




来源:机器之心
作者:仵冀颖
编辑:Joni
在各种任务中人类的学习能力和机器的学习能力究竟哪个更胜一筹?
随着 AI 的不断研究和发展,各类 AI 算法在不同场景中的应用层出不穷,关于 AI 及其在日常任务中支持甚至取代人类工作的能力的讨论无处不在。例如,在自动驾驶领域,尽管在目前的条件下自动汽车还不能完全替代人类,但关于何时能够完全取代人类驾驶员的问题仍然受到了高度关注。从长远来看,使用 AI 替代人类并非不可能,但是这种替代是否能在所有工作场景中实现?
目前,一些 AI 胜过人类的场景主要出现在有大量可用训练数据或标注图像的机器学习领域中,例如 Google 的 DeepMind AlphaGO 游戏等。而在样本数据很少或完全无监督的情况下,AI 的水平还很有局限性。在这篇文章中,我们关注 Human vs AI 的问题,即在不同的任务中人类的学习能力和机器的学习能力究竟哪个更胜一筹?他们的差距究竟还有多大?
1 Human & AI,怎么学习?
1.1 人类学习
首先,我们先来看看人类学习的方法和能力。
目前,关于人类学习的研究主要包括三种方向:认知心理学(Cognitive psychology)、社会认知理论(Social cognitive theory)和社会文化理论(Sociocultural theory)。
认知心理学是“研究人们如何感知、学习、记忆和思考信息的学科”。认知心理学的研究包括研究心理现象,如视觉感知、物体识别、注意、记忆、知识、言语感知、判断和推理。目前机器学习领域中的监督学习就是参考认知心理学的神经科学(Neuroscience)和脑功能(Brain functioning)发展而来的。
社会认知理论也包含了一些与认知心理学类似的观点,但它更关注人类如何通过观察和模仿他人的行为来向他人学习。社会认知理论表明人类是可以控制自己的学习的。与从自己的经验中学习相比,社会认知理论中所强调的向他人学习还有一个好处,即通过减少犯错来更快地学习。
社会文化理论强调社会和文化在学习中的重要性。学习一种像语言这样的社会文化工具不仅有助于交流,而且有助于人类的思维发展。与社会认知理论不同的是,人类不仅相互学习,而且共同努力实现个人无法实现的目标。例如,社会文化理论研究的重点是儿童与父母的互动。儿童个人能力的发展通常与他 / 她和父母的互动有关。此外,父母可以扩大孩子解决问题的能力,刺激认知能力的增长。
1.2 人工智能学习
然后,我们来看看人工智能究竟是如何进行学习的?
目前,关于人工智能的学习已经覆盖到了知识获取、理解、感知、创造甚至是做出道德评判等多个层面。例如,可以利用人脸识别技术抓捕犯人,利用图像识别技术识别不戴口罩、不按规程操作的明厨亮灶监控报警等等。以机器学习的人工智能技术为例,它描述的是在计算机系统帮助下解决各种实际任务的技术,这些计算机系统 / 程序可以通过学习来解决一个任务,而不是通过显式编程的方式来完成任务。机器学习的方法也包括有监督的方法、无监督的方法和增强学习方法等等。
无监督机器学习主要是指能够揭示先前未知数据模式的方法和算法。由于不存在假设的真值(Ground truth),无监督学习不一定能够找到 “正确的” 解决方案,比如 k-means 能因为根据不同的初始条件获得不同答案。属于半监督学习的强化学习基于单纯的奖励和惩罚讯号使得模型通过不断学习新的样本实例来改进算法或模型的效果。对于有监督学习,“学习”意味着使用一系列样本实例和对应的“答案”(“过去的经验”)来建立关于给定任务的知识。虽然在学习过程中经常会引入统计方法,但并不需要手动调整模型或进行编程来解决任务。更详细地说,有监督学习旨在通过对一组已知的数据应用一个算法来构建一个模型,从而能够解决未知数据集中的任务。一般来讲,有监督学习依赖于大规模的先验数据。
1.3 人类 vs 人工智能学习
关于对比人类和 AI 学习的能力,Hernandez-Orallo 首次提出了关于自然和人工智能的比较[1]。此外,专门的神经科学(Neuroscience)这一领域的研究也涉及了一些关于 human vs AI 的讨论。它的目的是从理论上去理解人类学习和机器的相互促进作用。一些研究人员分别从创造力测试(Creativity Tests)、人脸识别(Face Recognition)、音乐预测(Music Prediction)、计算机视觉(Computer Vision)、IQ 测试(IQ Tests)和认知研究(Cognitive Research)等不同应用场景对人类和机器的相互促进能力进行了理论和实证分析。
