




IT之家 3 月 16 日消息,今日,阿里通义实验室宣布发布并开源首个支持影视级多场景配音的多模态大模型 Fun-CineForge。此外,还配套开放了高质量数据集的构建方法。官方称,通过“数据 + 模型”的一体化设计,Fun-CineForge 正尝试解决影视级 AI 配音长期面临的关键问题。
IT之家附官方介绍如下:

在真实影视制作场景中,一段高质量的配音,需要同时通过四大严苛考验:
然而,现有 AI 配音方法普遍面临两大瓶颈:
01、高质量多模态数据集稀缺。
高质量的配音数据集依赖多种模态的信息,现有的配音数据集数据量过小、标注类型有限,难以满足大模型的有效训练;高度依赖人工标注成本较高,难以大规模生产;缺乏对话和多人场景的长视频数据使大模型难以应对复杂配音场景。
02、模型能力不足。
传统配音模型在方法上,仅依赖视频画面中清晰可见的唇部区域来学习音画同步。但真实影视配音制作中,存在大量复杂场景,如多人对话、频繁镜头切换、人脸遮挡、面部模糊,现有技术难以在说话人面部缺失的场景实现音画同步。

为了解决上述问题,通义实验室提出了 Fun-CineForge 。本次开源内容核心包含两部分,旨在打通影视配音的“数据 - 模型”闭环:
1️⃣ 模型侧:面向复杂影视场景的多模态配音大模型
2️⃣ 数据侧:大规模多模态配音数据集构建流程(CineDub)

在数据基础之上,Fun-CineForge 基于 CosyVoice3 强大的语音合成底层能力,构建了一个面向复杂影视场景的配音大模型,完成视频 + 文本 → 语音的任务。
输入包括:
模型即可以参考语音的音色来合成与时间和视频信息高度对齐的语音。

