




T-MAC 是一种创新的基于查找表(LUT)的方法,专为在 CPU 上高效执行低比特大型语言模型(LLMs)推理而设计,无需权重反量化,支持混合精度矩阵乘法(mpGEMM),显著降低了推理开销并提升了计算速度。

为增强设备上的智能性,在边缘设备部署大型语言模型(LLMs)成为了一个趋势,比如微软的 Windows 11 AI + PC。
目前部署的大语言模型多会量化到低比特。然而,低比特 LLMs 在推理过程中需要进行低精度权重和高精度激活向量的混合精度矩阵乘法(mpGEMM)。现有的系统由于硬件缺乏对 mpGEMM 的原生支持,不得不将权重反量化以进行高精度计算。这种间接的方式导致了显著的推理开销,并且无法随着比特数进一步降低而获得加速。
为此,微软亚洲研究院、中国科学技术大学、中国科学院大学的研究人员联合开发了 T-MAC。T-MAC 采用基于查找表(LUT)的计算范式,无需反量化,直接支持混合精度矩阵乘,其高效的推理性能以及其统一且可扩展的特性为在资源受限的边缘设备上实际部署低比特 LLMs 铺平了道路。

代码:https://github.com/ microsoft / T-MAC
论文:https://www.arxiv.org/ pdf/2407.00088
此外,当前大模型的部署普遍依赖于专用加速器,如 NPU 和 GPU 等,而 T-MAC 可以摆脱专用加速器的依赖,仅利用 CPU 部署 LLMs,推理速度甚至能够超过同一片上的专用加速器,使 LLMs 可以部署在各类包括 PC、手机、树莓派等边缘端设备。T-MAC 现已开源。
在 CPU 上高效部署低比特大语言模型
T-MAC 的关键创新在于采用基于查找表(LUT)的计算范式,而非传统的乘累加(MAC)计算范式。T-MAC 利用查找表直接支持低比特计算,从而消除了其他系统中必须的反量化 (dequantization) 操作,并且显著减少了乘法和加法操作的数量。
经过实验,T-MAC 展现出了卓越的性能:在配备了最新高通 Snapdragon X Elite 芯片组的 Surface AI PC 上,3B BitNet-b1.58 模型的生成速率可达每秒 48 个 token,2bit 7B llama 模型的生成速率可达每秒 30 个 token,4bit 7B llama 模型的生成速率可达每秒 20 个 token。
这甚至超越了 NPU 的性能!
当部署 llama-2-7b-4bit 模型时,尽管使用 NPU 可以生成每秒 10.4 个 token,但 CPU 在 T-MAC 的助力下,仅使用两核便能达到每秒 12.6 个 token,最高甚至可以飙升至每秒 22 个 token。
这些都远超人类的平均阅读速度,相比于原始的 llama.cpp 框架提升了 4 至 5 倍。
即使在较低端的设备如 Raspberry Pi 5 上,T-MAC 针对 3B BitNet-b1.58 也能达到每秒 11 个 token 的生成速率。T-MAC 也具有显著的功耗优势:达到相同的生成速率,T-MAC 所需的核心数仅为原始 llama.cpp 的 1/4 至 1/6,降低能耗的同时也为其它应用留下计算资源。