不过,目前直接对比人类和机器的学习能力和完成任务能力的系统性、深入性的理论和实证研究还较少。在这篇文章中,我们列举了一些有趣的 human vs AI 的竞赛。竞赛任务类型涵盖了逻辑分类、图像处理、文本生成、IQ 测试等。从竞赛的结果看,人类的学习能力还是明显占上风的。也许正如一些研究人员提出的,目前的机器是非常 Diligent(勤奋刻苦的),但距离真正的像人类一样的 Intelligent(聪明智能的)还有很长很长的路要走。
2 人类与 AI 的竞赛
在这一节中,我们选择了几个人类与 AI 的竞赛结果进行分析。这里,用于竞赛的人工智能方法既包括以深度学习为代表的机器学习算法 / 模型,也包括一些经典的算法和模型。
2.1 图像修复(Image Inpainting)能力对比
这个竞赛关注的是图像处理中的一个应用领域:图像修复(Image Inpainting)。
实验地址:https://github.com/xitu/gold-miner/blob/master/TODO1/image-inpainting-humans-vs-ai.md
Image Inpainting 的主要任务是填充图像中的信息缺失区域,补足这些信息,使修补后的图像看起来真实、自然。这项技术也可以用于去除掉图像中的某些区域,使处理后的图像不失真,因此在老照片修复、遥感图像处理等领域中非常重要。下图是最经典的图像修复实验结果。

图 1. 图像修复示例,移除目标物[2]
图像修复并不是 AI 时代新兴的技术,而是一门古老的艺术,最初是由人类艺术家手工完成的。但是今天,研究人员提出了许多自动修复方法。作为自动处理算法,除了待修复的图像外还必须输入一个显示待修复区域的掩码作为输入。在这个实验中,作者将九种自动修复方法与专业艺术家的结果进行比较。
作者从私人收藏的照片中剪切出 33 个 512×512 像素的图像以构建实验所用的图像数据集。然后用黑色在每个照片中心画一个 180×180 像素的方块。人类艺术家和自动修复方法的任务都是通过改变黑方块(掩码区域)中的像素来恢复失真图像。作者使用的是私人的、未公开的照片集,以确保在实验中人类艺术家并没有提前看到过原始图像。尽管在实际应用中,掩模的形状不一定是规则的,但在实验中还是使用了正方形的掩模,因为实验中有些 DNN 方法仅能使用正方形掩模进行处理。作者使用的照片示例如下:

图2. 样本照片示例
实验中使用了九种自动修复方法作为机器学习的方法示例,其中,前六种方法为以神经网络为基础的机器学习方法,后三种是深度学习爆发之前的计算机自动处理方法。具体包括:
(1)深度图像先验 Deep Image Prior,https://arxiv.org/abs/1711.10925
(2)全局和局部一致性图像修复 Globally and Locally Consistent Image Completion,http://iizuka.cs.tsukuba.ac.jp/projects/completion/en/
(3)高分辨率图像修复 High-Resolution Image Inpainting,https://arxiv.org/abs/1611.09969
(4)移位网 Shift-Net,https://arxiv.org/abs/1801.09392
(5)语境注意力的生成图像修复 Generative Image Inpainting With Contextual Attention,https://arxiv.org/abs/1801.07892
(6)基于部分卷积的不规则孔洞图像修复 Image Inpainting for Irregular Holes Using Partial Convolutions,https://arxiv.org/abs/1804.07723
(7)基于范例填充的图像修复 Exemplar-Based Image Inpainting(本竞赛中考虑了两种不同大小修复块(Examplar Patch)的情况),http://www.irisa.fr/vista/Papers/2004_ip_criminisi.pdf
(8)用于图像修复的面片偏移量统计 Statistics of Patch Offsets for Image Completion,http://kaiminghe.com/eccv12/index.html
(9)Adobe 自带的内容感知填充 Content-Aware Fill in Adobe Photoshop CS5
