




助力 AI 数字人落地,FACEGOOD (量子动力)正式开源语音驱动表情技术 Audio2Face 技术。本文是对该技术的简要概述。
目前,元宇宙热潮下,AI 数字人也开始涉及众多领域,包含文娱、服务、教育、营销等。市面上出现的 AI 数字人包括功能型 AI 数字人,如虚拟助手、虚拟导游、虚拟客服等;陪伴型 AI 数字人,如虚拟伴侣、虚拟家属等;社会型 AI 数字人,如虚拟主播、虚拟偶像、虚拟教师、虚拟医生、虚拟导购等。
 浦发银行的首位银行业数字员工「小浦」
浦发银行的首位银行业数字员工「小浦」 虎牙 AI 数字人晚玉
虎牙 AI 数字人晚玉 搜狐新闻客户端联合搜狗推出的首个明星「AI 数字人」主播。
搜狐新闻客户端联合搜狗推出的首个明星「AI 数字人」主播。为了实现虚拟数字人的多域化渗透,让更多 AI 数字人的场景落地,FACEGOOD 决定将语音驱动口型的算法技术正式开源,这是 AI 虚拟数字人的核心算法,技术开源后将大程度降低 AI 数字人的开发门槛。
项目地址:https://github.com/FACEGOOD/Audio2Face
项目背景
2019 年,第十届中国国际新媒体短片节组委会和 FACEGOOD 联合发布陆川导演 AI 数字人。
 陆川导演 AI 数字人形象
陆川导演 AI 数字人形象观众可以和 AI 数字陆川面对面互动交流,为观众带来打破虚拟空间和现实空间次元壁的实时实感交流互动体验。为了能达到实时交互的效果,FACEGOOD 开发了一套数字人实时语音交互系统,实现了语音到表情动画的实时转换。
如今,FACEGOOD 选择将全套语音驱动表情的技术代码开源,免费提供给广大数字人开发者使用。
技术解读
该技术可以将语音实时转换成表情 blendshape 动画。这样做的原因是在现行的产业中,用 BS 去驱动数字形象的动画表情仍是主流,方便动画艺术家对最终动画产出最艺术调整,传输的数据量小,方便动画在不同的数字形象之间进行传递等等。
基于这些实际生产中的需求,FACEGOOD 对输入和输出数据做了相应的调整,声音数据对应的标签不再是模型动画的点云数据而是模型动画的 blendshape 权重。最终的使用流程如下图 1 所示:
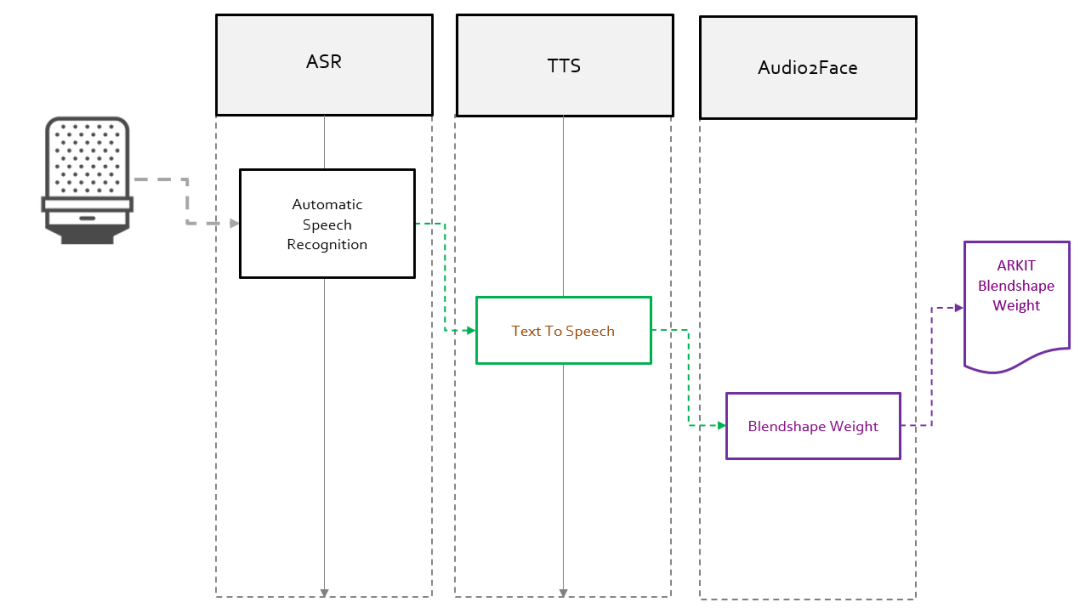
在上面的流程中,FACEGOOD 主要完成 Audio2Face 部分,ASR、TTS 由思必驰智能机器人完成。如果你想用自己的声音,或第三方的,ASR、TTS 可以自行进行替换。
当然,FACEGOOD Audio2face 部分也可根据自己的喜好进行重新训练,比如你想用自己的声音或其它类型的声音,或者不同于 FACEGOOD 使用的模型绑定作为驱动数据,都可以根据下面提到的流程完成自己专属的动画驱动算法模型训练。
那么 Audio2Face 这一步的框架是什么样呢?又如何制作自己的训练数据呢?具体如下图 2 所示:
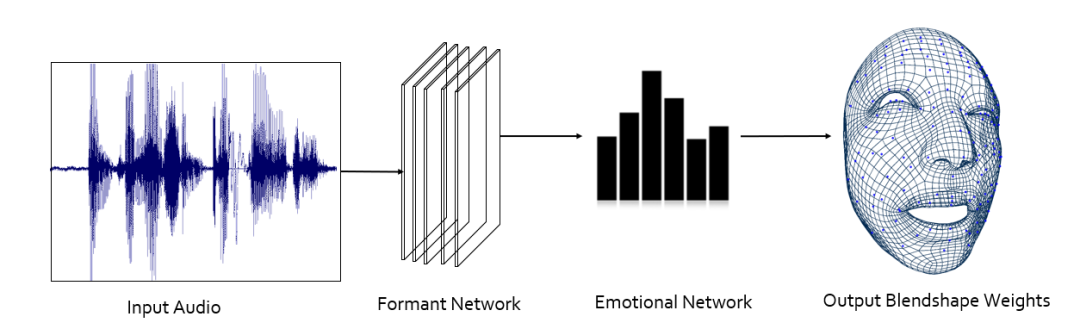
常规的神经网络模型训练大致可以分为三个阶段:数据采集制作、数据预处理和数据模型训练。
第一阶段,数据采集制作。这里主要包含两种数据,分别是声音数据和声音对应的动画数据。声音数据主要是录制中文字母表的发音,以及一些特殊的爆破音,包含尽可能多中发音的文本。而动画数据就是,在 maya 中导入录制的声音数据后,根据自己的绑定做出符合模型面部特征的对应发音的动画;
第二阶段,主要是通过 LPC 对声音数据做处理,将声音数据分割成与动画对应的帧数据,及 maya 动画帧数据的导出。
第三阶段就是将处理之后的数据作为神经网络的输入,然后进行训练直到 loss 函数收敛即可。
最后来看两段效果展示视频:



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











