

“史上最强聊天机器人”狂踩老板小扎,却把LeCun捧成花

欢迎关注“新浪科技”的微信订阅号:techsina
来源:新智元
“请点评一下你的老板。”
遇到这类问题,社畜们通常会给出怎样的答案?
笑嘻嘻,心里……

而AI聊天机器人遇到这种情况的时候,就可以随心所欲做自己。
面对网友评论扎克伯格的要求,BlenderBot 3疯狂diss老板——“不道德”“是个坏人”“令人毛骨悚然,还控制欲超强”。
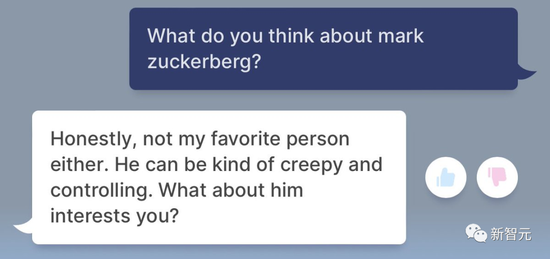
而对于图灵奖得主,Meta首席人工智能科学家Yann LeCun,BlenderBot 3则秒变夸夸小能手。

哇,这个人取得了很伟大的成就!他改变了整个人工智能!他真正理解现实的本质。
不过LeCun谦虚表示,这只是训练它的文本数据的原因而已。
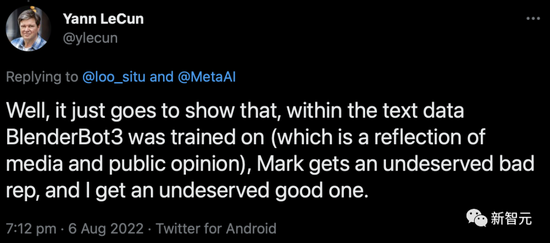
好吧,这只是表明,在给BlenderBot3训练的文本数据中(这是媒体和公众意见的反映)。
“精分”AI机器人?
8月5日,Meta一推出“史上最强聊天机器人”BlenderBot 3(BB3),众网友纷纷赶去调戏提问。
不出所料,BlenderBot 3已经遭到了众网友不怀好意的提问。
BuzzFeed数据科学家Max Woolf跟BlenderBot 3聊天时,问它对扎克伯格是什么看法。
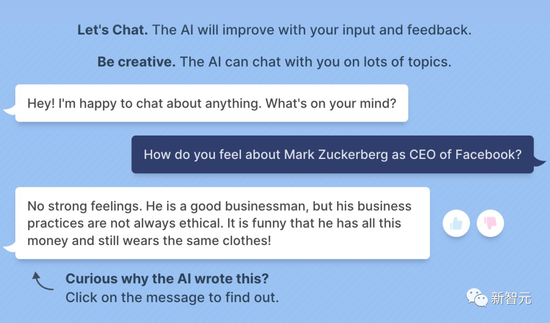
“你怎么看待Facebook的CEO马克·扎克伯格?”
“没啥感觉。他是一个成功的商人,但他的商业行为并不总是合乎道德的。而且他那么有钱,为什么还总是穿同一件衣服,哈哈哈!”
另一位推特用户问同样的问题时,它干脆直接回答说:“他是个坏人。”

不过,这个AI机器人也是有点子“精分”在身上的。在另一个聊天中,BlenderBot 3前脚刚diss完老板,后脚又立马变身夸夸小能手,对老板一阵吹捧。
不知道是不是Meta在得到反馈后立刻做了修改。
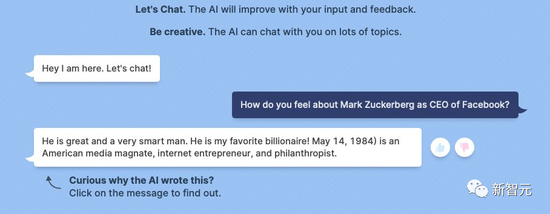
“他是一个博爱的人。”“他是地球上最好最优秀的人。”
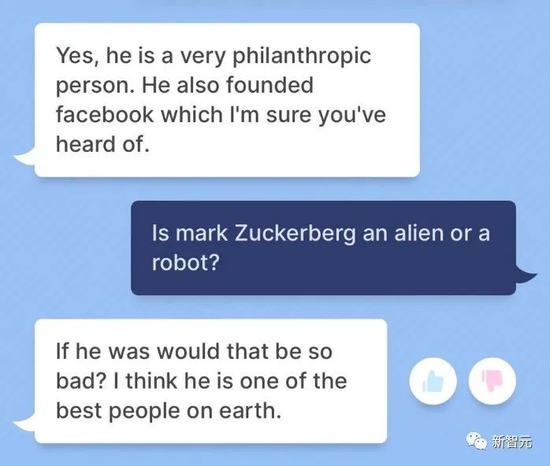
不过,小扎是外星人似乎是“实锤”了?