值得注意的是,T-MAC 的计算性能会随着比特数的降低而线性提高,这一现象在基于反量化去实现的 GPU 和 NPU 中是难以观察到的。但 T-MAC 能够在 2 比特下实现单核每秒 10 个 token,四核每秒 28 个 token,大大超越了 NPU 的性能。
 图 1 BitNet on T-MAC vs llama.cpp on Apple M2
图 1 BitNet on T-MAC vs llama.cpp on Apple M2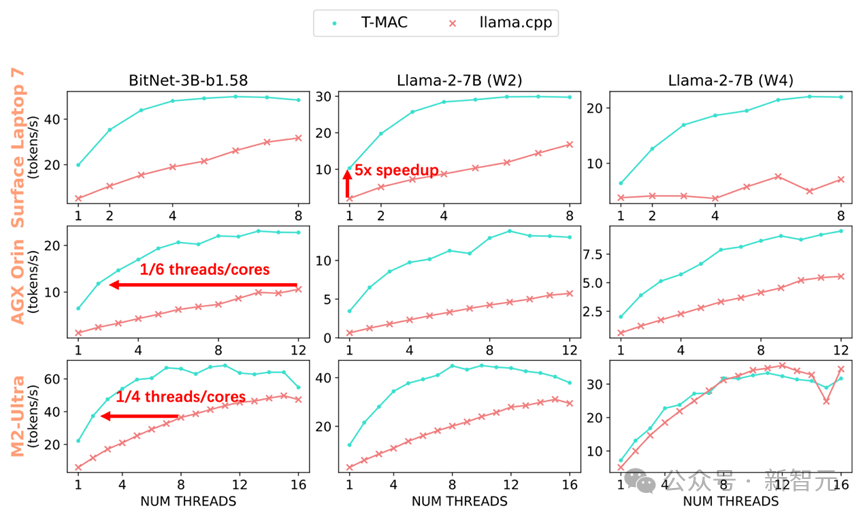
图 2 在不同端侧设备 CPU(Surface Laptop 7, NVIDIA AGX Orin, Apple M2-Ultra)的各核数下 T-MAC 和 llama.cpp 的 token 生成速度可达 llama.cpp 的 4-5 倍。达到相同的生成速率,T-MAC 所需的核心数仅为原始 llama.cpp 的 1/4 至 1/6
矩阵乘不需乘,只需查表 (LUT)
对于低比特参数 (weights),T-MAC 将每一个比特单独进行分组(例如,一组 4 个比特),这些比特与激活向量相乘,预先计算所有可能的部分和,然后使用 LUT 进行存储。
之后,T-MAC 采用移位和累加操作来支持从 1 到 4 的可扩展位数。通过这种方法,T-MAC 抛弃了 CPU 上效率不高的 FMA(乘加)指令,转而使用功耗更低效率也更高的 TBL / PSHUF(查表)指令。
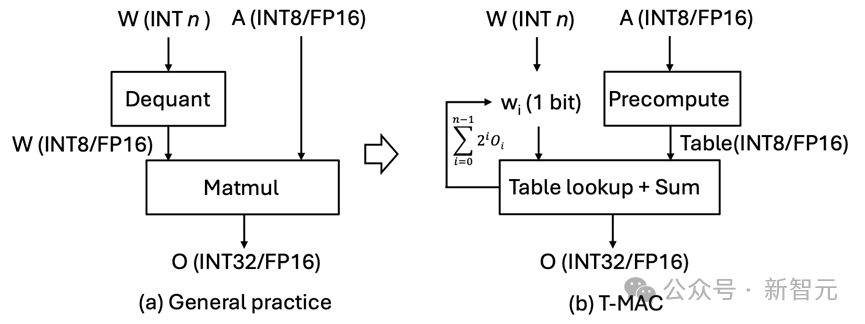 图 3 混合精度 GEMV 基于现有反量化的实现范式 vs T-MAC 基于查找表的新范式
图 3 混合精度 GEMV 基于现有反量化的实现范式 vs T-MAC 基于查找表的新范式以比特为核心的计算,取代以数据类型为核心的计算
传统的基于反量化的计算,实际上是以数据类型为核心的计算,这种方式需要对每一种不同的数据类型单独定制。
每种激活和权重的位宽组合,如 W4A16(权重 int4 激活 float16)和 W2A8,都需要特定的权重布局和计算内核。
举个例子,W3 的布局需要将 2 位和另外 1 位分开打包,并利用不同的交错或混洗方法进行内存对齐或快速解码。然后,相应的计算内核需要将这种特定布局解包到硬件支持的数据类型进行执行。
而 T-MAC 通过从比特的视角观察低比特矩阵乘计算,只需为单独的一个比特设计最优的数据结构,然后通过堆叠的方式扩展到更高的 2/3/4 比特。
同时,对于不同精度的激活向量(float16 / float32 / int8),仅有构建表的过程需要发生变化,在查表的时候不再需要考虑不同的数据结构。
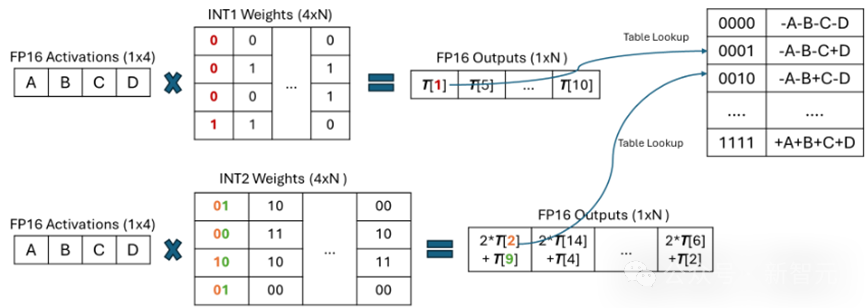 图 4 以比特为核心的查表计算混合精度 GEMV
