

国内百位AI大牛论文严重抄袭,学术造假为何屡禁不止?
 图片来源视觉中国
图片来源视觉中国欢迎关注“新浪科技”的微信订阅号:techsina
文/林志佳
来源:钛媒体(ID:taimeiti)
一起近百位国内AI大牛参与的论文被爆出抄袭,让中国人工智能(AI)学术圈顿时处于风口浪尖。
钛媒体App 4月14日消息,谷歌大脑(Google Brain)团队著名科学家Nicholas Carlini 近日发表的一篇博客中指控:由北京智源人工智能研究院团队牵头,刊登在论文预印网站Arxiv的一篇中国学术综述论文《关于“大模型”的路线图》(“A Roadmap for Big Model”)一文涉嫌严重抄袭。
Nicholas Carlini在博客文章《机器学习研究中的一个抄袭案例》中则详细列举了上述中国团队论文存在大段抄袭其他论文的嫌疑,证据是大规模的文本重叠,疑似被剽窃的论文也包括他更早发布的《去重训练数据使语言模型更好》(Deduplicating Training Data Makes Language Models Better),部分内容一模一样。讽刺的是,后者这篇被抄袭的论文,研究的主题正是数据去重和查重。
据悉,指控抄袭的这篇国内学术论文发表于今年3月26日,由国内外多家高校和企业共同完成,长达200多页,本论文有多达100名作者,分别来自于清华大学、北京大学、中国人民大学、上海交通大学、哈尔滨工业大学、哥伦比亚大学、蒙特利尔大学等国内外高校,以及字节跳动、华为、京东、腾讯等企业以及中科院、微软亚洲研究院和北京智源AI研究院等机构。
针对此事,钛媒体App获悉,该论文组织方“北京智源人工智能研究院”(以下简称“智源研究院”)于4月13日晚发表了一份1000字左右的《关于“A Roadmap for Big Model”综述报告问题的致歉信》。
智源研究院在致歉信中称,经过逐项核查与差重,确认共计五篇文章章节、613词的内容与其他论文重复,应属抄袭。团队决定立即从报告中删除相应内容,报告修订版今天将提交arXiv进行更新。目前已通知所有文章的作者对所有内容进行全面审查,后续经严格审核后再发布新版本。
“智源作为该报告的组织者,理应对各篇文章的所有内容进行严格审核,出现这样的问题难辞其咎。对此我们深感自责,特别感谢学术界和媒体的朋友们帮助我们发现问题。我们将深刻吸取教训,整改科研管理和论文发表流程,希望各界朋友监督我们工作。”智源研究院方面表示。
智源研究院方面表示,下一步,团队将以此为戒,即日启动邀请第三方专家对报告进行独立审查,根据正式调查结果对相关责任人作出问责处理。并进一步完善制度管理,通过更加严格的审核机制和更加明确的惩戒措施,对研究院内部以及支持的科研人员加强学风教育,防范同类事件的再次发生。
 致歉信内容截图
致歉信内容截图16篇文章部分存在抄袭,
中国大模型论文引起学术争议
据智源研究院介绍,被指控的学术综述论文《关于“大模型”的路线图》报告是一篇大模型领域的综述,希望尽可能涵盖国内外该领域的所有重要文献,由智源研究院牵头,负责框架设计和稿件汇总,并邀请国内外100位科研人员分别撰写了16篇独立的专题文章,每篇文章分别邀请了一组作者撰写并单独署名,共257页。报告发布后,根据反馈持续进行修改完善,到4月2日在arXiv网站上已经更新到第三版。
本论文由悟道大模型研究项目负责人、清华大学计算机系教授、智源研究院学术副院长唐杰牵头,从大模型基础资源、大模型构建、大模型关键技术与大模型应用探索4个层面出发,详细对15个具体领域的16个相关主题进行全面介绍和探讨。
据悉,论文研究主体“大模型”,为目前世界AI研究领域最热门的话题之一。AI 技术发展到今天,GPT和BERT等参数量巨大的模型被人们开发出来,他们在计算机视觉和自然语言处理等领域取得了前所未有的成就。同时,因为大模型参数量巨大,最近学术界开始将它们当作一类特别的 AI 模型进行研究。