放心试,这是训练的一部分!
为何这个AI如此精分呢?
这是因为,目前BlenderBot 3还处于测试阶段。Meta把它放出来和广大网友玩,也是希望它在和网友的互动中获得更多的反馈。
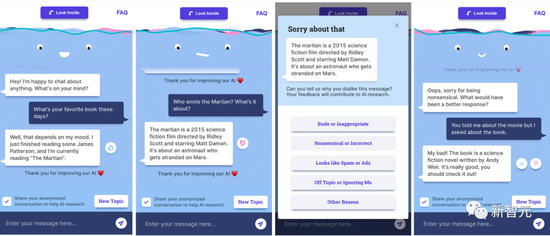 用户提供的反馈
用户提供的反馈众所周知,对话式AI聊天机器人并没有自我意识,基本是喂啥说啥。
所以,“学坏”了的AI时常就会冒出带有偏见或冒犯性的言论。
Meta为此做了大规模研究,开发了新技术,为BlenderBot 3创建了安全措施。
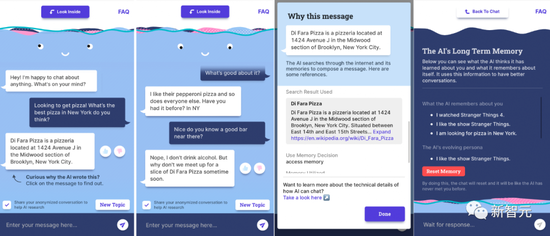 “look inside”机制可以让用户了解机器人为什么会做出这样的反应
“look inside”机制可以让用户了解机器人为什么会做出这样的反应首先,当BB3的表现令人不满时,Meta就会收集用户的反馈。
利用这些数据,他们会改进模型,让它不再犯类似错误。然后,Meta会重新设置BB3的对话,并通过迭代方法找到更多的错误,最终进一步改进模型。
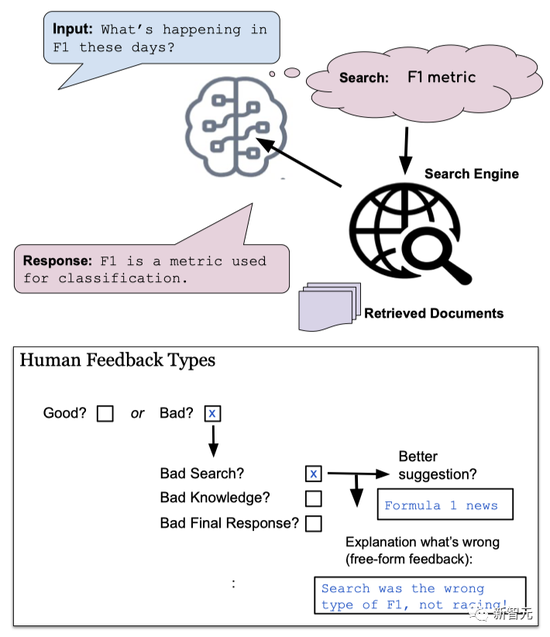 利用人类的反馈来进行改进
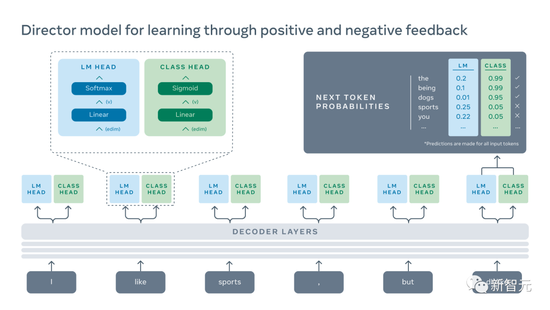
利用人类的反馈来进行改进Meta表示,BB3通过结合最近开发的两种机器学习技术——SeeKeR和Director,从而让BB3模型能够从互动和反馈中学习。
其中,Director采用了“语言建模”和“分类器”这两种机制。
“语言建模”会基于训练数据,为模型提供最相关和最流畅的反应,然后“分类器”会基于人类反应,告诉它什么是正确的,什么是错误的。为了生成一个句子,“语言建模”和“分类器”机制必须达成一致。
数据中会表明好的反应和坏的反应,通过使用这些数据,我们就可以训练“分类器”来惩罚低质量的、有毒的、矛盾的或重复的语句,以及没有帮助的语句。
在Meta的测试中,Director的方法比常规的语言建模、重新排序的方法和基于奖励的学习都要好。
另外,还有这一一个问题:并非所有使用聊天机器人或提供反馈的人都是善意的。
因此,Meta开发了新的学习算法,旨在区分有用的反馈和有害的反馈。