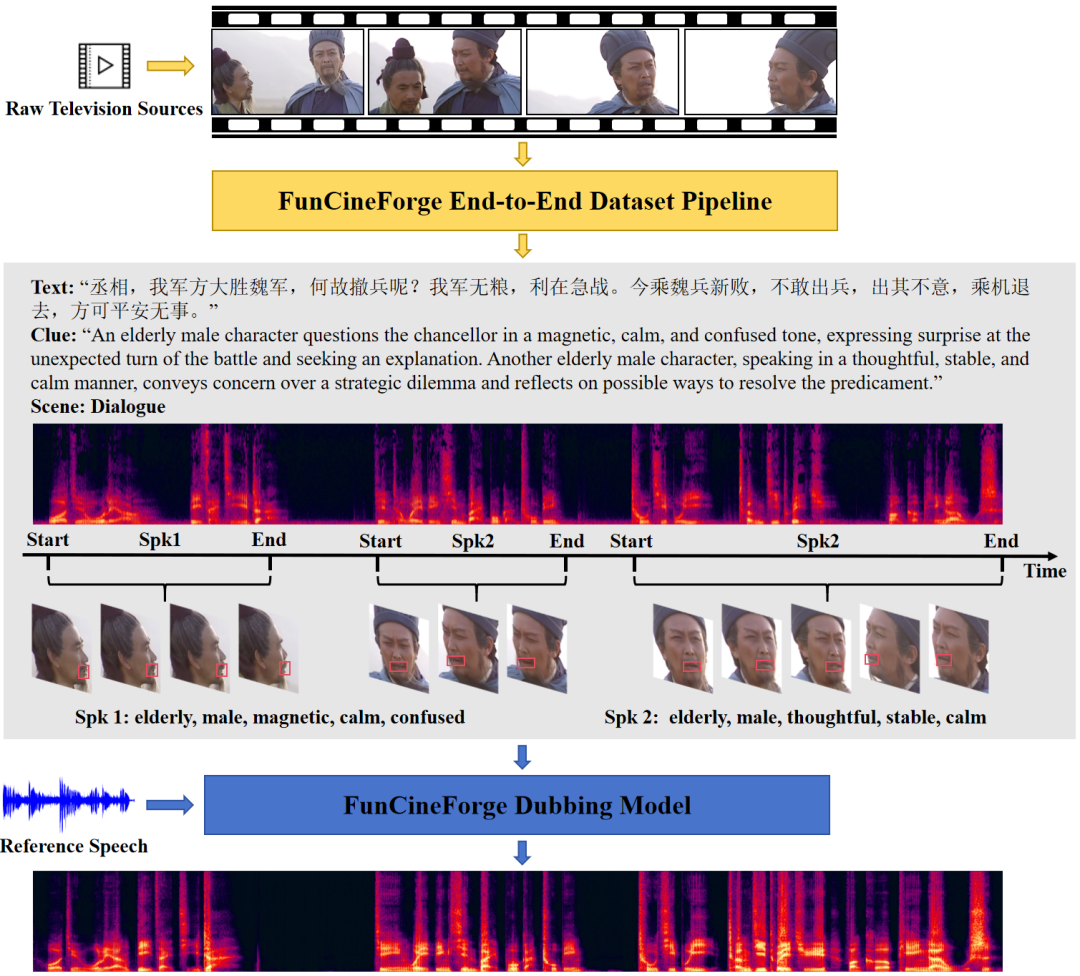
Fun-CineForge 首先构建了一套自动化的数据集生产流程,可以将原始影视素材转化为结构化多模态数据。
该流程包括人声分离、文本转录、长视频分段、音视频联合说话人分离等,其中,基于通用大模型思维链的双向矫正机制,大幅降低了转录文本和说话人分离结果的错误率。
数据覆盖独白、旁白、对话、多说话人等多种典型场景。每条数据都包含转录台词、帧级人脸唇部数据、角色属性情感线索、毫秒级时间戳及干净人声轨道。
这些相互补充、相辅相成的多模态信息为训练大模型的专业配音能力提供了坚实基础。
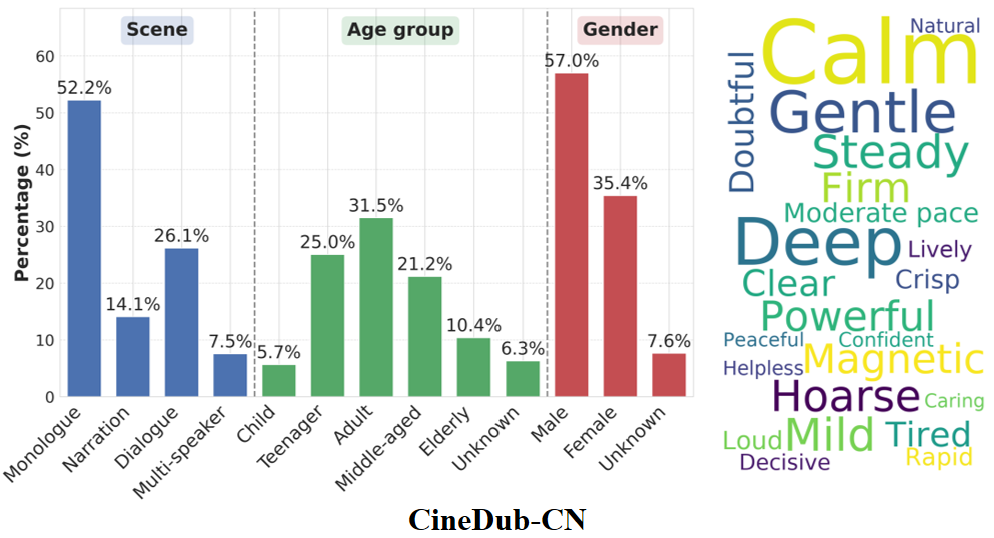
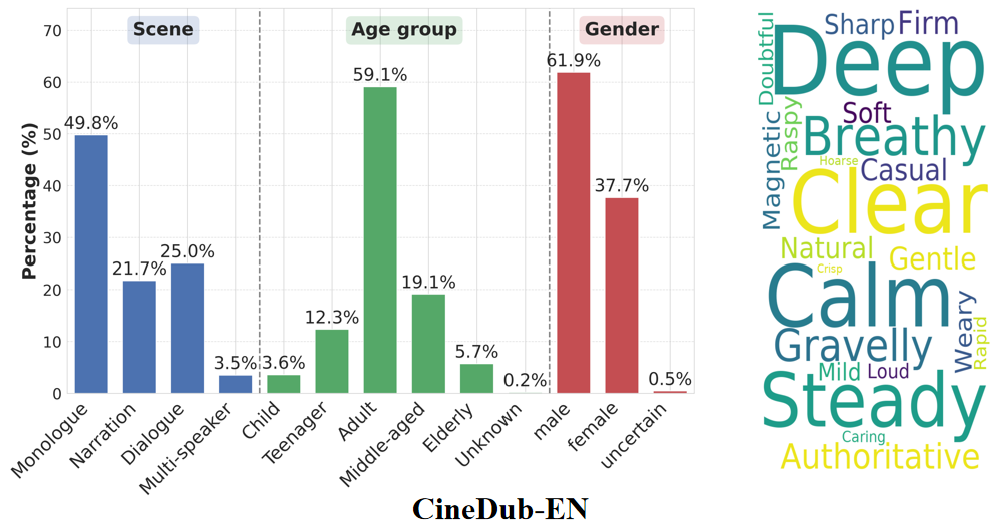
注释:从 350 多部的中英文影视剧中生产的 CineDub 数据集在场景类别,年龄分布,性格分布,音色热词的统计情况。