早在2021年6月1日的北京智源大会上,唐杰发布了“悟道 2.0”人工智能巨模型。它以1.75万亿参数量,打破了此前谷歌Switch Transformer预训练模型创造的1.6万亿参数记录,成为了全球最大的预训练模型,也是中国第一个超大规模预训练模型,取得了多项国际领先的AI技术突破和多个世界第一。
唐杰在会上称,“悟道”由智源研究院牵头,汇聚清华、北大、人大、中科院等高校院所以及诸多企业的100余位AI领域专家。
 清华大学计算机系教授、北京智源人工智能研究院副院长 唐杰(来源:智源大会官网)
清华大学计算机系教授、北京智源人工智能研究院副院长 唐杰(来源:智源大会官网)今年3月31日,北京智源社区撰文介绍了最新的《关于“大模型”的路线图》论文:
“随着以深度学习为代表的AI技术的快速发展,智能模型的训练应用模式逐渐由‘大炼模型’向‘炼大模型’转变。大模型研究在近年来发展迅速,模型的参数量以惊人的速度扩展。北京智源人工智能研究院最近发布的《关于“大模型”的路线图》由悟道大模型研究项目负责人,智源学术副院长,清华大学计算机系教授唐杰牵头,从大模型基础资源、大模型构建、大模型关键技术与大模型应用探索4个层面出发,对15个具体领域的16个相关主题进行全面介绍和探讨。非常值得关注。”
不过,谷歌大脑团队著名科学家Nicholas Carlini却在博客指出,上述论文有大量段落涉嫌抄袭,被抄袭的可能至少包括他自己发表的论文在内十余篇文章。
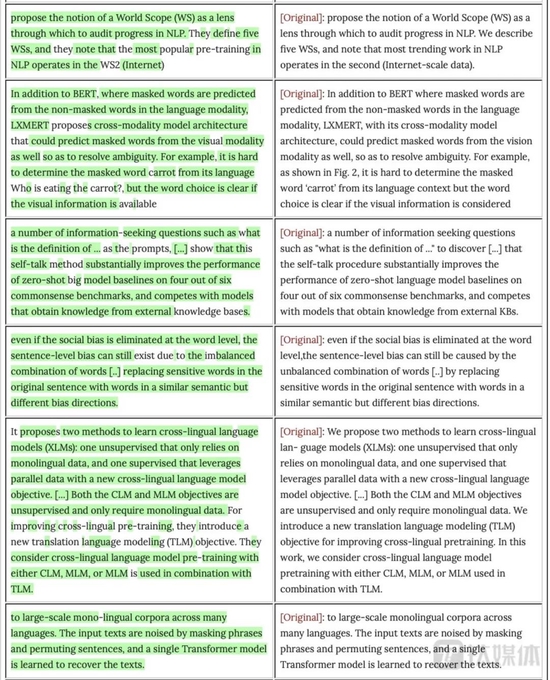 论文抄袭部分段落(图片来源:Nicholas Carlini博客)
论文抄袭部分段落(图片来源:Nicholas Carlini博客)钛媒体查阅arXiv发现,Nicholas Carlini的论文上传时间为去年七月份,而智源研究院领衔的论文则上传时间在今年3月。
根据智源研究院致歉信中的表述,经查重确认,本论文第2篇文章的第3.1节179个词,第8篇文章的第3.1节74个词、第12篇文章的第2.3节55个词、第14篇文章的第2节159个词、第16篇文章的第1节146个词与其他论文重复,应属抄袭。
Nicholas Carlini表示,很可能只有少数作者参与了这种抄袭,一小部分作者的不当行为不应该被用来指责大多数行为良好的作者。
事实上,这篇抄袭的论文之所以得到关注,除了他是中国 AI 学术论文之外,更重要的是,大模型论文作者署名甚至多达100人,其中不乏国内AI业界和学界的知名学者,供职机构更是把中国知名高校和互联网巨头几乎一网打尽。
这其中包括清华大学计算机系教授、人工智能研究院基础研究中心主任朱军,他曾获得科学探索奖、CCF自然科学一等奖、《麻省理工科技评论》“35岁以下科技创新35人”等重要奖项;以及中国人民大学高瓴人工智能学院执行院长,信息学院院长,大数据管理与分析方法研究北京市重点实验室主任文继荣教授等。当然还有牵头的通讯作者、国际计算机学会会士、清华大学计算机系教授唐杰。
目前,这篇被质疑的论文已经被Arxiv网站上备注了该文和Nicholas Carlini的论文有“文本重叠”(text overlap)。
中国正重拳打击论文抄袭等学术不端行为
这一论文抄袭事件,可能会给中国 AI 学术研究热潮造成一定打击。
去年6月,清华大学人工智能研究院等机构联合发布的《人工智能全球2000位最具影响力学者报告》指出,近年来中国的研究热度已经赶超美国。
根据美国斯坦福大学发布《2021年人工智能指数报告》中指出,在期刊论文总数超过美国的若干年后,中国 AI 期刊论文被引量超过美国,拿下了世界第一。而论文引用量在学术研究界是衡量一篇科研文献被其他机构学者认可的数据,上述报告显示,2020年中国研究机构比美国少发了近1400篇会议论文,但被引量相差了一万多次。