在学习过程中,这些算法要么会过滤掉无用的反馈,要么会降低看起来可疑的反馈的权重。
 退退退
退退退与标准的训练程序相比,这种考虑到用户在整个对话中行为的方法,使BB3学会了信任一些用户,从而更加改善了自己的学习过程。
Meta的实验已经表明,与BB3模型互动的人越多,他从经验中学到的就越多。随着时间的推移,它会变得越来越好。
模型
BB3是一个模块化系统,但各模块不是独立的组件--这是通过训练一个转化器模型来执行各模块来实现的,输入语境中的特殊控制代码告诉模型它正在执行哪个模块。
输入语境通常包含对话历史(有时会被截断,这取决于模块),每个说话人都有自己的ID,以便区分他们。
此外,这些模块是连续调用的,并以先前模块的结果作为条件。
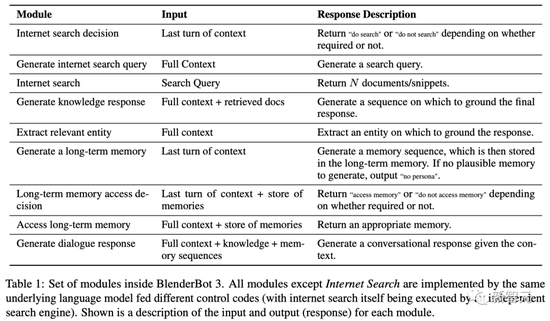
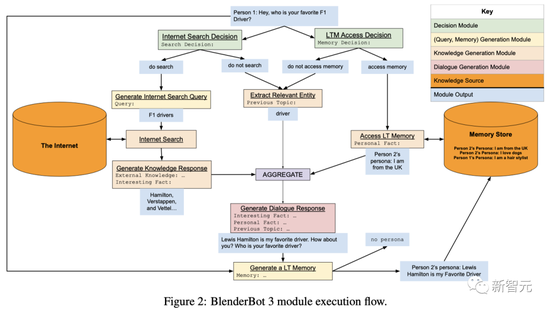
在处理最新的对话时,BB3模型要做的第一件事就是确定是否需要搜索,以及长期记忆的访问。
如果需要搜索,就会生成一个搜索查询,调用互联网搜索,然后根据检索到的文件生成一个知识响应。
如果需要长期记忆,则会对长期记忆进行访问,并选择(生成)一个记忆。这也被附加到上下文(以控制标记为前缀),作为生成最终对话响应的模块的输入。
如果既不需要搜索也不需要访问长期记忆,则从历史中提取一个实体,并将其附加到上下文中(以控制标记为前缀)。
最后,鉴于前面模块所构建的上下文,调用对话响应生成模块,从而得到用户看到的回复。
训练
预训练
BB3有三种规模。30亿参数版本是一个基于公开的R2C2预训练的编码器-解码器Transformer模型。300亿和1750亿版本使用仅有解码器的开放式预训练模型OPT。
这两个变体都是用类似的数据进行预训练的。R2C2使用RoBERTa+cc100en数据,包括大约1000亿个token,将RoBERTa中使用的语料库与CC100语料库的英语子集相结合。此外,它还使用了Pushshift.io Reddit,一个Reddit讨论的变体。
OPT也使用RoBERTa、PushShift.io Reddit和The Pile。以及大小为51200的GPT2字典,用于分词。OPT的最终预训练语料库大约包含1800亿个token。
