




IT之家 11 月 13 日消息,摩尔线程提出的新一代大语言模型对齐框架 —— URPO 统一奖励与策略优化,相关研究论文近日被人工智能领域的国际顶级学术会议 AAAI 2026 收录,为简化大模型训练流程、突破模型性能上限提供了全新的技术路径。
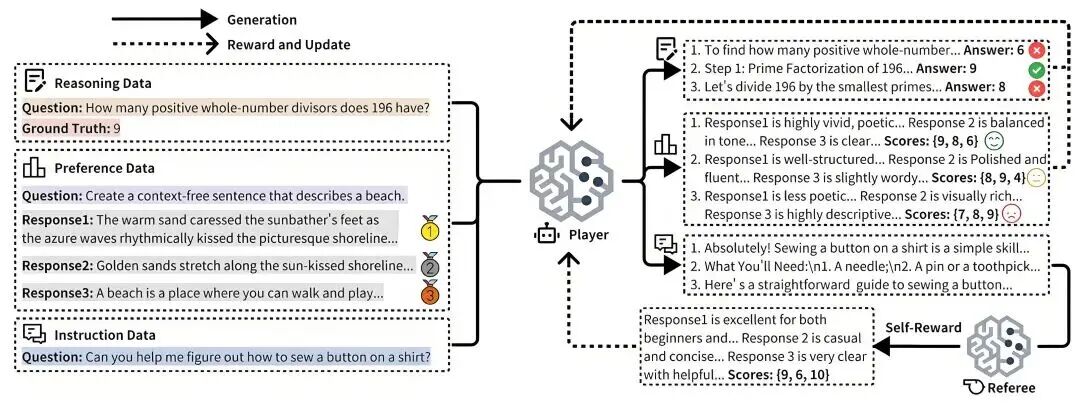 ▲ 图源:摩尔线程官方公众号 | URPO 统一奖励与策略优化框架
▲ 图源:摩尔线程官方公众号 | URPO 统一奖励与策略优化框架据介绍,在题为《URPO:A Unified Reward & Policy Optimization Framework for Large Language Models》的论文中,摩尔线程 AI 研究团队提出了 URPO 统一奖励与策略优化框架,将“指令遵循”(选手)和“奖励评判”(裁判)两大角色融合于单一模型中,并在统一训练阶段实现同步优化。URPO 从以下三方面攻克技术挑战:
数据格式统一:将异构的偏好数据、可验证推理数据和开放式指令数据,统一重构为适用于 GRPO 训练的信号格式。
自我奖励循环:针对开放式指令,模型生成多个候选回答后,自主调用其“裁判”角色进行评分,并将结果作为 GRPO 训练的奖励信号,形成一个高效的自我改进循环。
协同进化机制:通过在同一批次中混合处理三类数据,模型的生成能力与评判能力得以协同进化。生成能力提升带动评判更精准,而精准评判进一步引导生成质量跃升,从而突破静态奖励模型的性能瓶颈。
实验结果显示,基于 Qwen2.5-7B 模型,URPO 框架超越依赖独立奖励模型的传统基线:在 AlpacaEval 指令跟随榜单上,得分从 42.24 提升至 44.84;在综合推理能力测试中,平均分从 32.66 提升至 35.66。作为训练的“副产品”,该模型内部自然涌现出的评判能力在 RewardBench 奖励模型评测中取得 85.15 的高分,表现优于其替代的专用奖励模型(83.55 分)。
IT之家从摩尔线程官方获悉,目前,URPO 已在摩尔线程自研计算卡上实现稳定高效运行。同时,摩尔线程已完成 VERL 等主流强化学习框架的深度适配



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