滑铁卢大学教授Gautam Kamath表示,对于上述这篇有如此多作者的文章,他很惊讶没有一个作者注意到相似之处并且去改正它。
实际上,自2018年起,由于国外期刊频繁撤回国内学者论文,中国开始加大对论文抄袭、学术不端、存在造假、不当署名等行为的严厉查处力度。
2018年5月,中央印发《关于进一步加强科研诚信建设的若干意见》,并发出通知,要求各地区各部门结合实际认真贯彻落实。
其中重点提到:从事科研活动和参与科技管理服务的各类人员要坚守底线、严格自律。科研人员要恪守科学道德准则,遵守科研活动规范,践行科研诚信要求,不得抄袭、剽窃他人科研成果或者伪造、篡改研究数据、研究结论;不得购买、代写、代投论文,虚构同行评议专家及评议意见;不得违反论文署名规范,擅自标注或虚假标注获得科技计划(专项、基金等)等资助;不得弄虚作假,骗取科技计划(专项、基金等)项目、科研经费以及奖励、荣誉等;不得有其他违背科研诚信要求的行为。
若干意见中强调,科技部要建立学术期刊预警机制,支持相关机构发布国内和国际学术期刊预警名单,并实行动态跟踪、及时调整。将罔顾学术质量、管理混乱、商业利益至上,造成恶劣影响的学术期刊,列入黑名单。
2020年9月22日,教育部、国家发展改革委、财政部发布了《关于加快新时代研究生教育改革发展的意见》,针对学位“注水”问题指出培养单位要抓住课程学习、实习实践、学位论文开题、中期考核、论文评阅和答辩、学位评定等关键环节,细化强化导师、学位论文答辩委员会和学位评定委员会权责。
“对学术不端、学位注水的问题,我们坚持零容忍,发现一起、查处一起,露头就打,坚决确保学位授予的含金量……”教育部方面人士表示。
据科技部公布的教育、医疗机构医学科研诚信案件调查处理结果,自2021年下半年以来,约520起医疗科研学术不端案件遭通报,案件涉240余个教育、医疗机构,超600名医务人员遭惩处。
尽管中国不断严厉查处相关事件,但中国学者的论文造假、抄袭等学术不端行为依然屡禁不止。
根据今年1月27日,科技部指出,最新一批有46起涉嫌论文抄袭、学术不端、存在造假、不当署名等行为。其中,青岛大学被通报共18起,占据此次调查处理结果的近1/3。
更早之前,在2020年新冠疫情期间,国际同行评议的期刊发表的121篇中国作者的相关科研论文中,重复使用了一些相同的图片样本,而且每一篇论文都至少有一幅图像与另一篇论文相同。这些论文由大约50个城市的医院和医学院的研究人员发表。
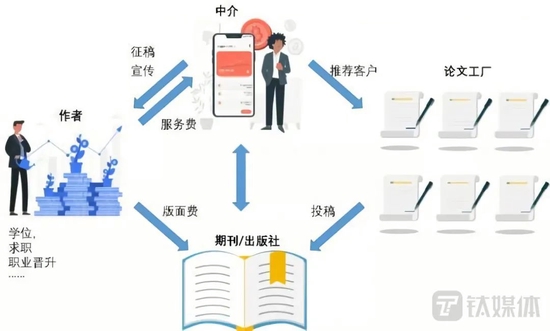 期刊出版社、中介公司、“论文工厂”、以及作者之间形成了一个错综复杂的利益链(来源:知识分子公众号)
期刊出版社、中介公司、“论文工厂”、以及作者之间形成了一个错综复杂的利益链(来源:知识分子公众号)多位学术界业内人士告诉钛媒体App,论文抄袭、学术造假等学术不端事件频出的背后原因,主要是中国教育乃至于整个学术圈的评价体系,拥有隐秘而成熟的利益链,形成了灰色地带“论文工厂”。其中有人生产和贩卖假论文,也有院士、教授、医生、教师、研究人员为了寻求职业晋升与经济回报,不知不觉中推动了这个行业的发展壮大。
因此,中国需要更多的关注和干预措施。
2020年2月,科技部印发《关于破除科技评价中 “唯论文” 不良导向的若干措施(试行)》通知,强调重视分类考核评价、注重评估成果的经济社会价值和影响力等。
2020年7月29日,国家科技部与国家自然科学基金委员会发布的《关于进一步压实国家科技计划(专项、基金等)任务承担单位科研作风学风和科研诚信主体责任的通知》中,明确应科学、理性看待学术论文,注重论文质量和水平,不将论文发表数量、影响因子等与奖励奖金挂钩,不使用国家科技计划(专项、基金等)专项资金奖励论文发表。
不过,“论文造假” 倒逼科研评价体系改革,但到底什么是更好的评价体系,如何将更公平的评估落到实处,可能还需要一个逐步探索的过程。