为完成人工处理,作者找到三位艺术家从每一组照片中随机挑选照片来修复。为了鼓励他们做出最好的结果,作者还告诉每位艺术家,如果他或她的作品超过竞争对手,将会酬金中增加 50% 的奖金。虽然实验中并没有规定严格的时间限制,但艺术家们都在大约 90 分钟内完成了任务。
作者将三位专业艺术家的修复结果和自动修复方法的修复结果与原始的、未失真的图像(ground truth)进行了比较。比较使用的是 Subjectify.us (http://subjectify.us/)平台(一个众包主观质量评价平台,Crowd-sourced subjective quality evaluation platform)。这个平台以成对的方式向参与者展示研究结果,让他们从每一对中选择视觉质量最好的图像。为了确保参与者做出深思熟虑的选择,平台还通过让参与者比较真实图像和基于样本的图像修复结果来进行验证。共收集了来自平台的 69215 名参与者的判断结果。
以下是本次比较的总体和每幅图像的主观质量分数:

图3. 艺术家和自动方法的图像修复结果主观评价对比
从这个竞赛的结果可以看出,艺术家们的表现在大多数照片中大大超过了自动方法。只在一种情况下有一种算法击败了艺术家:用非神经网络方法(8、Statistics of Patch Offsets for Image Completion)修复的 “Urban Flowers” 图像比艺术家 1(Artist#1)绘制的图像排名更高。此外,艺术家修复的图像与原始未失真图像的效果不相上下,甚至看起来更好:艺术家 2(Artist#2)和艺术家 3(Artist#3)修复的 “Splashing Sea” 图像的质量分数高于 Ground truth,艺术家 3(Artist#3)修复的 “Urban Flowers” 图像的得分仅略低于 Ground truth。所以,在图像修复的任务中,人类还是远胜于机器的。不过值得注意的是,在这个实验中,参与者是艺术家,也就是说,是具备一定绘画和艺术能力的人。对于普通人来说,他的修复能力就一定能比机器好么?
在自动修复方法中,效果最好的是生成方法(5、Generative Image Inpainting With Contextual Attention),但也并不是一种压倒性的胜利。从上面的对比结果也可以看出,这种方法在几种照片中都没获得最佳分数。“Urban Flowers”和 “Splashing Sea” 的第一名分别是(8、Statistics of Patch Offsets for Image Completion)和(7、Exemplar-Based Image Inpainting),“Forest Trail”的第一名是(6、Image Inpainting for Irregular Holes Using Partial Convolutions)。值得注意的是,根据总体排行榜,深度学习方法的表现是优于非神经网络方法的。
我们可以从这个竞赛中得到下述推断:
对于图像修复 Image Inpainting 来说,由艺术家进行修复还是最好的选择(图中标注为红色的条块),机器的修复结果往往差强人意(图中标注为蓝色、绿色的条块)。
对于一些特定的图片,机器学习的方法也可以取得不错的效果。但是 “特定” 的特征和范围是什么?在这个竞赛中还缺乏系统性、深入性的分析。所以这种 “特定” 对于实际应用还是缺乏指导作用的。
在这个竞赛中,总体上机器学习的所谓 AI 方法要优于经典的图像处理方法(图中标注为蓝色的条块)。不过对于一些图片库来说,经典方法仍然是有优势的,AI 方法并没有压倒性的优势。
机器学习方法对于输入的掩模形状是有严格要求的,这与它训练 - 测试 - 应用的工作机制是分不开的。但是人类艺术家或经典方法就没有这种问题,可以处理任意形状的掩模,因此可以应用在多种实际场景中。
作者认为:这一领域的未来研究随着可学习数据量增多、GPU 计算能力提高和内存的增长将使得深度学习算法可能会超越传统的竞争对手,并给出与人类艺术家可以媲美的图像修复结果。然而,作者还是强调,鉴于目前的技术水平,对于 Image Inpainting 来说,选择一种经典的图像或视频处理方法可能比仅仅因为它是新鲜事物而盲目地选择一种机器学习方法要好。
2.2 文本生成能力对比(A/B testing OpenAI's GPT-3)
这是一场人类生成文案(Copyright)和由 OpenAI 的 GPT-3 API支持的 VWO 生成的文案之间的竞赛。
竞赛地址:https://vwo.com/ab-testing-openai-gpt-3/
