




作者:陈萍
打开手机进行人脸解锁;VR、AR 技术带来如此虚拟却真实的场景……3D 视觉几乎无所不能,在智能家居、智能安防、汽车电子、工业测量、新零售、智能物流等领域发挥重要作用,堪称赋能产业创新的最大推力。这些技术的背后涉及了 3D 视觉相关内容,那么计算机是如何「看」这个三维世界的?
随着信息技术的快速发展,计算机视觉 3D 技术已经应用到了诸多领域,推动了虚拟现实(VR)、增强现实(AR)等技术的不断进步。3D 视觉问题变得越来越重要,它提供了比 2D 更加丰富的图像信息。
现如今,随处可见 3D 视觉技术带来的便利,工业机器人、工件识别与定位、3D 成像技术、产品虚拟设计、智能制造、自动驾驶、SLAM、无人机、3D 重建、人脸识别等等,都涉及到 3D 视觉相关内容。

3D 视觉应用举例,图源:https://zhuanlan.zhihu.com/p/52049458
总结来说,3D 视觉是计算机视觉与计算机图形学高度交叉的一个重要研究方向。由于三维传感技术的飞速发展和三维几何数据的爆炸式增长,3D 视觉研究突破传统的二维图像空间,实现三维空间的分析、理解和交互。
我们生活在三维空间中,如何智能地感知和探索外部环境一直是个热点课题。2D 视觉技术借助强大的计算机视觉和深度学习算法取得了超越人类认知的成就,而 3D 视觉则因为算法建模和环境依赖等问题,一直处于正在研究的前沿,而三维信息才真正能够反映物体和环境的状态,也更接近人类的感知模式。
随着技术的不断进步,三维视觉领域也取得了快速进步,例如 3D+AI 识别功能,扫描人脸三维结构完成手机解锁;自动驾驶领域通过分析 3D 人脸信息,判断司机驾驶时的情绪状态;SLAM 通过重建周边环境,完成建图与感知;AR 领域通过三维重建技术完成目标的重现等。那么如此实用的技术,是怎样实现的呢?
在深入了解之前,让我们先来了解一下 3D 视觉技术的一些基础知识。
3D 图像介绍
在进行 3D 图像介绍之前,首先简单回顾一下 2D 图像。我们日常生活中所见的图像可以称为物理图像,这种图像不能直接被计算机识别,需要转换成数字格式,即数字图像。数字图像是二维图像有限数字数值像素的表示。由数组或矩阵表示,其光照位置和强度都是离散的。其有两种存储方式:位图存储和矢量存储,常见的存储格式包括 PNG、GIF、JPEG、BMP 等。