Fun-CineForge 最重要的技术创新,是在配音模型中首次引入“时间模态”。传统 TTS 模型通常只关注文本内容、声音特征或视觉信息,但影视配音中还有一个关键维度:时间。
例如:
这些信息能够直接帮助模型深入理解“在什么时间段内,哪个角色在说什么。”,在视觉模态“看不到”说话人的时候,时间模态作为一种强监督目标,使语音出现在该出现的时间区域内。
这一点使模型具备了在复杂场景下的配音能力。

为了实现上述能力,Fun-CineForge 模型同时利用四类信息,它们相互补充、相辅相成。

实验结果显示,在多个关键指标上,Fun-CineForge 配音模型都优于现有开源配音模型,包括:
其中,Fun-CineForge 配音模型以独白和旁白两种单人配音场景效果最佳,首次支持双人对话与多人对话的场景,并能够实现准确的时间对齐、音画同步与音色一致。
我们在自建的 CineDub 数据集上对 Fun-CineForge 进行了全面评估,覆盖独白、旁白、对话、多人场景等多种典型影视配音场景。结果显示,单人场景效果最优,独白和旁白的中文字错率仅 1.49% 和 1.90%,音画同步精准。
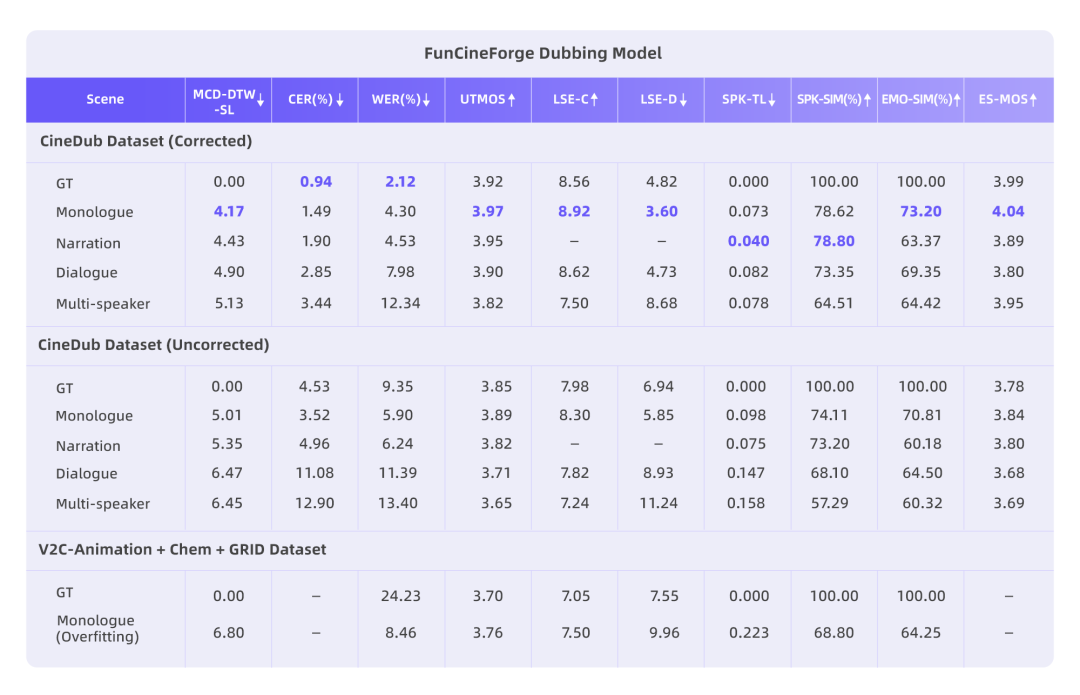
在独白场景下,我们将 Fun-CineForge 与 DeepDubber-V1 和 InstructDubber 进行了对比。结果显示,Fun-CineForge 在词错率、唇部同步、时间对齐、音色相似度等各项指标上均明显优于基线模型。
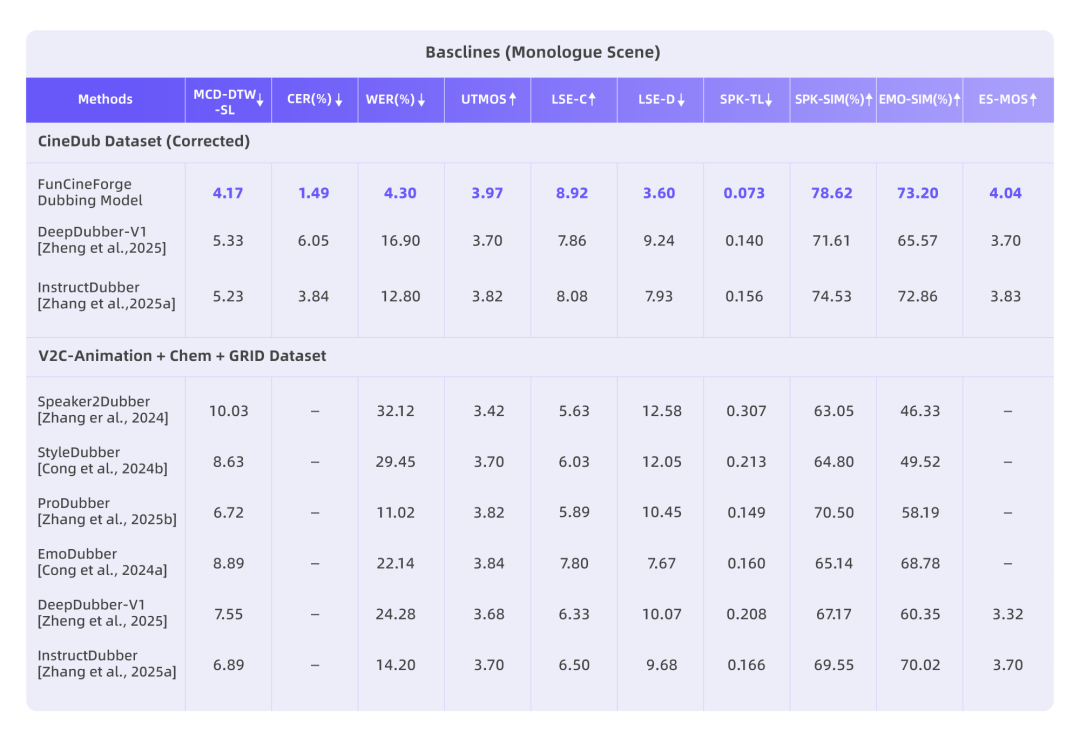
注:CER / WER 为中文字 / 英文词错率(↓ 越低越准);SPK-SIM 为音色相似度(↑ 越高越像);SPK-TL 为时间对齐误差(↓ 越低越精准);LSE-C/D 为唇部同步度(C ↑ 越高 / D ↓ 越低越好)。

