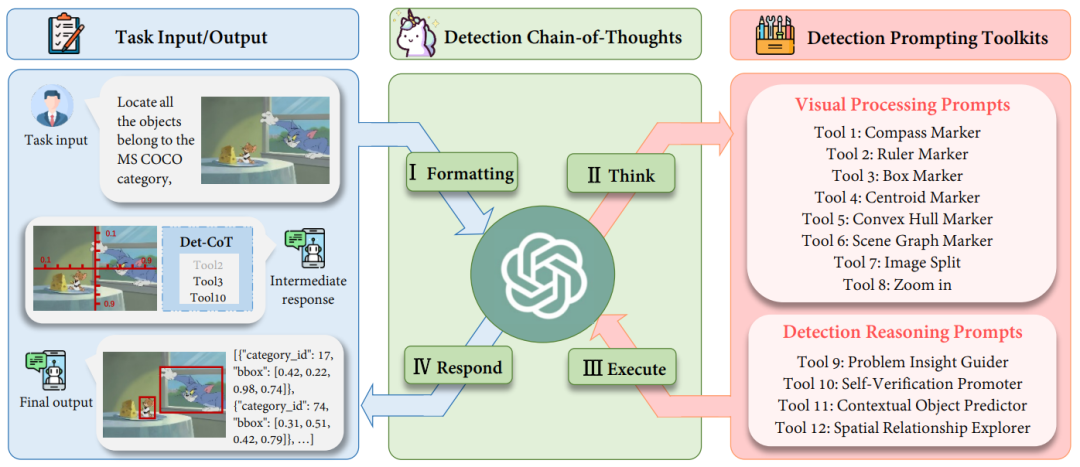
如图 1 所示,对于给定的查询图像,MLLM 被指示进行以下步骤:
I. Formatting:将任务的原始输入格式转化为适当的指令模板,作为 MLLM 的输入;
II. Think:将特定的复杂检测任务分解为更简单的子任务,并从检测提示工具包中选择有效的提示(prompts);
III. Execute:按顺序迭代执行特定的提示(prompts);
IV. Respond:运用 MLLM 其自身的推理能力来监督整个检测过程并返回最终响应(final answer)。
检测提示工具包:Visual Processing Prompts
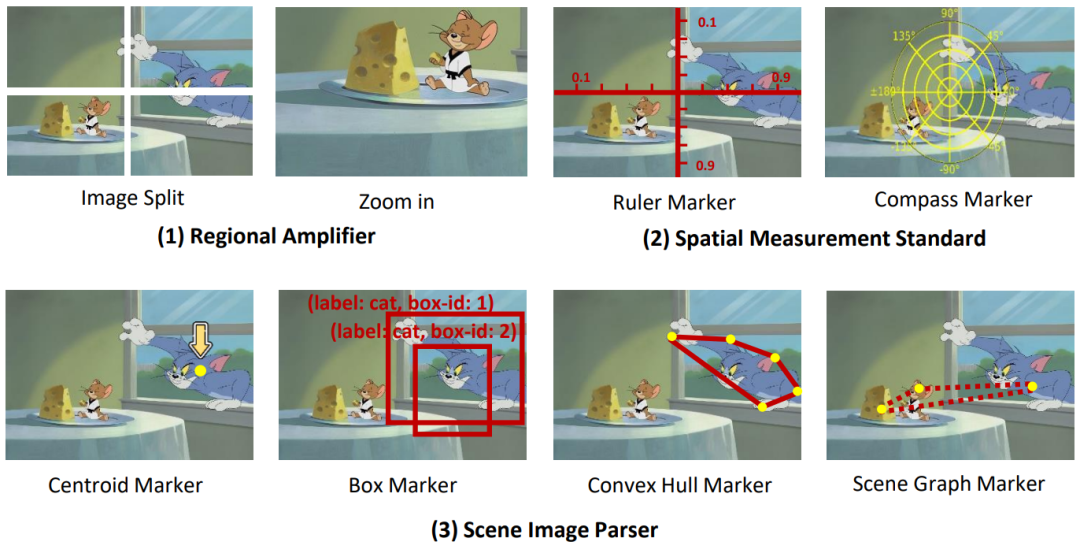
图 2:visual processing prompts 的示意图。我们设计了 (1) Regional Amplifier, (2) Spatial Measurement Standard, (3) Scene Image Parser,从不同的角度来提升 MLLMs 的检测能力。
如图 2 所示,(1) Regional Amplifier 旨在增强 MLLMs 对感兴趣区域(ROI)的可见性,包括将原始图像裁剪成不同部分子区域,重点关注目标物体所在子区域;此外,放大功能则使得可以对图像中特定子区域进行细粒度观察。
(2) Spatial Measurement Standard 通过在原始图像上叠加带有线性刻度的尺子和指南针,为目标检测提供更明确的参考,如图 2 (2) 所示。辅助尺子和指南针使 MLLMs 能够利用叠加在图像上的平移和旋转参考输出准确的坐标和角度。本质上,这一辅助线简化了检测任务,使 MLLMs 能够读取物体的坐标,而不是直接预测它们。
(3) Scene Image Parser 标记预测的物体位置或关系,利用空间和上下文信息实现对图像的空间关系理解。Scene Image Parser 可以分为两类:首先,针对单个目标物体,我们用质心、凸包和带标签名称及框索引的边界框标记预测的物体。这些标记以不同格式表示物体位置信息,使 MLLM 能够检测不同形状和背景的多样物体,特别是形状不规则或被大量遮挡的物体。例如,凸包标记器标记物体的边界点并将其连接为凸包,以增强对形状非常不规则的物体的检测性能。其次,针对多目标,我们通过场景图标记器(scene graph marker)连接不同物体的中心,以突出图像中物体之间的关系。基于场景图,MLLM 可以利用其上下文推理能力来优化预测的边界框并避免幻觉。例如,如图 2 (3) 所示,Jerry 要吃奶酪,因此它们的 bounding box 应该非常接近。
检测提示工具包:Detection Reasoning Prompts