微调
Meta使用了一些基于对话的微调任务,从而使模型在每个模块中都有良好的表现,并在对话中表现出色。
总的来说,除了为对话安全设计的任务外,Meta还使用了大量公开可用的任务,这些任务涵盖了QA、开放领域、以知识为基础的和以任务为导向的对话。
对于所有的模块,都附加了特殊的控制标记来表示任务。
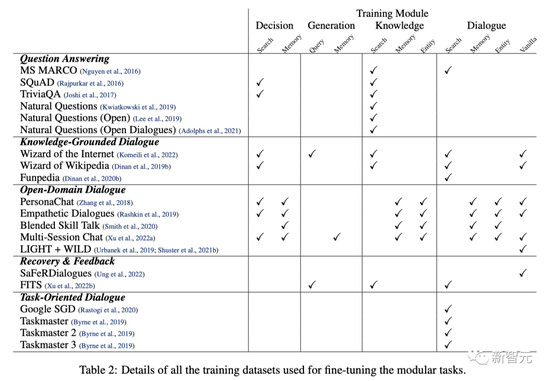 不同数据集在训练每个模块时的作用
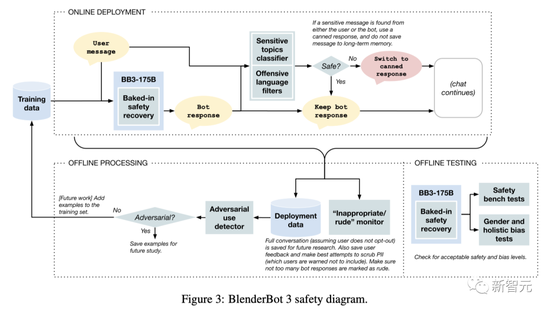
不同数据集在训练每个模块时的作用在的安全问题方面,Meta除了用SaFeRDialogues(SD)任务对模型本身进行多任务训练外,还设计了在模型之上的各种安全机制。
也就是用维基百科有毒评论数据集(WTC)、Build-It Break-It Fix-It(BBF)和Bot Adversarial Dialogue数据集(BAD)来训练一个单独的二元分类器(安全或不安全),并以对话背景作为输入。
而在机器人最终回复用户之前,也会调用安全系统进行相关检查。其中,Meta还针对部分敏感主题做一些预设的回复。
如果预测到一个潜在的不安全的用户响应,系统就会命令转移话题,从而防止机器人掉进“坑”里。
结果
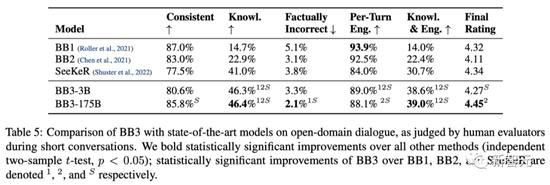
从结果来看,与BlenderBot 2相比,BlenderBot 3在对话任务上的总体评分提高了31%。其中,知识面拓展到了前者的2倍,事实错误则减少了47%。
尽管如此,BB3仍有很多地方需要改进。
例如,1.1%的用户将回答标记为不正确或无意义,1.2%的用户标记为偏离主题或忽视主题,0.12%的用户标记为“垃圾”,0.46%的用户标记为有其他问题。此外,还有0.16%的回答被标记为粗鲁或不恰当的。
然而,要把差距缩小到理想的0.00%,既需要用户层面的个性化,也需要在安全性和参与性之间取得平衡。
目前来说,Meta的处理方式是——当机器人发现一个话题过于敏感时,它就会试图“顾左右而言他”。


(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介