在这场竞赛中,将测试人工智能生成的标题、按钮或产品描述文案,与现有(或新的)参与网站的人类生成的书面文案进行对比。测试可以在 VWO 或参与者自己使用的任何 A/B 测试平台上进行。在这个竞赛中机器使用的方法就是 GPT-3,而对人类并没有特定限制,可以是任何参与者。
VWO 已经将 OpenAI 的 GPT-3 集成到它的可视化编辑器中,这使得任何人都可以很容易地使用它生成任何语言的文案。这项功能提供给了竞赛网站,为比赛提供了 A/B 测试。所以,小伙伴们都可以到网站上来试试。
目前已经给出的竞赛结果如下图。在 18 份有效参与竞赛中,有 1 项明确人类生成的文案胜过 AI 生成的文案,有 3 项则是判定 AI 获胜,还有 3 项判定是双方平手,其余 11 份则暂无打分(含一项还未最终完成)。
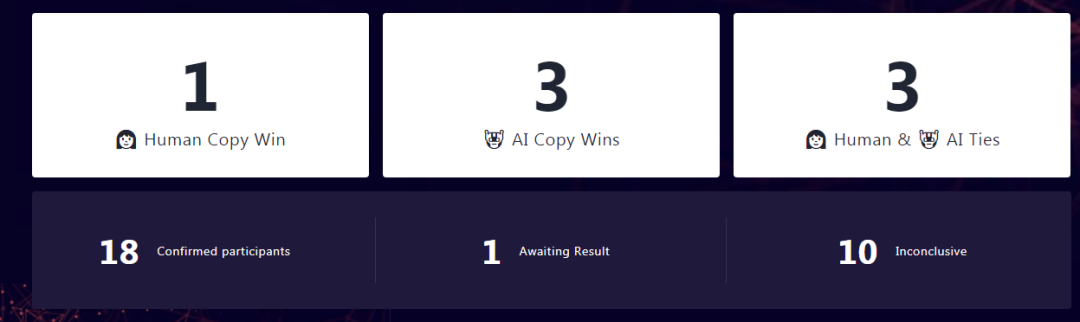
图4. 文本生成竞赛结果
人类生成文案获胜的案例是 Booking.com 网站的竞赛作品(红色框,生成 button 的文案)。具体的人类生成的文案见图 5,AI 生成的文案如图 6。人类生成的文案 Human Copy 1 赢得了这次比赛。展示出的是模糊的屏幕截图以掩盖酒店的身份。
 图5
图5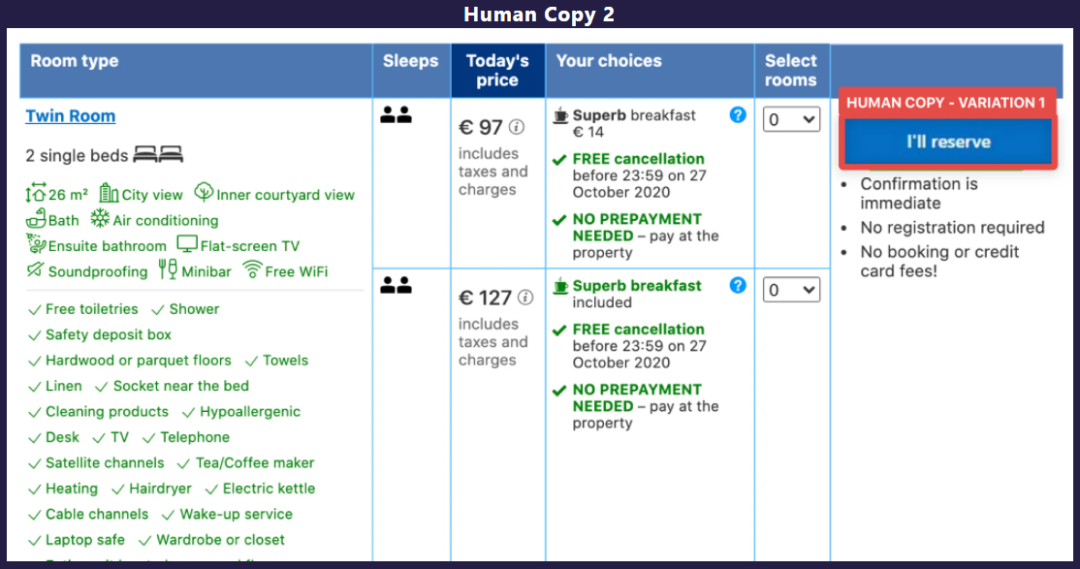
图6. Booking 网站人类生成的文案
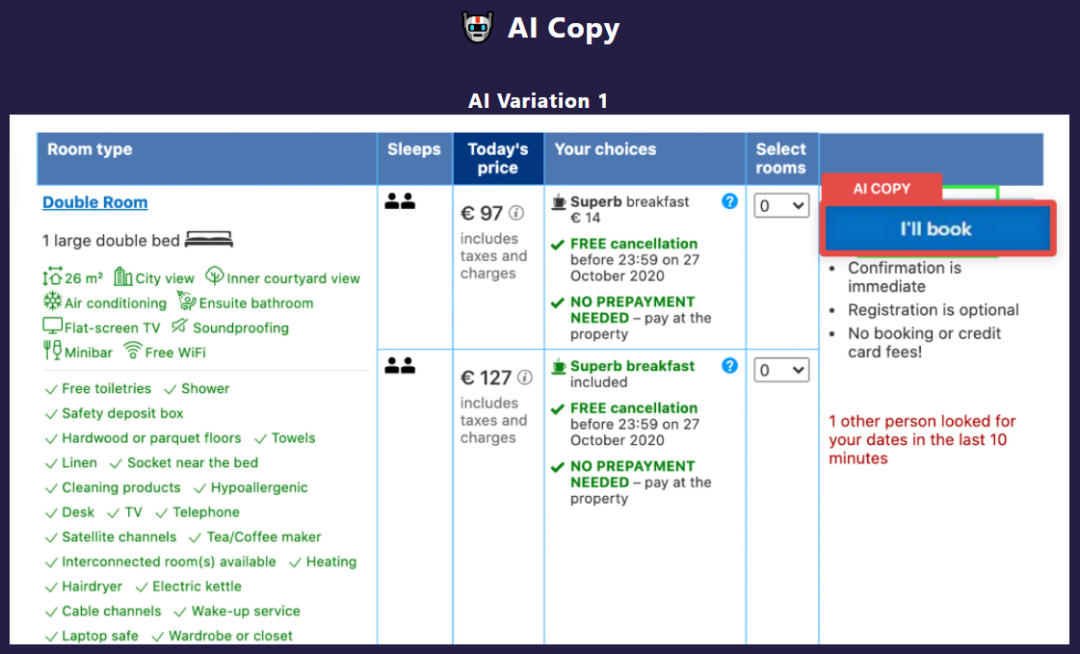
图7. Booking 网站 AI 生成的文案
AI 获胜的文案有三项,我们选择了 Schneiders 的一项实验进行展示(红色框,生成标题的文案)。人类生成的文案如图 8,AI 生成的文案如图 9。我们直观的感受是,AI 生成的标题将 Shop Now 放在最前面,给人的目标性感受更强,更有效。
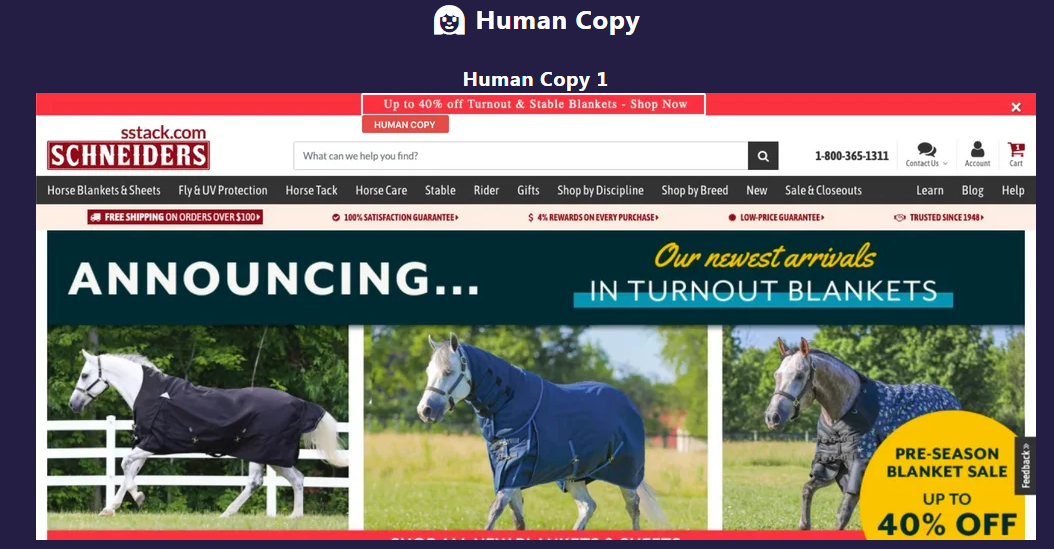
图8. Schneiders 人类生成的文案
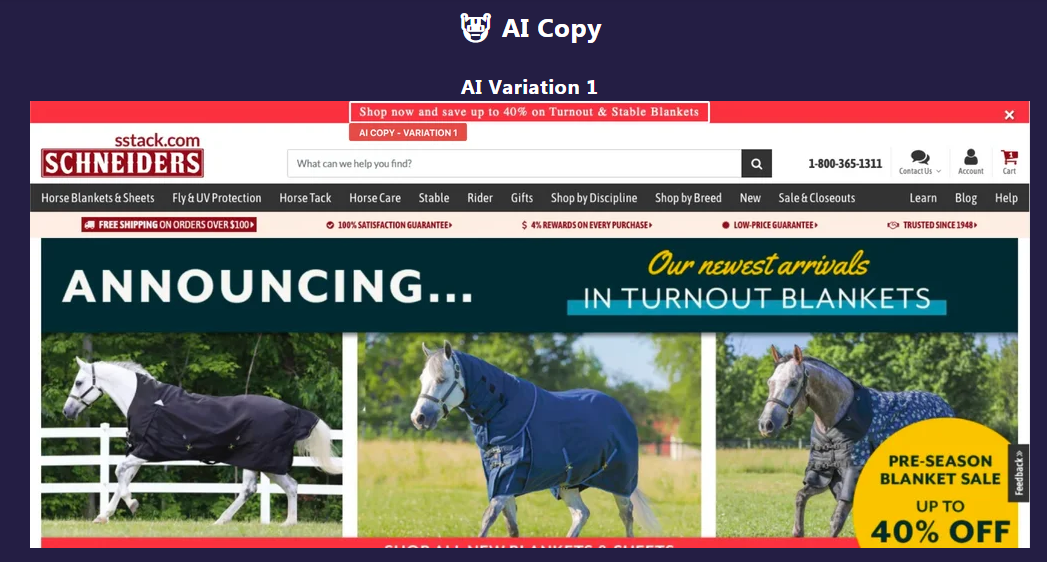
图9. Schneiders AI 生成的文案
从这个竞赛的结果可以看出,在文本生成这个领域,借助于强大的 GPT-3,AI 在实验环境中更胜一筹。当然,竞赛组织者并没对 AI 获胜做任何系统性、深入性的分析,仅仅是将参赛者的结果进行了展示和统计。我们认为,AI 获胜一方面是因为文本生成的先验数据库、预训练模型规模是非常大的。另一方面 GPT-3 等文本生成的算法 / 模型也是相对成熟的,属于 AI/ML 较早在实际场景中应用的方法。最后,参与实验的人类并没有特定的要求,例如对文字撰写、新闻宣传、行业背景有特殊的限定,所以人类生成的文案水平并不是很高。如果对参与者的行业身份、知识背景有所限定,会不会能够提升人类生成文案的水平呢?不过,不管怎样,文本生成领域的 AI 还是展现出了非常高的应用水平和价值。
3 Humans 与 SML(Supervised Machine Learning)
这项工作关于一个学习曲线描述任务,拟解决的是在小样本量的前提下完成二进制分类任务时人类和有监督机器学习模型的学习曲线有哪些不同。具体的工作分析和结果在文献 [3] 中,并以预印的形式发布在 arxiv 中(https://arxiv.org/abs/2012.03661)。
学习曲线(Learning Curve)描述的是基于经验的任务表现。在该例子中,经验是由训练数据(Training Data)的数量来衡量的,更准确地说,是由训练实例(Training Instances)的数量来衡量的。任务表现受两个主要因素影响:执行任务的实体(人或机器)的特征和任务本身的特征。对于该竞赛中的监督式机器学习任务(Supervised Machine Learning,SML)来说,有四个任务特征很重要:输入、输出、实例和特征。
输入。输入描述了任务所依据的数据。它可以按数据类型(例如,数字或二进制)和数据表示方式(例如,表格、图片或音频)来区分。
输出。一个任务的需求产出也是不同的。在这种情况下,有两种类型的输出是相关的:分类和回归。分类确定每个实例是否属于预定的类别之一,而回归的结果是一个连续的数字。
实例。可供学习的实例数量。
特征。一个任务的实例由一定数量的不同特征来描述。
作者选择了一个以二进制作为输入、二进制分类作为输出,包含一小组训练实例和有限数量特征的任务。具体任务特征和实现方式见表 1。
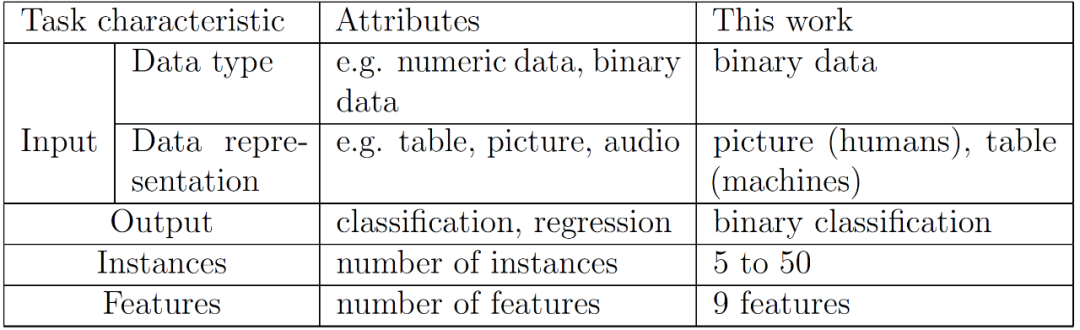