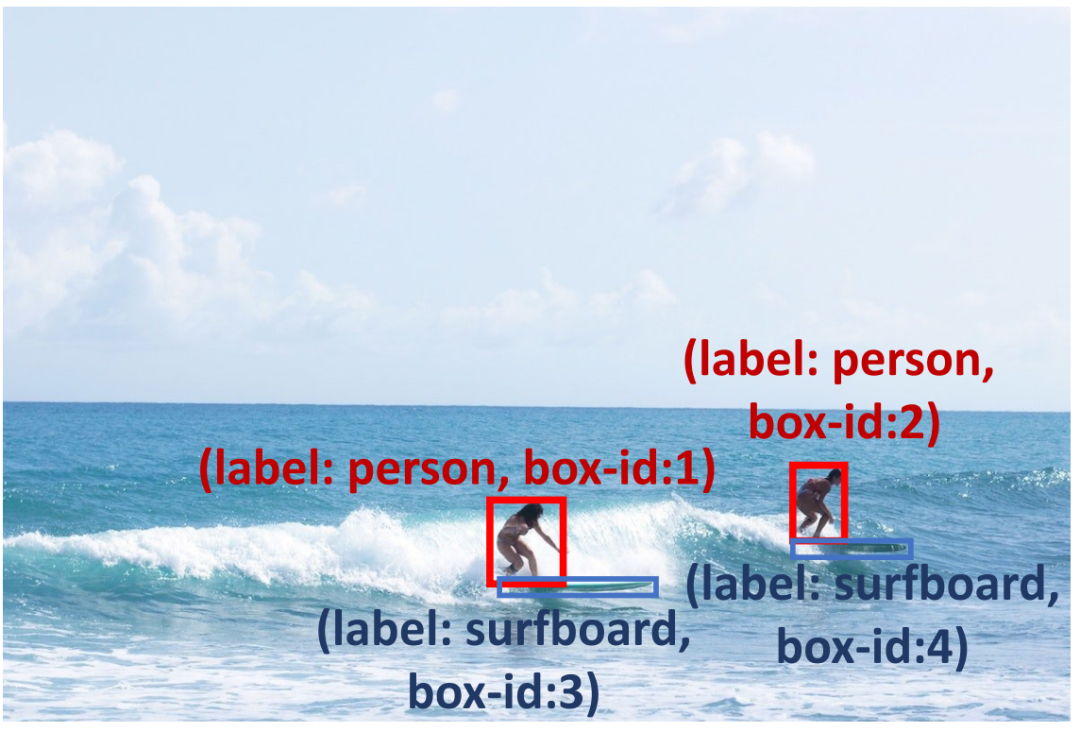
为了提高预测框的可靠性,我们进行了检测推理提示(如表 1 所示),以检查预测结果并诊断可能存在的潜在问题。首先,我们提出了 Problem Insight Guider,突出困难问题并为查询图像提供有效的检测建议和相似例子。例如,针对图 3,Problem Insight Guider 将该查询定义为小物体检测的问题,并建议通过放大冲浪板区域来解决它。其次,为了利用 MLLMs 固有的空间和上下文能力,我们设计了 Spatial Relationship Explorer 和 Contextual Object Predictor,以确保检测结果符合常识。如图 3 所示,冲浪板可能与海洋共现(上下文知识),而冲浪者的脚附近应该有一个冲浪板(空间知识)。此外,我们应用 Self-Verification Promoter 来增强多轮响应的一致性。为了进一步提升 MLLMs 的推理能力,我们采用了广泛应用的 prompting 方法,例如 debating 和 self-debugging 等。详细描述请见原文。

实验:免训练也能超越微调方法

如表 2 所示,我们在 open vocabulary detection(OVD)上评估了我们的方法,测试了在 COCO OVD benchmark 中 17 个新类、48 个基础类和所有类的 AP50 结果。结果显示,使用我们的 DetToolChain,GPT-4V 和 Gemini 的性能均显著提升。

为了展示我们的方法在指称表达理解上的有效性,我们将我们的方法与其他零样本方法在 RefCOCO、RefCOCO + 和 RefCOCOg 数据集上进行了比较(表 5)。在 RefCOCO 上,DetToolChain 使得 GPT-4V 基线在 val、test-A 和 test-B 上的性能分别提升了 44.53%、46.11% 和 24.85%,展示了 DetToolChain 在 zero-shot 条件下优越的指称表达理解和定位性能。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