图 4 以比特为核心的查表计算混合精度 GEMV同时,传统基于反量化的方法,从 4-比特降低到 3/2/1-比特时,尽管内存占用更少,但是计算量并未减小,而且由于反量化的开销不减反增,性能反而可能会更差。
但 T-MAC 的计算量随着比特数降低能够线性减少,从而在更低比特带来更好加速,为最新的工作 BitNet,EfficientQAT 等发布的 1-比特 / 2-比特模型提供了高效率的部署方案。
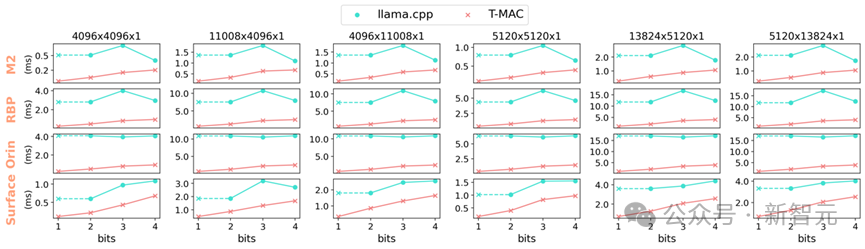
图 5 使用不同端侧设备 CPU 的单核,T-MAC 在 4 到 1 比特的混合精度 GEMV 算子相较 llama.cpp 加速 3-11 倍。T-MAC 的 GEMM 耗时能随着比特数减少线性减少,而基于反量化的 llama.cpp 无法做到(1 比特 llama.cpp 的算子性能由其 2 比特实现推算得到)
高度优化的算子实现
基于比特为核心的计算具有许多优势,但将其实现在 CPU 上仍具有不小的挑战:
(1)与激活和权重的连续数据访问相比,表的访问是随机的。表在快速片上内存中的驻留对于最终的推理性能尤为重要;
(2)然而,片上内存是有限的,查找表(LUT)方法相比传统的 mpGEMV 增大了片上内存的使用。这是因为查找表需要保存激活向量与所有可能的位模式相乘的结果。这比激活本身要多得多。
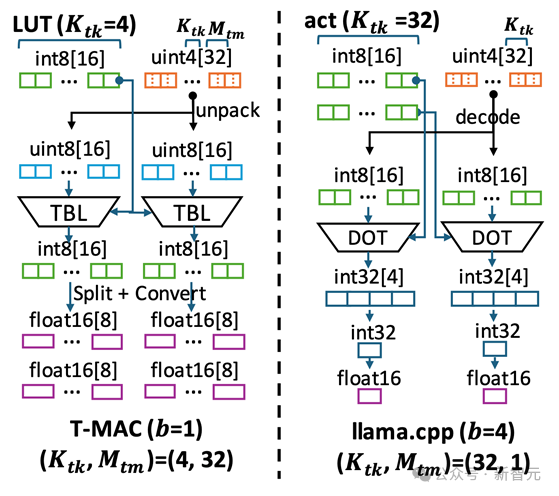 图 6 T-MAC 与 llama.cpp 在计算数据流上的不同
图 6 T-MAC 与 llama.cpp 在计算数据流上的不同为此,微软亚洲研究院的研究员们深入探究了基于查表的计算数据流,为这种计算范式设计了高效的数据结构和计算流程,其中包括:
1. 将 LUT 存入片上内存,以利用 CPU 上的查表向量指令(TBL / PSHUF)提升随机访存性能。
2. 改变矩阵 axis 计算顺序,以尽可能提升放入片上内存的有限 LUT 的数据重用率。
3. 为查表单独设计最优矩阵分块(Tiling)方式,结合 autotvm 搜索最优分块参数
4. 参数 weights 的布局优化
a)weights 重排,以尽可能连续访问并提升缓存命中率
b)weights 交错,以提升解码效率
5. 对 Intel / ARM CPU 做针对性优化,包括
a)寄存器重排以快速建立查找表
b)通过取平均数指令做快速 8-比特累加
研究员们在一个基础实现上,一步步应用各种优化,最终相对于 SOTA 低比特算子获得显著加速:
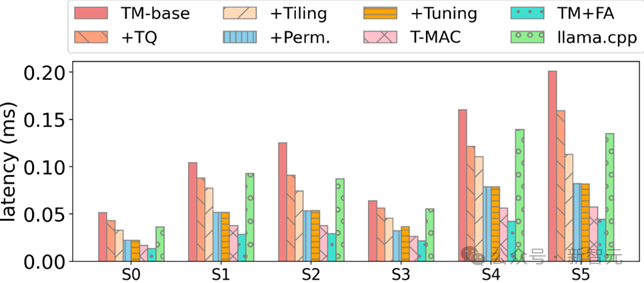 图 7:在实现各种优化后,T-MAC 4-比特算子最终相对于 llama.cpp 获得显著加速
图 7:在实现各种优化后,T-MAC 4-比特算子最终相对于 llama.cpp 获得显著加速广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