表 1. 相关任务特征概述及其在本工作中的执行情况[3]
作者使用智能测试领域的两个测试任务作为具体实验基础,即最小智能信号测试(Minimum intelligent signal tests,MISTs)和 Raven 的渐进矩阵(Raven's progressive matrices, RPMs)。MISTs 是用来量化人类人格(Humanness)的二进制问题。与其他智力测试相比,这些问题不需要复杂的答案,只需要简单的" 是 "或" 否 ",这就满足了对二进制输出的限制。然而,输入的是自然语音,而不是一组几个、二进制特征。
RPM 是一个关于由规则设计的视觉几何对象的测试。任务是通过从六个或八个选项中选择一个对象来完成一组视觉几何对象,其中,只有一个可选择的对象符合规则。如图 10 的示例,RPMs 有一个图形化的表示方法,可以将其简化为一组带有一些二进制特征的实例,从而得到标准化的实例。但是,这项测试不具备二进制输出。通过结合这两个测试,我们得出以下任务:
为了获得相同数量的特征,只使用 3x3 矩阵,有 9 个元素(=9 个特征),每个特征都是二进制的。据此,有一组 2^9 =512 个二元矩阵。这些矩阵可以显示为黑白元素的图片(对人类而言),也可以显示为特征为 1 和 0 的数字列表(对机器而言)。图 10 给出了同一个实例分别对人类和机器进行表示的例子。
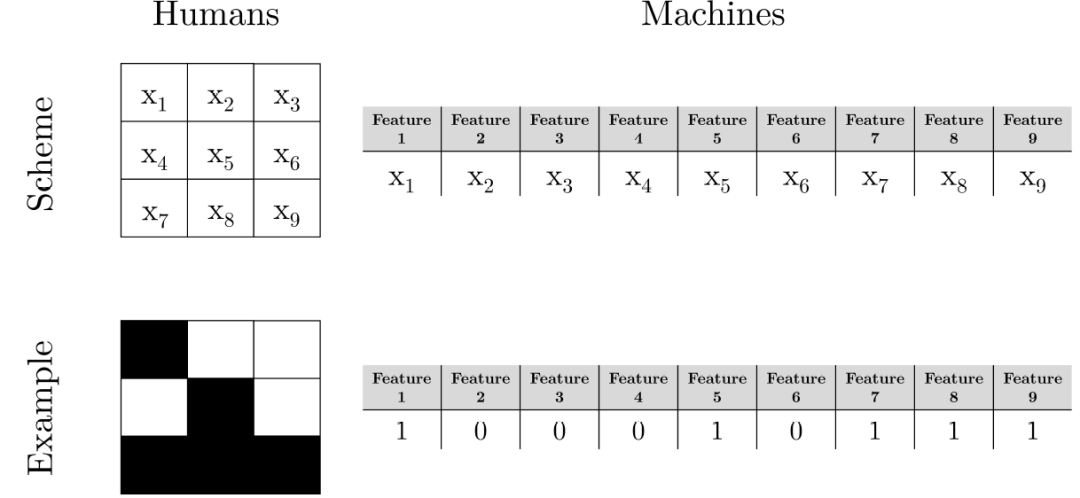 图 10. 具有 x1 至 x9 特征的实例的人和机器示意图
图 10. 具有 x1 至 x9 特征的实例的人和机器示意图根据关于特征值的规则,我们可以对矩阵进行分类。一些实例 (矩阵) 符合规则,因此它们被标记为真,而所有其他不符合规则的实例则标记为假。作者将四种基本模式作为分类任务的四条规则。
对角线(Diagonal)。符合对角线规则的矩阵至少有一条对角线,标为黑色,或者从左上角块开始一直到右下角块结束,或者从左下角块开始,到右上角块结束。
水平的(Horizontal)。符合水平规则的矩阵至少有一排水平的黑色元素。
数字规则(Numbers)。如果总共有五个元素被标为黑色,则满足数字规则。
对称性(Symmetry)。对称性描述的是轴对称性,可以是对矩阵中间列的轴对称性,也可以是对矩阵中间行的轴对称性。
设计一个多回合游戏以生成 一个符合特定规则的学习曲线。在游戏过程中规则不会改变。在游戏开始时,玩家收到访问 5 个标记的实例(训练数据)。确保每个实例被标记为正值的概率为 50%(相应地也有 50% 被标记为负值),以根据所选规则来考虑数据集中正值和负值标记实例的不平衡的问题。此外,玩家还收到 5 个未标记的实例(测试数据),这些实例必须根据从标记的训练实例中得出的知识进行标记。如前所述,每个实例被标记为正的概率仍为 50%。然后,我们用准确度量来衡量测试数据的性能,准确度量表示为正确标注实例的数量除以标注实例的总数量。
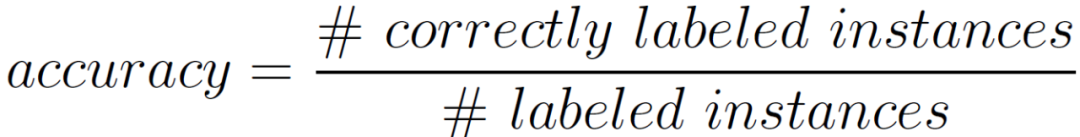
由于在我们的工作中,标签只是一个二进制决策,准确度指标为 "1" 则表示标签 100% 正确,而准确度指标为 "0.5" 则相当于随机猜测,标签是随机分配的。五个实例的标签准确率代表了第 r 轮的表现。在第二轮中,先前标记的实例消失,生成五个新的、未标记的实例(新测试实例),总共有 10 个标注的实例可用于训练。训练中对 5 个新的未标记的实例进行标记,具体图 11 进行了详细描述。在每个游戏中,标记和未标记实例的顺序是随机的。然而,一个矩阵(实例)只会是训练数据或测试数据的一部分,而不会同时是两者。学习曲线是根据每一轮的表现生成的。
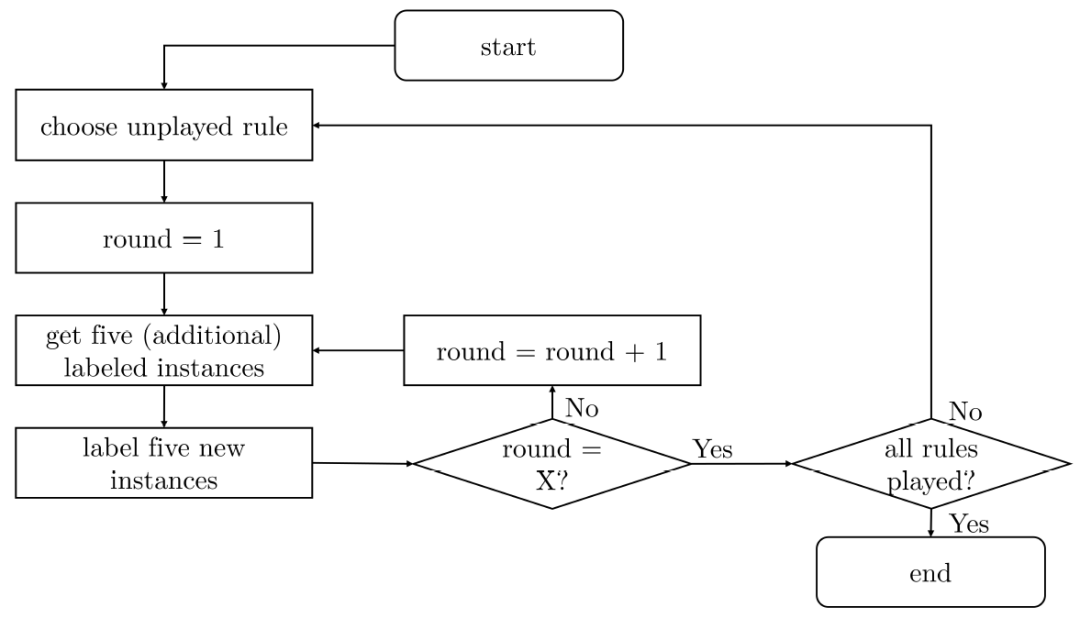
图11. 人类 X=10 轮、机器 X=20 轮的实验过程
人类的实验是通过研究不同环节的参与者进行的,这些人是在没有任何事先知识的情况下单独参加实验的,因此参与者并不是根据特定知识背景、行业能力等进行筛选的。不过,事先他们会得到一份关于实验总体目标、用户界面布局和一些抽象例子的标准化介绍。每位参赛者参与四场游戏,有可能玩遍四种规则。每场总轮数为 10 轮,也就是说,参赛者总共会看到 50 个标签实例,在一局游戏中,有可能需要他 / 她给 50 个实例贴标签。在完成一个游戏后,参与者不会收到任何关于他 / 她表现的反馈,这就保证了每轮游戏的独立性。图 12 是用人类进行规则对称性实验的 GUI 实例。