二值图像示例,图源:https://blog.csdn.net/gzq0723/article/details/82185832
2D 图像可分为二值图像、彩色图像等。其中二值图像中每个像素可以由 0(黑) 到 255(白) 的亮度值表示。0-255 之间表示不同的灰度级。而彩色图像是由三种不同颜色的灰度图像组合而成,一个为红色分量(R),一个为绿色分量(G),一个为蓝色分量(B)。
 图像彩色显示法,RGB 图像三个分量,图源:https://blog.csdn.net/Hello_Chan/article/details/89094790
图像彩色显示法,RGB 图像三个分量,图源:https://blog.csdn.net/Hello_Chan/article/details/89094790与二维图像类似,三维图像是在二维彩色图像的基础上又多了一个维度,即深度(Depth,D),可用一个很直观的公式表示为:三维图像 = 普通的 RGB 三通道彩色图像 + Depth Map。
RGB-D
RGB-D 是广泛使用的 3D 格式,其图像每个像素都有四个属性:即红(R)、绿(G)、蓝(B)和深度(D)。
深度图是三维图像特有的,是指存储每个像素所用的位数,也用于度量图像的色彩分辨率。确定彩色图像每个像素可能有的颜色数,或者确定灰度图像每个像素可能有的灰度级数。它决定了彩色图像中可出现的最多颜色数,或灰度图像中的最大灰度等级。其数值是规整的,适合直接用于现存的图像处理框架。
关于深度图的解释,例如,一幅彩色图像的每个像素用 R、G、B 三个分量表示,若每个分量用 8 位,那么一个像素共用 24 位表示,那么像素的深度为 24,则每个像素可以是 16777216(224) 种颜色中的一种。因此,可以把像素深度理解成是图像深度。表示一个像素的位数越多,它能表达的颜色数目就越多,而它的深度就越深。
 RGB-D 图像格式,图源:https://www.sohu.com/a/249567571_114877
RGB-D 图像格式,图源:https://www.sohu.com/a/249567571_114877在一般的基于像素的图像中,我们可以通过(x,y)坐标定位任何像素,分别获得三种颜色属性(R,G,B)。而在 RGB-D 图像中,每个(x,y)坐标将对应于四个属性(深度 D,R,G,B)。
点云
我们在做 3D 视觉的时候,处理的主要是点云,点云就是一些点的集合。相对于图像,点云有其不可替代的优势——深度,也就是说三维点云直接提供了三维空间的数据,而图像则需要通过透视几何来反推三维数据。
何为点云?其实点云是某个坐标系下的点的数据集。点包含了丰富的信息,包括三维坐标 X,Y,Z、颜色、分类值、强度值、时间等等。点云在组成特点上分为两种,一种是有序点云,一种是无序点云。
 点云示例,图源:https://www.jianshu.com/p/ffedad5e8e30
点云示例,图源:https://www.jianshu.com/p/ffedad5e8e30点云的获取:点云不是通过普通的相机拍摄得到的,一般是通过三维成像传感器获得,比如双目相机、三维扫描仪、RGB-D 相机等。目前主流的 RGB-D 相机有微软的 Kinect 系列、Intel 的 realsense 系列、structure sensor(需结合 iPad 使用)等。点云可通过扫描的 RGB-D 图像,以及扫描相机的内在参数创建点云,方法是通过相机校准,使用相机内在参数计算真实世界的点(x,y)。因此,RGB-D 图像是网格对齐的图像,而点云则是更稀疏的结构。此外,获得点云的较好方法还包括 LiDAR 激光探测与测量,主要通过星载、机载和地面三种方式获取。
点云的内容:根据激光测量原理得到的点云,包括三维坐标(XYZ)和激光反射强度(Intensity),强度信息与目标的表面材质、粗糙度、入射角方向以及仪器的发射能量、激光波长有关。根据摄影测量原理得到的点云,包括三维坐标(XYZ)和颜色信息(RGB)。结合激光测量和摄影测量原理得到点云,包括三维坐标(XYZ)、激光反射强度(Intensity)和颜色信息(RGB)。
点云的属性:空间分辨率、点位精度、表面法向量等。
虽然 RGB-D 相机应用广泛,但会受到很多硬件的限制,目前深度相机输出的深度图存在很多问题,比如对于光滑物体表面反射、透明物体、半透明物体、深色物体等都会造成深度图缺失。而且很多深度相机是大片的深度值缺失,后续还需要进一步的深度图补全操作。
 图源:https://www.cnblogs.com/CV-life/p/10105480.html
图源:https://www.cnblogs.com/CV-life/p/10105480.html上图为拍摄的室外一个街道的点云图,如果仔细观察,能看清建筑物、树木的轮廓等。就上图而言,点云的优点可以归为以下几点:首先,点云可以表达物体的空间轮廓和具体位置,我们能看到街道、房屋的形状,物体距离摄像机的距离也是可知的;其次,点云本身和视角无关,可以任意旋转,从不同角度和方向观察一个点云,而且不同的点云只要在同一个坐标系下就可以直接融合。
接下来,放大点云,如下图所示,如果将点云放大,最后看到的就是一个个离散的点。也就是空间中成千上万的点组成了一个点的集合,这个点集合构成了上面的街道房屋等。
 点云放大图,图源:https://www.cnblogs.com/CV-life/p/10105480.html
点云放大图,图源:https://www.cnblogs.com/CV-life/p/10105480.html从放大的点云图侧面反映了点云的缺点,可归结为以下几点:三维点云比图像多了一个维度,即深度;点云是不规则分布的,相比于图像式的规整网格更难处理;点云缺少了图像中的纹理,而是一个个孤立的点,会丢失很多信息。除此以外,点云是分布在空间中(XYZ 点)非结构化数据(无网格);在图像中,像素的数量是一个给定的常数,取决于相机。然而,点云的数量可能会有很大的变化,取决于各种传感器;点云的分辨率和离相机的距离有关。不能近距离的观察,只能在一个很远的视角才能观察整体。
下面来看一下点云结果对比,原始的 RGB-D 生成的点云结果如下:
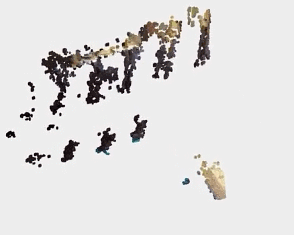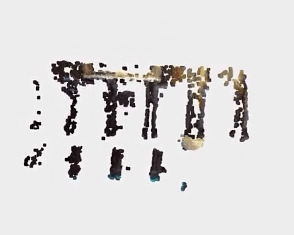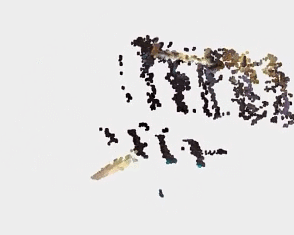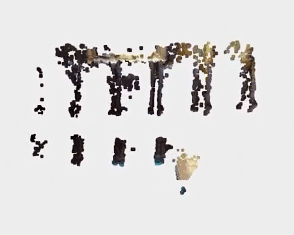 图源:https://zhuanlan.zhihu.com/p/42084058
图源:https://zhuanlan.zhihu.com/p/42084058下面动图显示了经过深度图补全后生成的点云结果如下:
 图源:https://zhuanlan.zhihu.com/p/42084058
图源:https://zhuanlan.zhihu.com/p/42084058点云的数据存储格式
点云存储文件格式有很多。一些文件格式致力于标准化与通用性,而今被多个相关软件或软件库所支持,也被大多数业内人士所认同和使用。点云目前的主要存储格式包括:pts、LAS、PCD、.xyz 和. pcap 等。选择合适的通用格式可以更好地与其它工具乃至其它组织对接,进而提高工作效率。下面简单列举一下点云的数据存储格式。
pts 点云文件格式是最简便的点云格式,直接按 XYZ 顺序存储点云数据, 可以是整型或者浮点型。如下图是截取的塑像点云的一部分。示例如下:
 塑像 pts 格式点云截图,图源:https://blog.csdn.net/ArhatShaw/article/details/70889353
塑像 pts 格式点云截图,图源:https://blog.csdn.net/ArhatShaw/article/details/70889353LAS 是激光雷达数据(LiDAR),存储格式比 pts 复杂,旨在提供一种开放的格式标准,允许不同的硬件和软件提供商输出可互操作的统一格式。现在 LAS 格式文件已成为 LiDAR 数据的工业标准格式。示例如下:

