




IT之家 9 月 19 日消息,小米今天宣布开源首个原生端到端语音大模型 Xiaomi-MiMo-Audio,首次在语音领域实现基于 ICL 的少样本泛化。
据小米介绍,五年前 GPT-3 首次展示了通过自回归语言模型 + 大规模无标注数据训练,获得 In-Context Learning(ICL,上下文学习)能力,而在语音领域,现有的大模型仍严重依赖大规模标注数据,难以适应新任务达到类人智能。
而 Xiaomi-MiMo-Audio 模型打破了这种瓶颈,它基于创新预训练架构和上亿小时训练数据,在智商、情商、表现力与安全性在内的跨模态对齐能力均有提升,在自然度、情感表达和交互适配方面呈现出拟人化水准。
这款模型的具体创新点如下:
首次证明把语音无损压缩预训练 Scaling 至 1 亿小时可以“涌现”出跨任务的泛化性,表现为 Few-Shot Learning 能力。
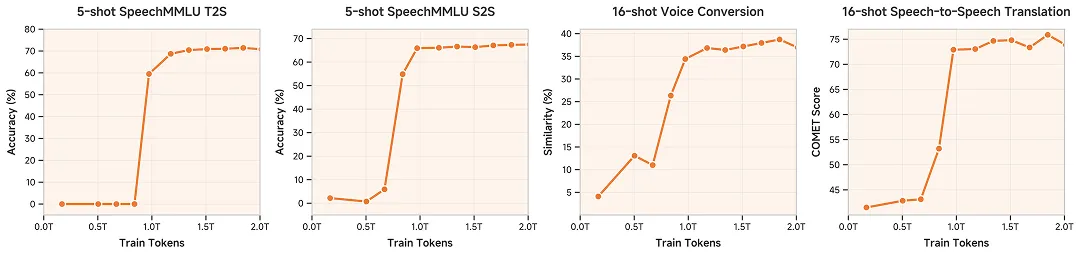
首个明确语音生成式预训练的目标和定义,并开源一套完整的语音预训练方案,包括无损压缩的 Tokenizer、全新模型结构、训练方法和评测体系。
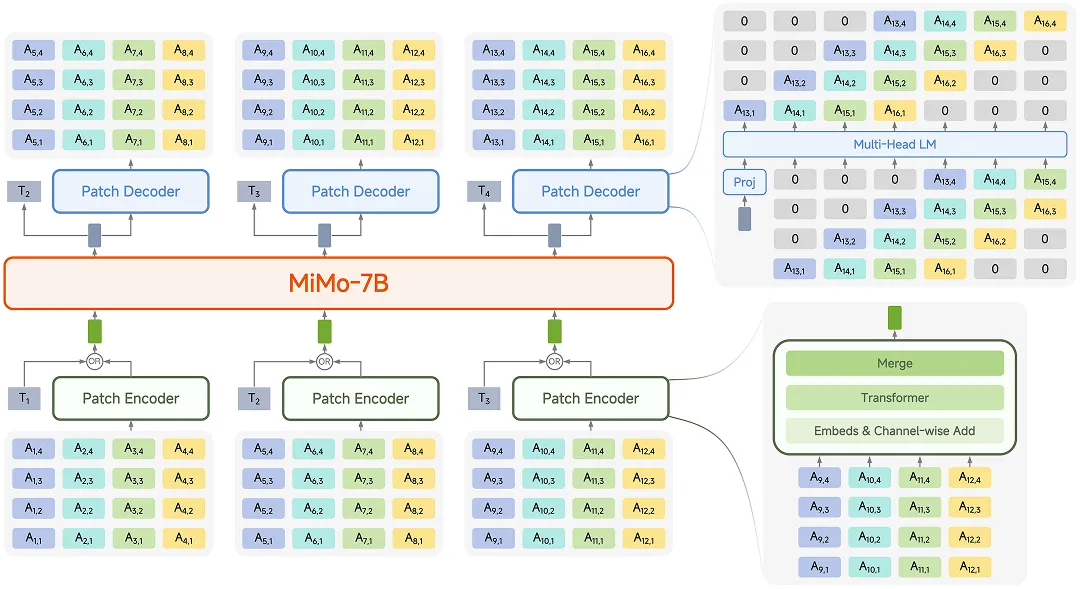
目前小米已在 Huggingface 平台开源了这款模型的预训练、指令微调模型,同时在 Github 平台开源了 Tokenizer 模型,其参数量达 1.2B,基于 Transformer 架构,支持音频重建任务和音频转文本任务。



新浪科技公众号

“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