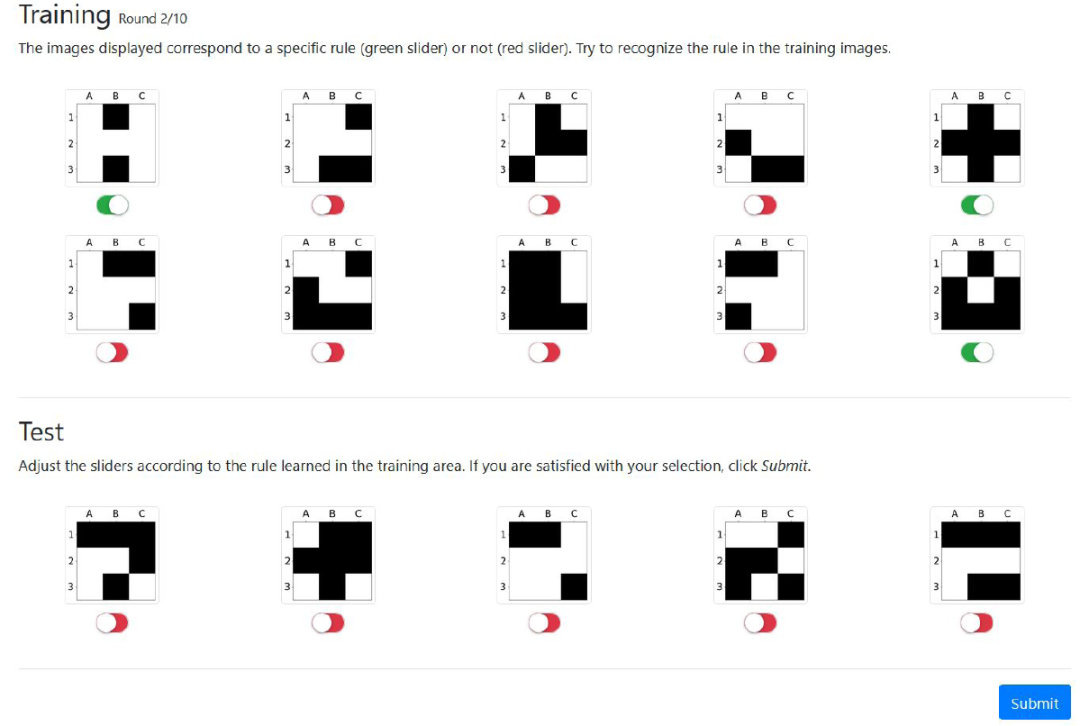 图 12. 规则对称性(Symmetry)的第 2 轮人类的实验截图。上方显示 10 个训练实例,下方则是未标记(测试)的实例
图 12. 规则对称性(Symmetry)的第 2 轮人类的实验截图。上方显示 10 个训练实例,下方则是未标记(测试)的实例作者选择了三种机器学习算法验证 AI 的性能:逻辑回归、决策树和神经网络算法(MLP)。为了增加可比性,在每一个游戏中应用每一个算法时模型的数量与玩游戏的人类数量相同。该算法只对一个游戏进行实例化,并且在每一局游戏结束后都会被终止,这样就不会使用之前游戏的知识。具体针对四种规则的四种任务完成结果见图 13 - 图 16。
关于规则“对角线”(图 13),决策树的表现优于所有其他机器学习模型和人类参与者。不过,在前 50 个训练样本中,决策树的性能与人类相比并没有明显改善。从第 55 个训练样本开始,决策树在 50 个实例中的表现明显优于人类。相比之下,MLP 和逻辑回归与人类相比则表现是差不多的。因此,总的来说,机器学习的方法 / 模型在 50 个训练实例中的表现并没有明显优于人类,但稍好于人类。
关于规则“水平”(图 14),人类在前 50 个训练样本中的表现明显优于机器学习模型。随着提供给机器学习模型学习的训练样本越来越多,从第 55 个训练样本开始,50 个实例的人类和 55 个实例的机器的性能已经没有显著差异。在图 14 的竞赛结果中,人类和机器学习的性能相差不大,只是最后逻辑回归的性能会有所下降。
关于规则“数字规则”(图 15),人类的表现是最好的。从 15 个训练样本开始,人类的性能始终在 90% 以上,而三种机器学习模型的准确率没有任何改进。在整个 100 个训练样本中,机器学习模型准确率一直保持在 "0.5" 左右。因此,在所有轮次的实验中,人类和机器学习模型之间的性能差异是显著的,这从图 15 中也可以很直观的看出来。
关于规则“对称性”(图 16),与数字规则的表现类似,人类的表现优于机器学习模型。在有五个训练样本的情况下,人类的性能明显更好。之后,随着训练样本的增多,人类的性能比机器的性能提高的更多,并且差异变得非常显著。然而,人类性能在 20 个训练样本后达到了其准确率的最大值,低于 0.9,并保持在这一水平上。而 MLP 和决策树的准确率在每一轮都略有提高。
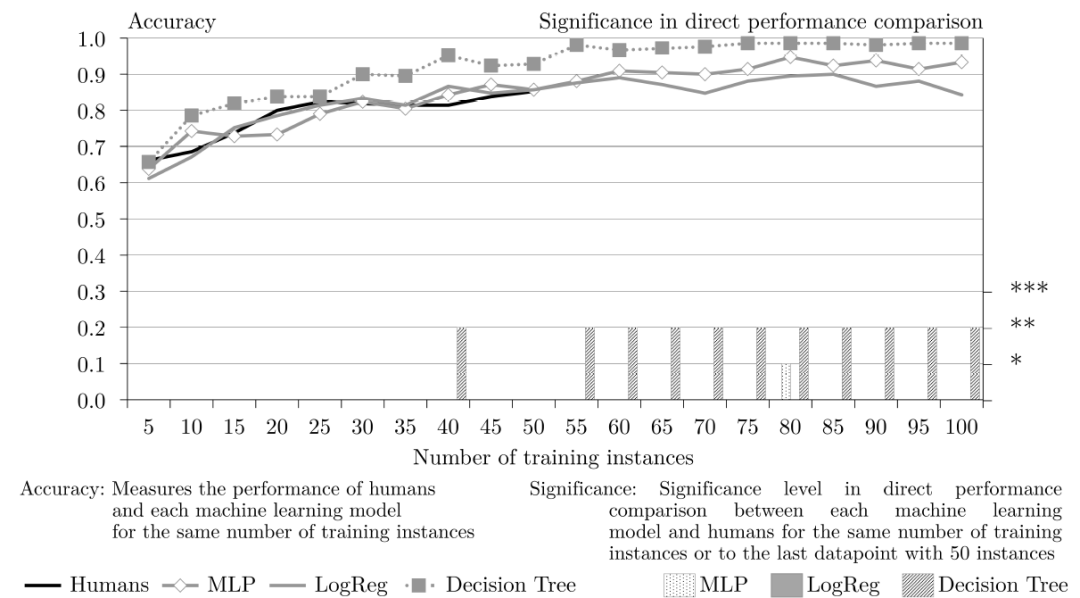
图13. 规则 Diagonal 的人类和机器学习性能比较

图14. 规则 Horizontal 的人类和机器学习性能比较
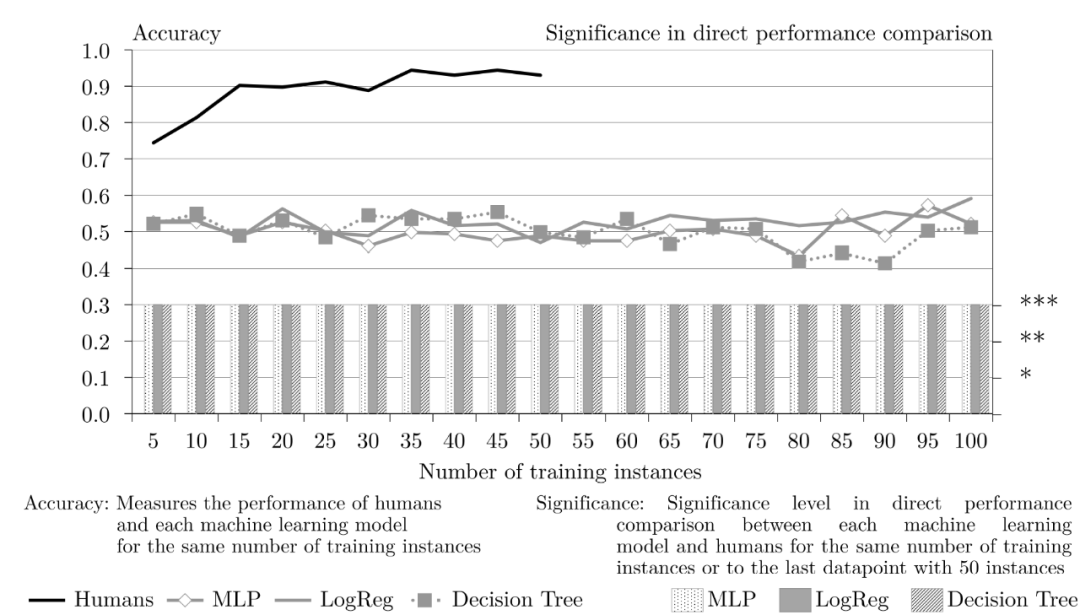
图15. 规则 Numbers 的人类和机器学习性能比较
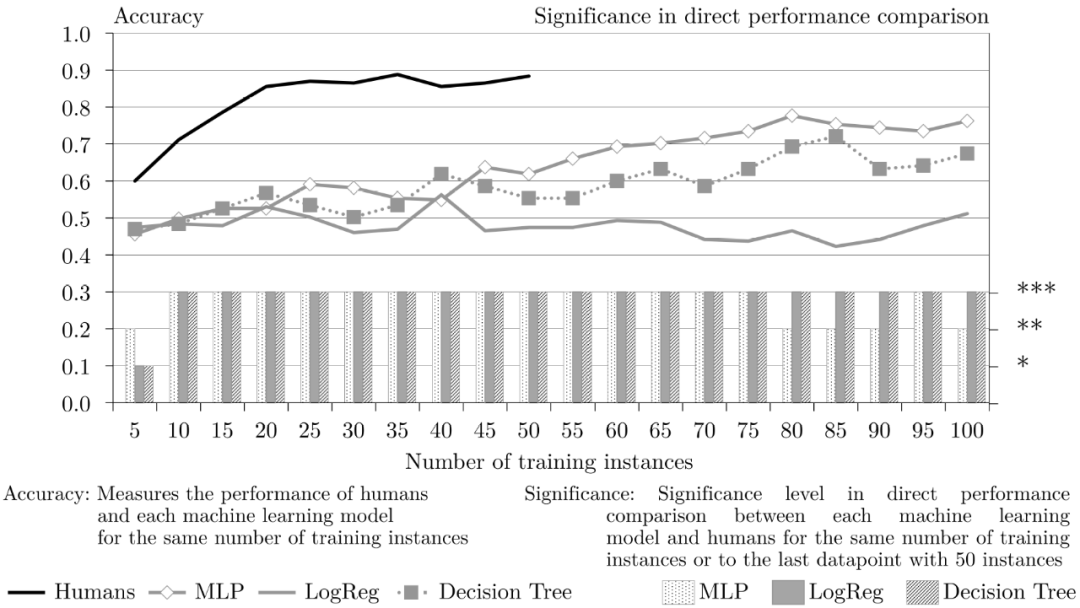
图16. 规则 symmetry 的人类和机器学习性能比较
由该竞赛的结果可以看出,除了对角线规则(Diagonal)中机器学习的性能略强于人类的性能,在其它分类任务中,人类的性能都优于机器学习模型。尤其是人类在看了几个学习样本之后就学到知识,在大部分测试下学习速率都很快。在这个竞赛中,选择的是有监督机器学习方法,因此,随着训练样本的增多,机器学习方法的性能会不断提升。而在训练样本数量很少时,机器学习方法的性能是非常差的。另一方面,机器的性能也受到任务复杂度的影响。在对角线这种规则简单的任务中,机器学习能获得不错的性能,但对于复杂的分类任务,机器学习模型的性能还是比人类差得多。对于人类来说,这四种规则都是很简单的,因此,并不需要有很好的行业或知识背景的特定人类来完成任务。
4 IQ Test 能力对比 [4]
这项工作关于一个 IQ 测试任务,用以比较人类和 Q-learning(一种流行的强化学习算法)的能力。详细的工作分析和结果介绍见文献[4],已经发表在 AGI 2012 中。与上一节的竞赛内容类似,这个 IQ Test 的竞赛解决的也不是实际应用问题,而是完成一个人工生成的逻辑任务。
在一般智力测试中,选择一个合适的环境类(Environment Class)是一个至关重要的问题。例如,可以引入一个无偏的环境类(记为 Λ),其空间和 Agent 具有普遍的描述能力(图灵完备)。这种环境将空间视为一个具有不同(且可变)拓扑结构的行动图。可以使用图灵完备语言引入对象和 Agent 以生成它们的动作。奖励是区间 [-1,1] 中的有理数,由两个特殊的 Agent :Good 和 Evil 产生,它们会在它们访问的单元格中留下奖励。除了奖励的符号外,Good 和 Evil 的行为模式相同(Good 为 +,Evil 为 -)。