LAS 格式点云截图,其中 C:class(所属类),F:flight(航线号),T:time(GPS 时间),I:intensity(回波强度),R:return(第几次回波),N:number of return(回波次数),A:scan angle(扫描角),RGB:red green blue(RGB 颜色值)。图源:https://www.cnblogs.com/chenbokai/p/6010143.html
PCD 存储格式,现有的文件结构因本身组成的原因不支持由 PCL 库(后文会进行介绍)引进 n 维点类型机制处理过程中的某些扩展,而 PCD 文件格式能够很好地补足这一点。PCD 格式具有文件头,用于描绘点云的整体信息:定义数字的可读头、尺寸、点云的维数和数据类型;一种数据段,可以是 ASCII 码或二进制码。数据本体部分由点的笛卡尔坐标构成,文本模式下以空格做分隔符。
PCD 存储格式是 PCL 库官方指定格式,典型的为点云量身定制的格式。优点是支持 n 维点类型扩展机制,能够更好地发挥 PCL 库的点云处理性能。文件格式有文本和二进制两种格式。示例如下:
 图源:https://cloud.tencent.com/developer/article/1475778
图源:https://cloud.tencent.com/developer/article/1475778.xyz 一种文本格式,前面 3 个数字表示点坐标,后面 3 个数字是点的法向量,数字间以空格分隔。示例如下:

