

英伟达发布“空气CPU”,Arm架构专为AI而生,性能超x86十倍,与自家GPU更搭
来源:量子位
梦晨 晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
30系显卡买不到?英伟达老黄刚刚又发布一款“空气CPU”。
不过就算你抢不到也没关系,因为这款CPU专门为服务器设计,到2023年才能发布。
刚刚,在英伟达举办的GPU技术大会上(其实会场就是老黄家的厨房),黄仁勋发布了全新ARM架构CPU,也是英伟达首款服务器CPU——Grace。

这款CPU专为处理大量数据的AI任务而生。老黄说,如果服务器用上这款CPU,那么AI性能将超过x86架构CPU的10倍。
去年,老黄就是在这里发布了A100、RTX 30系列GPU。今年,这位皮衣男的头发更长了,也更白了。

除推出首款服务器GPU外,英伟达还要把ARM架构带到笔记本上。
如果用一句话概括这场发布会,那就是老黄想用ARM革x86的命,毕竟英伟达是准备用400亿美元收购ARM的。
PPT级CPU
全新的CPU以女程序员先驱Grace Hopper的名字命名,有趣的是英伟达的GPU是以男性科学家的名字来命名的:图灵、安培……现在英伟达的两条产品线实现了梦幻联动。

RTX 30系显卡是因为买不到而被叫做“空气”,那么Grace CPU被叫做空气的原因是,这款产品实在是“太PPT”了。
正式发布时间在2年后,什么整数浮点运算性能、主频参数统统没有,连制程工艺也语焉不详,如果不出意外,应该是5nm。
英伟达只在发布会上透露,Grace在SPECrate2017_int_base基准测试中超过300分,可以与AMD第二代64核EPYC中的某些CPU相媲美。

再看看这一个月里AMD和Intel发布的服务器GPU那一大串参数,这不就是“空气”吗!
既然什么参数都没有,唯一参数也只和AMD上一代ETPC持平,老黄为何敢拍着胸脯说Grace比其他x86架构强10倍呢?
因为,在数据传输速度这件事上,Grace比AMD和Intel跑得快多了。
这对于AI任务太重要了。英伟达的GPU用于深度学习,而CPU、内存和GPU之间的通信速度往往拖了AI的后腿。
过去,CPU和GPU之间靠PCIe总线进行数据传输,两种不同架构硬件之间的沟通太慢。

而x86架构CPU又不支持英伟达自有的NVLink,所以最好的办法是自己造一个CPU,专门为大量数据的AI任务而生。

Grace和英伟达GPU之间通过NVLink 4进行通信,从GPU到CPU之间的传输速度高达900GB/s,比AMD EPYC 2+NVIDIA A100的搭配快14倍。
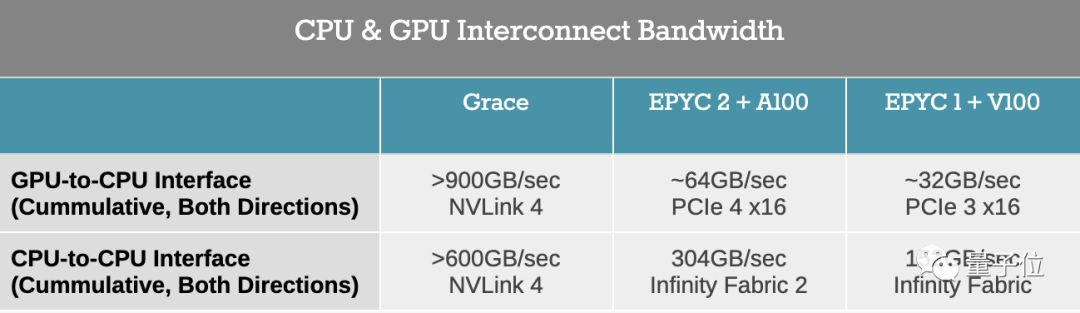 △ Grace与AMD CPU传输速率对比(图片来自AnandTech)
△ Grace与AMD CPU传输速率对比(图片来自AnandTech)另外,Grace也有着最高的内存带宽500GB/s,且支持LPDDR5x ECC内存,能效比其他产品高10倍。
这款CPU我们何时才能见到呢?
现在已经有两个大客户了,其中瑞士国家计算中心正在建造全球最快AI超算算力达20EFLOPS;美国洛斯阿拉莫斯国家实验室也将为其研究人员配备搭载Grace的新AI超算。

至于Grace的一个可能用途,是用来训练下一代超过1万亿参数的NLP模型,GPT-4就靠它了。
ARM笔记本也能有独显
取代x86的野心不仅在服务器端,英伟达还要把ARM带到PC平台上。
但英伟达不是自己制造笔记本CPU,而是与联发科合作。