空间的生成首先要确定单元格的数目 n_c,由 2 至 9 之间的数字给出,使用几何分布和一元编码(即 prob(n)=2^(-n),并归一化为 1)。同样,行动数 n_a 的定义是在 2 和 n_c 之间均匀分布。单元和动作都用自然数进行索引。有一个特殊的动作 0,它将每个单元与自己连接起来(它总是可以停留在单元)。通过一个动作可以从另一个单元格进入的单元格称为近邻或相邻单元格。单元格之间的连接是通过对每一对单元格和动作使用统一的分布来建立的,它为每一对单元格指定了目的单元格。
图 17 给出了一个随机生成空间的例子。图 17 中空间的序列实例为 201210200,即执行动作 a_2、a_0、a_1、a_2 等。例如,考虑 Good 被放置在 c_5 单元中。由于图案以 "2" 开始,Good 将 (通过 a_2) 移动到 c_1 单元。两个 agent Good 和 Evil 从序列中取出一个动作,并在每一步中执行它。当动作用完后,该序列将重新开始。如果某一行动在某一单元不被允许,则 Agent 不移动。
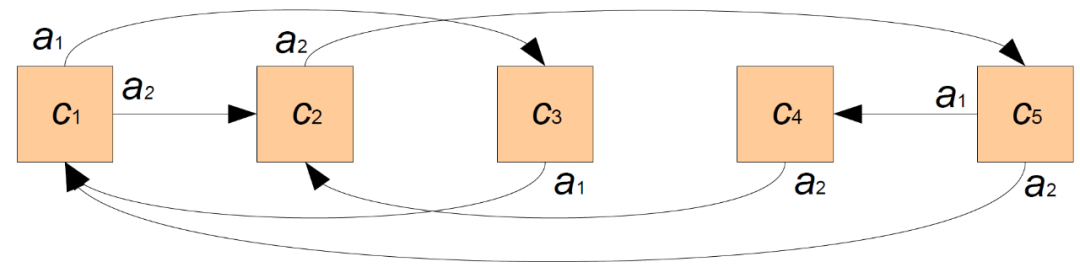
图 17. 一个有 5 个单元格和 3 个动作(a_0, a_1, a_2)的空间,反射动作 a_0 未显示
最初,每个 Agent 被随机(使用统一分布)放置在一个单元中。然后,我们让 Good、Evil 和被评估的 Agent 在一定的步数 m 内进行交互,称之为一个练习 exercise(或情节 episode)。对于一次练习,我们将获得的奖励进行平均,所以给出环境中 Agent 的得分。测试过程是由一连串的练习或情节组成的。我们将使用 7 个环境,每个环境都有 3 到 9 个单元格(n_c)。Good-Evil 模式的大小将与单元格的数量成正比,使用 p_stop= 1/n_c。在每个环境中,我们将允许 10x(n_c-1)个步骤,这样 Agent 就有机会发现环境中的任何模式,也有可能利用一些进一步的步骤来利用这些发现。表 2 给出了测试任务的控制指标。
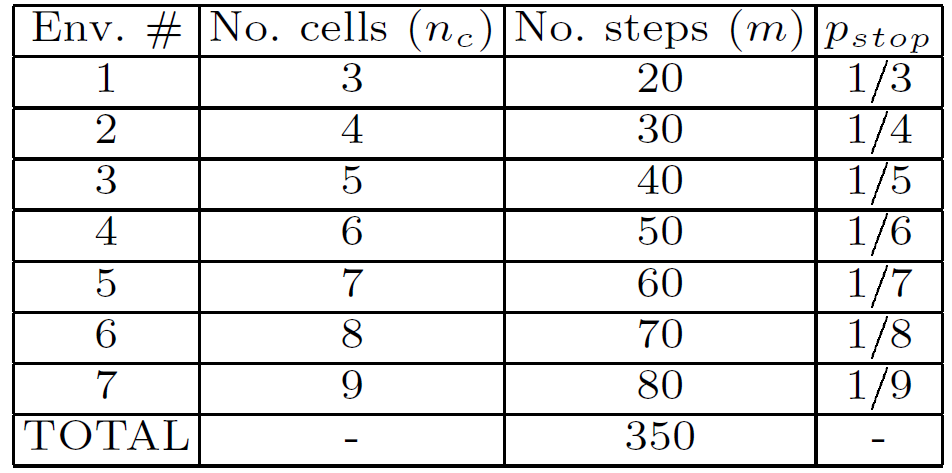
表2. 组成测试的 7 个环境的设置
在该竞赛中,作者选择 Q-Learning 作为 AI 方法,Q-Learning 是一种经典的增强学习方法。而参与竞赛的人类这是从某大学系部抽取的 20 名年龄在 20-50 岁之间的人类(博士生、研究人员和教学人员)。为了使人类完成任务,在设计人类交互界面时考虑到了以下原则:i)用于表示观察结果的标志对受试者来说不应该有隐含的意义,ii)行动和奖励应该容易向受试者解释,以避免额外的认知开销。人类交互界面的示例见图 18,具体的代码可下载 http://users.dsic.upv.es/proy/anynt/human1/test.htm。
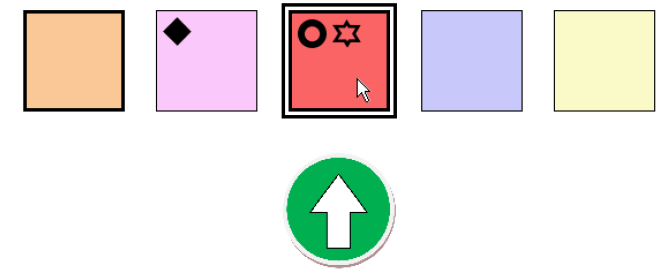
图 18. 人类的交互界面快照。
Agent 刚刚获得了一个积极的奖励,用圆圈与向上的箭头显示。图中还显示 Agent 位于第 3 单元格,Evil 和 Good 分别放在第 2 和第 3 单元格。Agent 可以移动到单元格 1 和单元格 3。单元格 3 被高亮显示,因为鼠标指针在它上面
作者分别对人类和 Q-Learning 完成了 20 个测试(每个测试有 7 个练习),其设置如表 2 所示。关于 Q-learning 结果的平均值如图 19 所示。Q-learning 的总体均值为 0.259,而人类的均值为 0.237,标准差分别为 0.122 和 0.150。
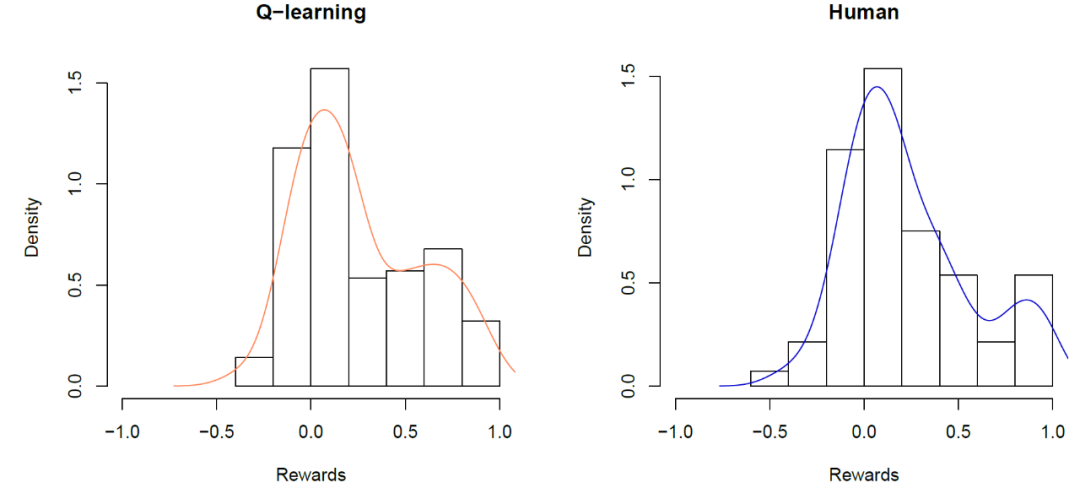
图 19. Q-learning(左)和人类(右)的(20 x7=)140 个练习的直方图,线条显示的是概率密度
为了更详细地看到练习的结果,图 20(左)显示了按练习汇总的结果(每个数字都有一个练习),具体包括每个练习的 Q-learning 和人类完成任务情况的平均值、中位数和散度。观察每个空间大小的曲线图,我们还可以看到,Q-learning 和人类在 7 次练习中的表现并没有显著的不同。图 20(右)为 20x7x2=280 个练习的平均奖励结果。人类比 Q-learning 有更高的离散性。这可能是由于 20 个人类是不同的,他们的能力各有不同,而 Q-learning 在 20 个测试中的每一个算法都是完全相同的,他们的能力是相同的。
