




IT之家 12 月 23 日消息,科技博主 Jeff Geerling 于 12 月 18 日发布评测视频,利用苹果提供的四台 Mac Studio(搭载 M3 Ultra 芯片)搭建计算集群,实测了 macOS Tahoe 26.2 中 Thunderbolt 5 与 RDMA 技术对 AI 性能的提升。
这套“豪华”集群由四台搭载 M3 Ultra 芯片的 Mac Studio 组成(两台配备 512GB 内存,两台配备 256GB 内存),通过 Thunderbolt 5 连接,构建了总容量达 1.5TB 的统一内存池,硬件总价值近 4 万美元(现汇率约合 28.2 万元人民币)。

在多机集群中,节点间的通信速度往往决定了整体性能。传统的以太网连接通常受限于 10Gb/s 的带宽,而此次测试启用的 Thunderbolt 5 支持将带宽上限提升至 80Gb/s。

更为关键的是,苹果在新系统中引入了 RDMA 技术。该技术无需经过对方 CPU 的繁琐处理,允许集群中的某个 CPU 节点直接读取其他节点的内存数据。
这意味着四台 Mac 的内存资源被整合成一个巨大的共享池,极大地降低了延迟,为运行单个设备无法承载的超大语言模型(LLM)提供了硬件基础。
Geerling 使用支持 RDMA 的开源工具 Exo 与不支持该技术的 Llama.cpp,对比测试大模型推理速度。在运行 Qwen3 235B 模型时,单节点下 Llama.cpp 略占优势;但扩展至四节点后,Llama.cpp 性能跌至 15.2 tokens/s,而开启 RDMA 的 Exo 则升至 31.9 tokens/s,性能实现翻倍。
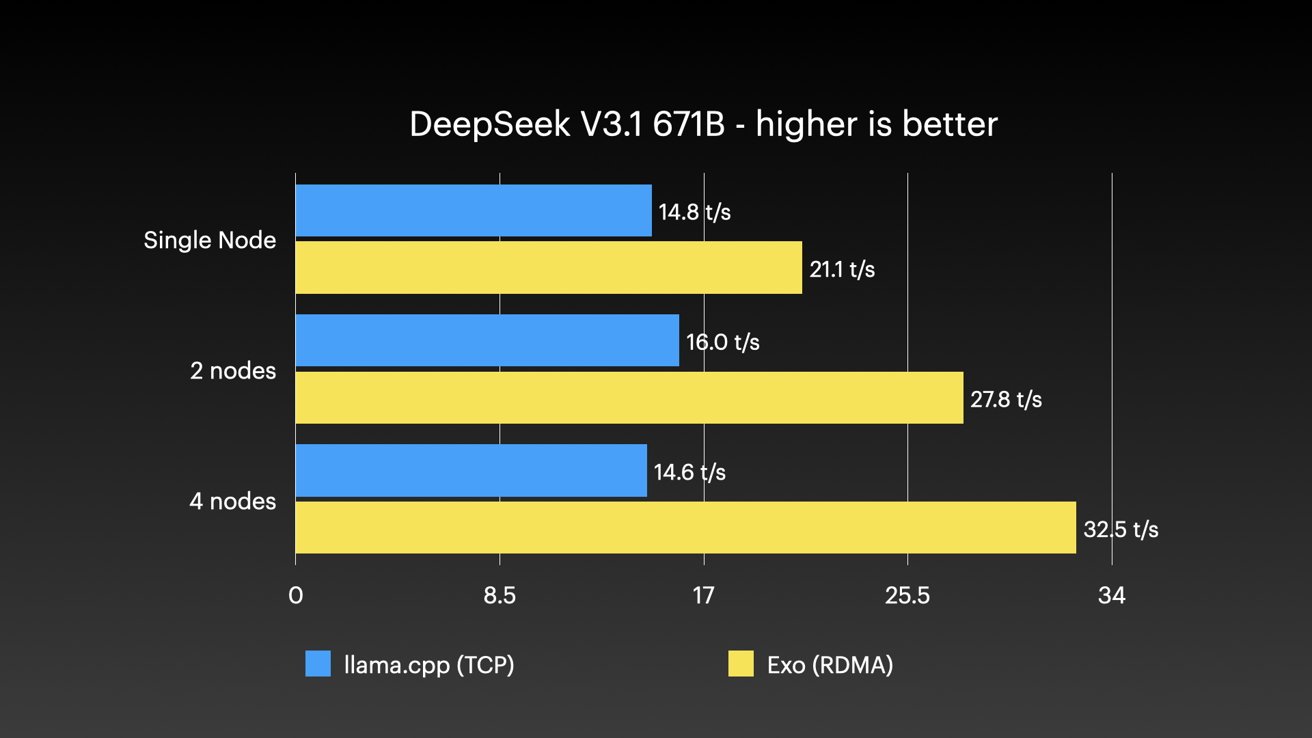
在测试 DeepSeek V3.1(671B 参数)时,Exo 的推理速度从单节点的 21.1 tokens/s 稳步提升至四节点的 32.5 tokens/s,增幅 54.03%。在相同四节点情况下,Llama.cpp 的推理速度为 14.6 tokens/s,开启 RDMA 后提升 122.6%。
测试还成功运行了万亿参数级别的 Kimi K2 Thinking 模型,四节点速度达到 28.3 tokens/s,验证了该方案在处理超大规模模型时的可用性。
尽管测试结果令人振奋,但该方案仍存在一定门槛。首先是约 4 万美元的高昂成本,虽相比企业级 H100 集群具有价格优势,但对个人用户依然遥不可及。
其次是 Thunderbolt 5 目前仅支持菊花链连接,缺乏专用交换机,限制了集群的无限扩展;此外,测试过程中也出现了基准测试报错等软件稳定性问题。
不过,随着未来 M5 Ultra 芯片及 GPU 神经加速器的引入,结合 SMB Direct 等潜在功能的开放,Mac 集群有望成为 AI 研究机构和高带宽需求团队的高效解决方案。
IT之家注:RDMA 全称为 Remote Direct Memory Access,直译为远程直接内存访问,是一种允许一台计算机直接读取或写入另一台计算机内存的技术。
就像你不用打电话让同事发文件,而是直接把手伸进他的抽屉拿文件一样,过程中不需要对方的大脑(CPU)参与,因此速度极快、延迟极低,常用于高性能计算集群。
Thunderbolt 5(雷雳 5)是英特尔发布的新一代连接标准,传输速度翻倍达到了 80Gb/s(特定模式下可达 120Gb/s),能像高速公路一样快速传输海量数据。
雷雳 5 集群是指 macOS 现已支持多台电脑通过雷雳 5 端口互联,可将参数庞大的 AI 大语言模型分布运行在多台电脑上,不仅能够分担运算负载,还能够共享内存等硬件资源,同时系统还提升了 AI 运算的整体性能。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