未来英伟达RTX笔记本显卡将支持ARM架构CPU,将光追和AI技术带到ARM平台上。目前双方已经开发了支持Chromium、Linux两种开源系统的SDK参考平台。
联发科CEO表示,GPU加速将对整个Arm生态系统产生巨大的推动作用。
希望Windows能在ARM软件生态上给力,用上ARM架构的独显游戏本也许不是梦了。
自动驾驶芯片
老黄在发布会上表示,将于2022年投产Orin自动驾驶芯片。
虽然我们到明年才可能看到搭载Orin的汽车,但是这不妨碍英伟达发布下一代自动驾驶芯片Atlan。

Atlan算力达到1000TOPS,是上一代Orin芯片的4倍,为2025年诞生的汽车设计。
英伟达宣布与沃尔沃深化合作,明年沃尔沃将从新款XC90开始搭载Orin系统,并在2025年款车型中搭载最新的Atlan系统。
更多AI落地
Nvidia发布了用于训练大规模Transformer模型的“威震天”——Megatron Triton推理服务器。
Transformer模型的参数规模正以指数级增长,每两个半月翻一倍。Nvidia预计明年将会出现万亿级参数的模型。
以GPT-3为例,使用双路CPU的服务器进行一次128个单词的查询就要超过一分钟。
Megatron Triton通过多GPU、多节点推理,可以在1秒内同时进行16次这样的查询。

会上还发布了药物研发领域的Clara Discovery产品,包括医学影像、基因组分析、量子化学、寻找新化合物等方面。

CuQuantum,用GPU加速量子电路模拟,适用于张量网络求解和状态向量求解。在测试中,将双CPU需要10天完成的任务缩短到2小时。

除此之外,还有多模态实时对话AI平台Jarvis的1.0公测版,能够实现语音识别、语言理解、翻译,以及在合成语音中表现出情绪。

以及开源推荐系统框架Merlin。在测试中实现10-50倍的ETL加速。

Jarvis和Merlin都已可以在NvidiaNGC中下载。
还要打造虚拟世界
Nvidia还宣布夏季推出元宇宙产品Omniverse企业授权许可,用于让团队在虚拟世界中异地实时协作。
元宇宙(Metaverse),1992年由尼尔·斯蒂芬森于在科幻小说《雪崩》中提出,是一个与现实世界相互影响的虚拟世界,就像《头号玩家》中展示的那样。
NVIDIA Omniverse是一个云原生平台,除了视觉模拟外、还进行高精度的材料和物理学模拟并与NVIDIA AI完全集成。
除了娱乐外,Omniverse可用于机器人训练,通过创造工厂的数字重建,在虚拟环境中训练好的机器人AI可以直接部署到真实环境中。

老黄还展示了与宝马公司合作的项目,通过模拟了31家宝马工厂的生产流程,并在数字环境中进行优化,将生产效率提升了30%。

显卡呢?
说了这么多乱七八糟的,老本行显卡呢?
Nvidia公布了8款为下一代笔记本电脑、台式机和服务器推出八款全新安培架构显卡RTX A系列。
A系列为用于图形设计的专业卡,搭载下一代RTX技术。

其中RTX A5000桌面卡提供24G显存。而A2000-A5000的移动版将搭载第三代MAX-Q技术,在不影响笔记本轻薄属性下提供更高性能。
参考链接:
[1]https://nvidianews.nvidia.com/news/nvidia-announces-cpu-for-giant-ai-and-high-performance-computing-workloads
[2]https://www.anandtech.com/show/16610/nvidia-unveils-grace-a-highperformance-arm-server-cpu-for-use-in-ai-systems
[3]https://www.engadget.com/nvidia-mediatek-arm-pcs-gpus-170021586.html

(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介
作者文章
推荐阅读
- 被骗39元后,我发现了AI算命的财富密码
-

- 21世纪的算命先生如何赚钱?他们已经抛弃了兽骨、龟甲、石子、铜钱的传统“老四样”,拿起人工智能的时髦镰刀,收割财富。详细>>
- 大哥特斯拉:造车“三傻”,咱们抱团?
-

- 传统车企大反攻、特斯拉带领造车三兄弟突围,2021年的新能源汽车市场会掀起怎样的浪潮?行业格局又将如何演变?我们从销量入手,试图剖析一二。详细>>
- 在线教育淘汰赛:一起教育的校内流量并非免死金牌
-

- 在线教育的淘汰赛里,校内流量并非一起教育的“免死金牌”。它还有几张牌可打,打好则生,打坏则陨。详细>>
- 电池江湖:日本还比中国先进多少?
-

- 如果这手机、电脑没有了电池,我们的生活可能会出现停顿。详细>>