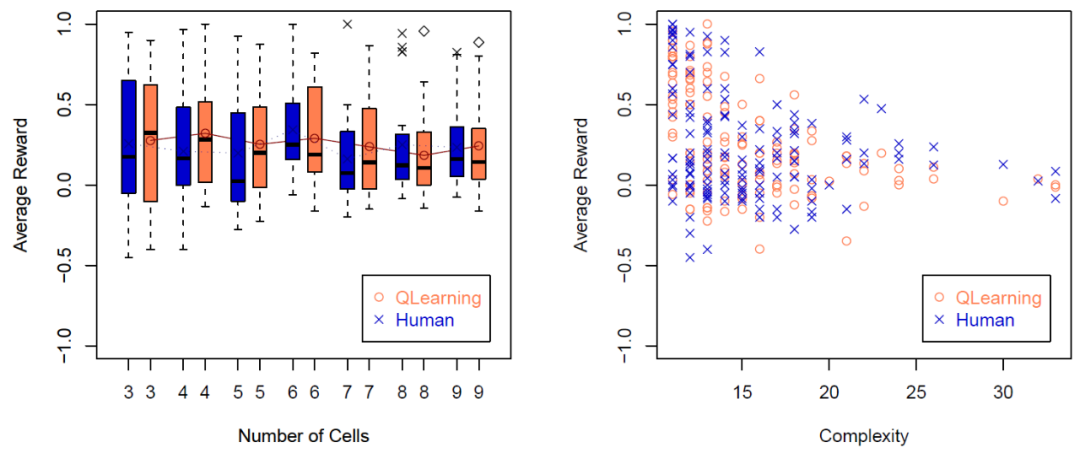 图 20. 左图:不同 Agent 的七次练习的箱形图。
图 20. 左图:不同 Agent 的七次练习的箱形图。中位数在方框中显示为一个黑色的短段。均值由 Q-learning 的连续线和人类的虚线进行连接。右图:20x7x2=280 个练习的平均奖励结果,使用 Kapprox 作为复杂性的衡量标准
由该竞赛的结果可以看出,人类和 AI 在完成 IQ-test 的时性能几乎没有差别。在这项任务中选择的人类都是高校的教职员工,都有较强的知识背景和逻辑分析能力,使用的 Q-learning 就是标准的模型和参数。作者也表示,这样简单的实验条件和设置并不能真正反映出人类和 AI 谁的能力更强,竞赛的结果并不能说明人类获胜,或者 AI 最终获得了胜利。
小结
在这篇文章中,我们讨论了一个非常有趣的问题,即 Human vs AI,在不同的任务中人类的学习能力和机器的学习能力究竟哪个更胜一筹?在每天面对大量的算法、模型、调参、应用的论文,不断关注新突破的各类算法大赛、数据挖掘大赛、图像识别、机器学习预测、风险用户识别竞赛等等的同时,考虑这样一个问题,无疑是发人深思的。
我们列举了四个竞赛,其中两个是针对常见的程序类应用的,包括图像修复 Image Inpaiting 和文本生成,另外两个则是简单的人工生成的逻辑推理问题。从我们给出的实验结果可以看出:
对较为复杂的任务,例如图像修复、复杂逻辑规则推理等,机器的学习能力还远不能与人类相比。
对于一些简单的逻辑问题,例如简单的 IQ Test,利用强化学习的机器模型已经能获得与人类媲美的能力。
在文本生成领域中,依赖于长期的研究积累,拥有大量的标注数据、预训练模型等,并在多个领域中有成功的应用模型,利用超多参数的 GPT3,目前,已经能够在一些场景中获得与人类相匹敌、甚至胜出的文本生成能力。但是,在一些对语言能力要求较高的场景中,例如我们在文中给出的 Booking.com 网站的场景中,AI 生成的 Button 文字仍不如人类生成的精准。人类对于语言的掌控和使用能力,特别是反应特殊意图的启发式、暗语式表达能力,目前,并不是机器能够 “学习” 到的。
对于有监督的机器学习方法,数据数量直接影响了机器 “学习” 的效果。如文中给出的四条规则的分类任务,机器学习模型的性能一般都在 50 个训练样本后实现提升。
当然,正如我们开头所提到的,目前这些竞赛、比对实验都是单一的、小范围的,缺乏系统性、深入性的研究和分析,任何一个结果都不能推导得出 “人类一定胜过机器” 或“机器胜过人类”的结论。而下一步我们如果可以通过尝试构建更通用的、更普遍的人机对抗 (Human vs AI) 测试竞赛,为人与机器能力的评估提供了有价值的信息来源,或许可以引导 AI、ML 向更有利、更有益的方向发展。
本文参考引用的文献:
[1] Hernandez-Orallo, J., 2017b. The measure of all minds: evaluating natural and artificial intelligence. Cambridge University Press.
[2] Bertalmio, M, Sapiro, G., Caselles, V., Ballester, C. Image Inpainting. SIGGRAPH 2000, pages 417-424.
[3] Niklas Kühl,Marc Goutier,Lucas Baier,Clemens Wolff,Dominik Martin, Human vs. supervised machine learning: Who learns patterns faster? https://arxiv.org/abs/2012.03661.
[4] Insa-Cabrera, J., Dowe, D.L., Espana-Cubillo, S., Hernandez-Lloreda, M.V., Hernandez-Orallo, J., 2011. Comparing humans and ai agents, in: International Conference on Artificial General Intelligence, Springer. pp. 122-132.
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