.pcap 是一种通用的数据流格式,现在流行的 Velodyne 公司出品的激光雷达默认采集数据文件格式。它是一种二进制文件。
数据构成结构如下:
整体一个全局头部 (GlobalHeader),然后分成若干个包(Packet),每个包又包含头部(Header)和数据(Data)部分。
相应基础算法库对不同格式的支持
点云的数据量庞大,需要专门的数据存储库进行显示和保存。例如,一张 640 x 480 尺寸的深度图就可以转换为大约三十万个空间点的点云,大的点云可达百万甚至千万以上,这时专门用来进行点云的读写、处理等各种操作数据存储库就显得非常重要。
PCL(Point Cloud Library)库支持跨平台存储,可以在 Windows、Linux、macOS、iOS、Android 上部署。可应用于计算资源有限或者内存有限的应用场景,是一个大型跨平台开源 C++ 编程库,它实现了大量点云相关的通用算法和高效数据结构,其基于以下第三方库:Boost、Eigen、FLANN、VTK、CUDA、OpenNI、Qhull,实现点云相关的获取、滤波、分割、配准、检索、特征提取、识别、追踪、曲面重建、可视化等操作,非常方便移动端开发。

此处的 common 指的是点云数据的类型,包括 XYZ、XYZC、XYZN、XYZG 等很多类型点云。可以看出,低层次的点云处理主要包括滤波(filters)、关键点(keypoints)、边缘检测。点云的中层次处理则是特征描述(feature)、分割(segmention)与分类。高层次处理包括配准(registration)、识别(recognition)。
除了 PCL 库以外,VCG 库(Visulization and Computer Graphics Libary)是专门为处理三角网格而设计的,该库很大,且提供了许多先进的处理网格的功能,以及比较少的点云处理功能。
CGAL(Computational Geometry Algorithms Library)计算几何算法库,设计目标是以 C++ 库的形式,提供方便、高效、可靠的几何算法,其实现了很多处理点云以及处理网格的算法。
Open3D 是一个可以支持 3D 数据处理软件快速开发的开源库。支持快速开发处理 3D 数据的软件。Open3D 前端在 C++ 和 Python 中公开了一组精心选择的数据结构和算法。后端经过高度优化,并设置为并行化。Open3D 是从一开始就开发出来的,带有很少的、经过仔细考虑的依赖项。它可以在不同的平台上设置,并且可以从源代码进行最小的编译。代码干净,样式一致,并通过清晰的代码审查机制进行维护。在点云、网格、rgbd 数据上都有支持。
本文是针对 3D 视觉的总结性文章,介绍了几个比较重要的知识点,希望可以在一定程度上帮助大家更深刻地理解 3D 视觉。在接下来的文章中,我们将继续介绍 3D 视觉领域算法的实现。
参考链接:
https://zhuanlan.zhihu.com/p/42772630
https://www.cnblogs.com/ostin/p/9237544.html
https://www.cnblogs.com/CV-life/p/10105480.html
https://www.cnblogs.com/chenbokai/p/6010143.html
https://blog.csdn.net/xinguihu/article/details/78922005
https://cloud.tencent.com/developer/article/1475778
https://www.jianshu.com/p/ffedad5e8e30
https://zhuanlan.zhihu.com/p/42084058
NeurIPS 2020线上分享:面向鲁棒深度学习的对抗分布式训练
论文:《Adversarial Distributional Training for Robust Deep Learning》。
本篇论文中,研究者提出了一种名为对抗分布式训练(adversarial distributional training, ADT)的新型框架。11月26日,清华大学计算机系博士生董胤蓬,为大家详细解读此前沿研究。




“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