目前,Fun-CineForge 已经开源,开发者可立即体验各种复杂场景下的中英文影视配音能力(包括情绪化表达、镜头切换、面部遮挡等情景)。
Fun-CineForge 项目主页:https://funcineforge.github.io/
(网站提供独白、旁白、对话、多说话人、音色克隆、指令控制等丰富示例,还能体验音色克隆和指令控制等进阶功能。样例涵盖了在实际影视场景中存在的,情绪化表达、镜头频繁切换、说话人频繁切换、说话人面部遮挡或镜头对准其他角色、画面阴暗、画面多人共存等各种复杂情景。)
技术论文 Fun-CineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
数据集样例:网站开源了剔除原视频的 CineDub 数据集样例,包括 CineDub-CN 和 CineDub-EN 中英文双语种,以供参考。
代码与模型:三个平台同步开源,欢迎体验~
现阶段 AI 语音技术已经在客服、助手等场景广泛应用,但在专业的动漫或影视内容制作和后期加工中,仍然存在更高要求。对于越长的视频,需要给定的时间戳区间和参考角色音频越多,音画同步性能和音色克隆准确性会下降,多人对话场景鲁棒性降低。
Fun-CineForge 为音频大模型技术在专业配音制作领域提供了新的技术方案,当前支持 30 秒以内的视频片段推理。
未来,随着多模态大模型能力不断提升,我们也希望 AI 能在影视、动画、游戏等内容生产领域发挥更大的作用。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











